 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
KaVa: Latent Reasoning via Compressed KV-Cache Distillation
Oct 02, 2025Large Language Models (LLMs) excel at multi-step reasoning problems with explicit chain-of-thought (CoT), but verbose traces incur significant computational costs and memory overhead, and often carry redundant, stylistic artifacts. Latent reasoning has emerged as an efficient alternative that internalizes the thought process, but it suffers from a critical lack of supervision, limiting its effectiveness on complex, natural-language reasoning traces. In this work, we propose KaVa, the first framework that bridges this gap by distilling knowledge directly from a compressed KV-cache of the teacher into a latent-reasoning student via self-distillation, leveraging the representational flexibility of continuous latent tokens to align stepwise KV trajectories. We show that the abstract, unstructured knowledge within compressed KV-cache, which lacks direct token correspondence, can serve as a rich supervisory signal for a latent reasoning student. Empirically, the approach consistently outperforms strong latent baselines, exhibits markedly smaller degradation from equation-only to natural-language traces, and scales to larger backbones while preserving efficiency. These results establish compressed KV-cache distillation as a scalable supervision signal for latent reasoning, combining the accuracy of CoT-trained teachers with the efficiency and deployability of latent inference.
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Nov 27, 2024



Mixture of Experts (MoE) LLMs have recently gained attention for their ability to enhance performance by selectively engaging specialized subnetworks or "experts" for each input. However, deploying MoEs on memory-constrained devices remains challenging, particularly when generating tokens sequentially with a batch size of one, as opposed to typical high-throughput settings involving long sequences or large batches. In this work, we optimize MoE on memory-constrained devices where only a subset of expert weights fit in DRAM. We introduce a novel cache-aware routing strategy that leverages expert reuse during token generation to improve cache locality. We evaluate our approach on language modeling, MMLU, and GSM8K benchmarks and present on-device results demonstrating 2$\times$ speedups on mobile devices, offering a flexible, training-free solution to extend MoE's applicability across real-world applications.
Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design
Oct 24, 2024



The proliferation of large language models (LLMs) has led to the adoption of Mixture-of-Experts (MoE) architectures that dynamically leverage specialized subnetworks for improved efficiency and performance. Despite their benefits, MoE models face significant challenges during inference, including inefficient memory management and suboptimal batching, due to misaligned design choices between the model architecture and the system policies. Furthermore, the conventional approach of training MoEs from scratch is increasingly prohibitive in terms of cost. In this paper, we propose a novel framework Read-ME that transforms pre-trained dense LLMs into smaller MoE models (in contrast to "upcycling" generalist MoEs), avoiding the high costs of ground-up training. Our approach employs activation sparsity to extract experts. To compose experts, we examine the widely-adopted layer-wise router design and show its redundancy, and thus we introduce the pre-gating router decoupled from the MoE backbone that facilitates system-friendly pre-computing and lookahead scheduling, enhancing expert-aware batching and caching. Our codesign therefore addresses critical gaps on both the algorithmic and system fronts, establishing a scalable and efficient alternative for LLM inference in resource-constrained settings. Read-ME outperforms other popular open-source dense models of similar scales, achieving improvements of up to 10.1% on MMLU, and improving mean end-to-end latency up to 6.1%. Codes are available at: https://github.com/VITA-Group/READ-ME.
InterroGate: Learning to Share, Specialize, and Prune Representations for Multi-task Learning
Feb 26, 2024
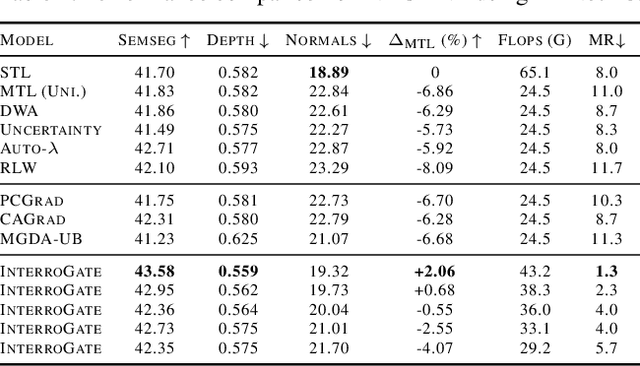

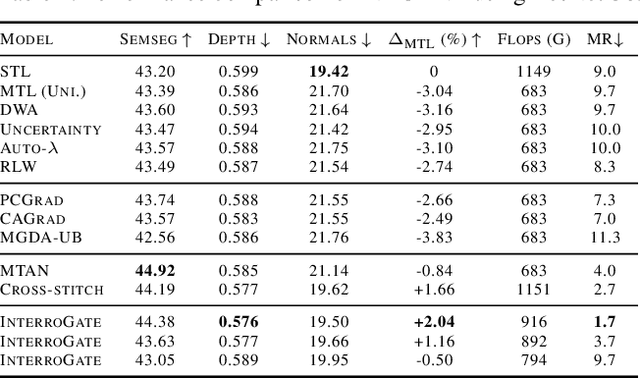
Jointly learning multiple tasks with a unified model can improve accuracy and data efficiency, but it faces the challenge of task interference, where optimizing one task objective may inadvertently compromise the performance of another. A solution to mitigate this issue is to allocate task-specific parameters, free from interference, on top of shared features. However, manually designing such architectures is cumbersome, as practitioners need to balance between the overall performance across all tasks and the higher computational cost induced by the newly added parameters. In this work, we propose \textit{InterroGate}, a novel multi-task learning (MTL) architecture designed to mitigate task interference while optimizing inference computational efficiency. We employ a learnable gating mechanism to automatically balance the shared and task-specific representations while preserving the performance of all tasks. Crucially, the patterns of parameter sharing and specialization dynamically learned during training, become fixed at inference, resulting in a static, optimized MTL architecture. Through extensive empirical evaluations, we demonstrate SoTA results on three MTL benchmarks using convolutional as well as transformer-based backbones on CelebA, NYUD-v2, and PASCAL-Context.
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Feb 26, 2024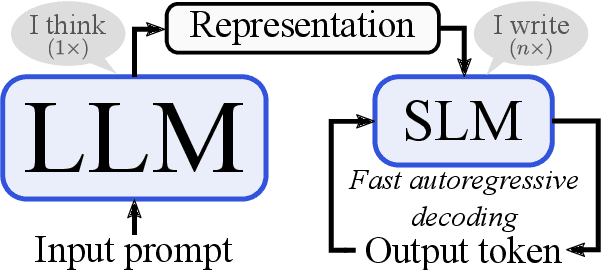
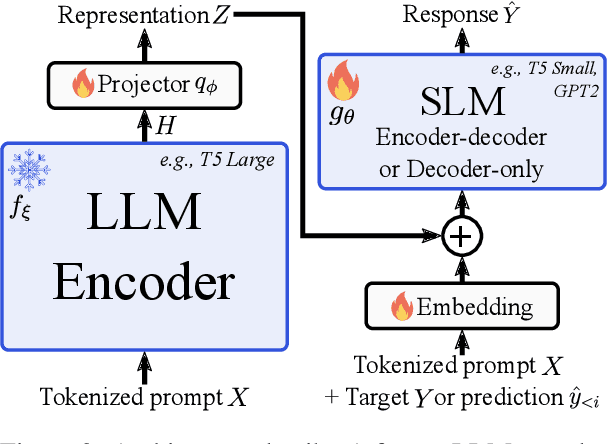
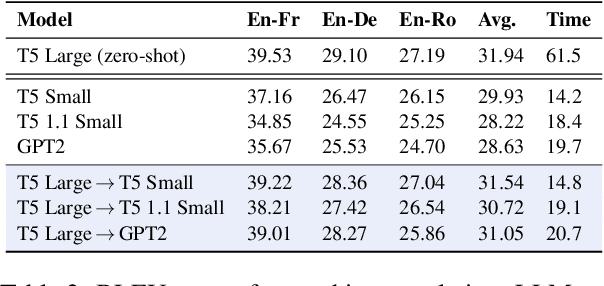
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4\times$, with minor performance penalties of $1-2\%$ for translation and summarization tasks compared to the LLM.
Scalarization for Multi-Task and Multi-Domain Learning at Scale
Oct 13, 2023Training a single model on multiple input domains and/or output tasks allows for compressing information from multiple sources into a unified backbone hence improves model efficiency. It also enables potential positive knowledge transfer across tasks/domains, leading to improved accuracy and data-efficient training. However, optimizing such networks is a challenge, in particular due to discrepancies between the different tasks or domains: Despite several hypotheses and solutions proposed over the years, recent work has shown that uniform scalarization training, i.e., simply minimizing the average of the task losses, yields on-par performance with more costly SotA optimization methods. This raises the issue of how well we understand the training dynamics of multi-task and multi-domain networks. In this work, we first devise a large-scale unified analysis of multi-domain and multi-task learning to better understand the dynamics of scalarization across varied task/domain combinations and model sizes. Following these insights, we then propose to leverage population-based training to efficiently search for the optimal scalarization weights when dealing with a large number of tasks or domains.
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
Jul 05, 2023



The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs (e.g., 20 epochs on ImageNet) with little training overhead. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.
Computational Pathology: A Survey Review and The Way Forward
Apr 11, 2023



Computational Pathology (CoPath) is an interdisciplinary science that augments developments of computational approaches to analyze and model medical histopathology images. The main objective for CoPath is to develop infrastructure and workflows of digital diagnostics as an assistive CAD system for clinical pathology facilitating transformational changes in the diagnosis and treatment of cancer diseases. With evergrowing developments in deep learning and computer vision algorithms, and the ease of the data flow from digital pathology, currently CoPath is witnessing a paradigm shift. Despite the sheer volume of engineering and scientific works being introduced for cancer image analysis, there is still a considerable gap of adopting and integrating these algorithms in clinical practice. This raises a significant question regarding the direction and trends that are undertaken in CoPath. In this article we provide a comprehensive review of more than 700 papers to address the challenges faced in problem design all-the-way to the application and implementation viewpoints. We have catalogued each paper into a model-card by examining the key works and challenges faced to layout the current landscape in CoPath. We hope this helps the community to locate relevant works and facilitate understanding of the field's future directions. In a nutshell, we oversee the CoPath developments in cycle of stages which are required to be cohesively linked together to address the challenges associated with such multidisciplinary science. We overview this cycle from different perspectives of data-centric, model-centric, and application-centric problems. We finally sketch remaining challenges and provide directions for future technical developments and clinical integration of CoPath.
Revisiting Single-gated Mixtures of Experts
Apr 11, 2023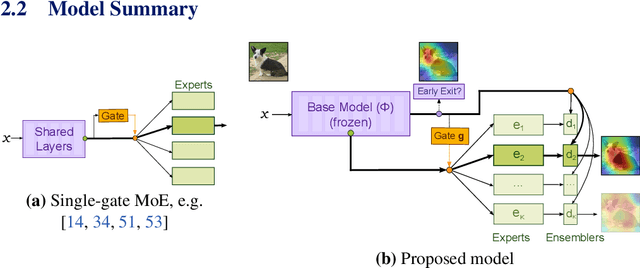
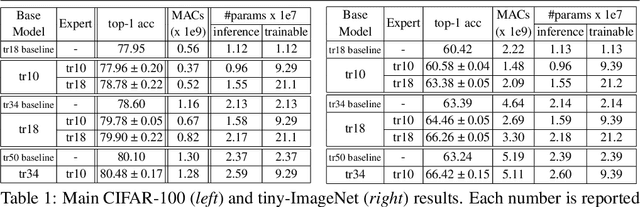
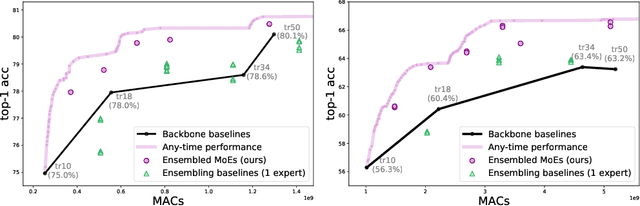
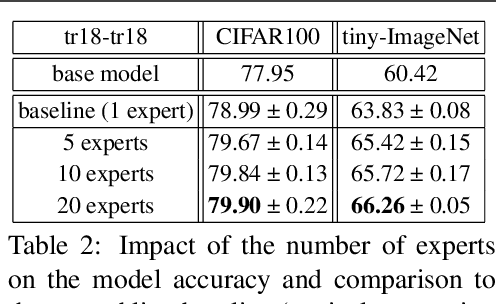
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.