 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient LLM Inference using Dynamic Input Pruning and Cache-Aware Masking
Dec 02, 2024



While mobile devices provide ever more compute power, improvements in DRAM bandwidth are much slower. This is unfortunate for large language model (LLM) token generation, which is heavily memory-bound. Previous work has proposed to leverage natural dynamic activation sparsity in ReLU-activated LLMs to reduce effective DRAM bandwidth per token. However, more recent LLMs use SwiGLU instead of ReLU, which result in little inherent sparsity. While SwiGLU activations can be pruned based on magnitude, the resulting sparsity patterns are difficult to predict, rendering previous approaches ineffective. To circumvent this issue, our work introduces Dynamic Input Pruning (DIP): a predictor-free dynamic sparsification approach, which preserves accuracy with minimal fine-tuning. DIP can further use lightweight LoRA adapters to regain some performance lost during sparsification. Lastly, we describe a novel cache-aware masking strategy, which considers the cache state and activation magnitude to further increase cache hit rate, improving LLM token rate on mobile devices. DIP outperforms other methods in terms of accuracy, memory and throughput trade-offs across simulated hardware settings. On Phi-3-Medium, DIP achieves a 46% reduction in memory and 40% increase in throughput with $<$ 0.1 loss in perplexity.
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Nov 27, 2024



Mixture of Experts (MoE) LLMs have recently gained attention for their ability to enhance performance by selectively engaging specialized subnetworks or "experts" for each input. However, deploying MoEs on memory-constrained devices remains challenging, particularly when generating tokens sequentially with a batch size of one, as opposed to typical high-throughput settings involving long sequences or large batches. In this work, we optimize MoE on memory-constrained devices where only a subset of expert weights fit in DRAM. We introduce a novel cache-aware routing strategy that leverages expert reuse during token generation to improve cache locality. We evaluate our approach on language modeling, MMLU, and GSM8K benchmarks and present on-device results demonstrating 2$\times$ speedups on mobile devices, offering a flexible, training-free solution to extend MoE's applicability across real-world applications.
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Feb 26, 2024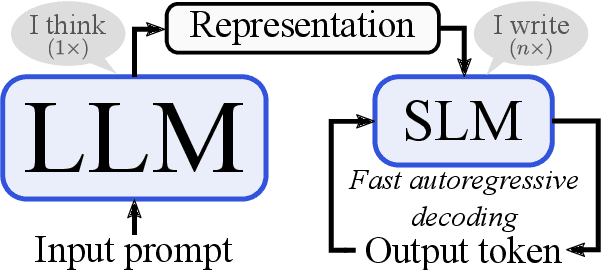
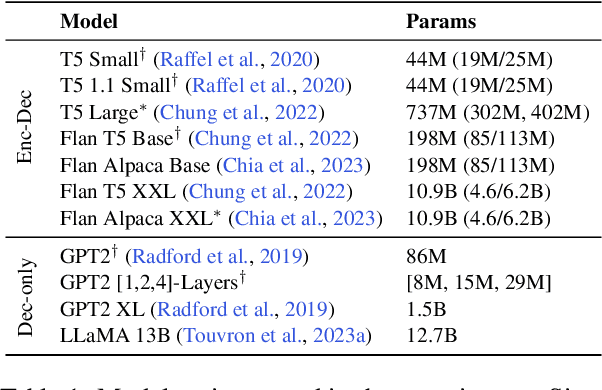
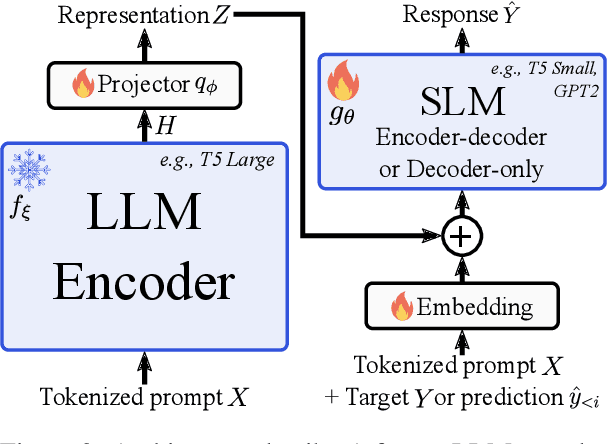
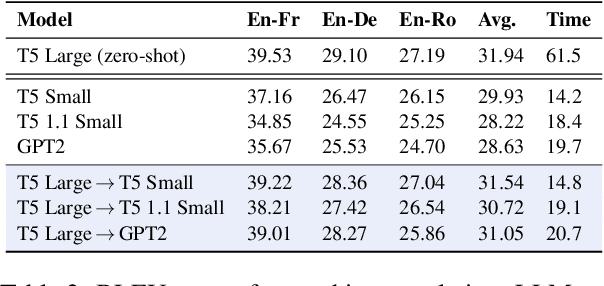
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4\times$, with minor performance penalties of $1-2\%$ for translation and summarization tasks compared to the LLM.
Hyperbolic Convolutional Neural Networks
Aug 29, 2023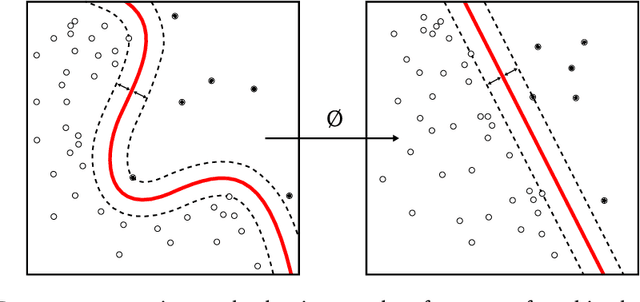
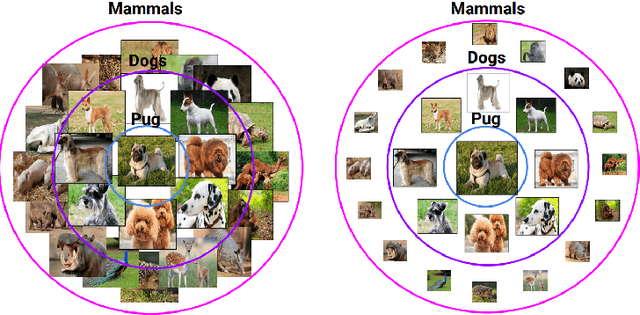
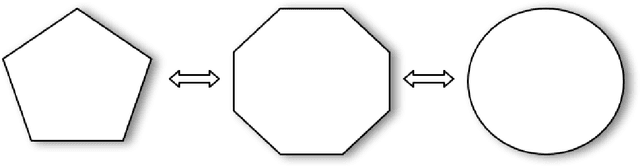
Deep Learning is mostly responsible for the surge of interest in Artificial Intelligence in the last decade. So far, deep learning researchers have been particularly successful in the domain of image processing, where Convolutional Neural Networks are used. Although excelling at image classification, Convolutional Neural Networks are quite naive in that no inductive bias is set on the embedding space for images. Similar flaws are also exhibited by another type of Convolutional Networks - Graph Convolutional Neural Networks. However, using non-Euclidean space for embedding data might result in more robust and explainable models. One example of such a non-Euclidean space is hyperbolic space. Hyperbolic spaces are particularly useful due to their ability to fit more data in a low-dimensional space and tree-likeliness properties. These attractive properties have been previously used in multiple papers which indicated that they are beneficial for building hierarchical embeddings using shallow models and, recently, using MLPs and RNNs. However, no papers have yet suggested a general approach to using Hyperbolic Convolutional Neural Networks for structured data processing, although these are the most common examples of data used. Therefore, the goal of this work is to devise a general recipe for building Hyperbolic Convolutional Neural Networks. We hypothesize that ability of hyperbolic space to capture hierarchy in the data would lead to better performance. This ability should be particularly useful in cases where data has a tree-like structure. Since this is the case for many existing datasets \citep{wordnet, imagenet, fb15k}, we argue that such a model would be advantageous both in terms of applications and future research prospects.
Revisiting Single-gated Mixtures of Experts
Apr 11, 2023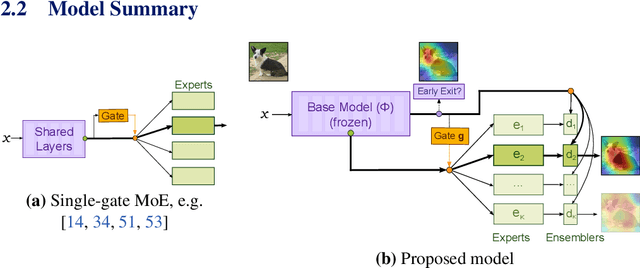
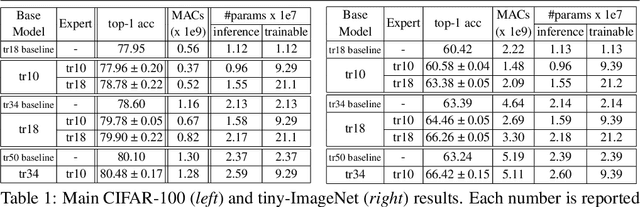
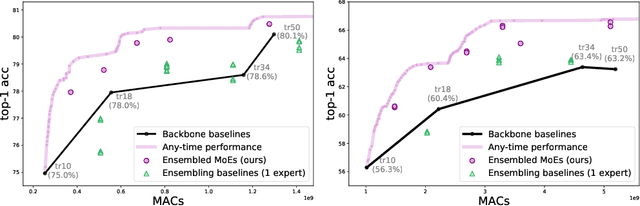
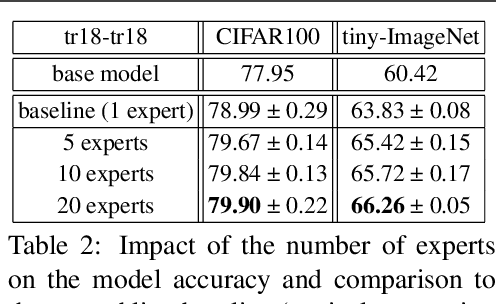
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.
Simple and Efficient Architectures for Semantic Segmentation
Jun 16, 2022
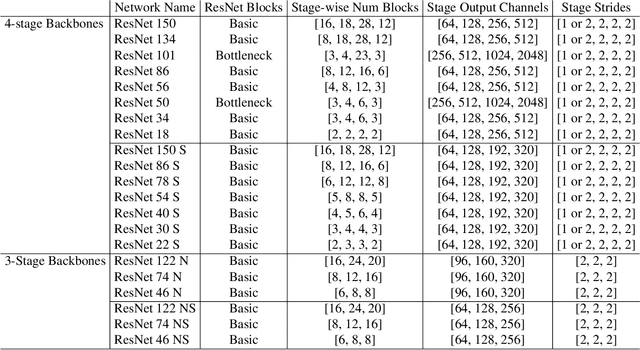
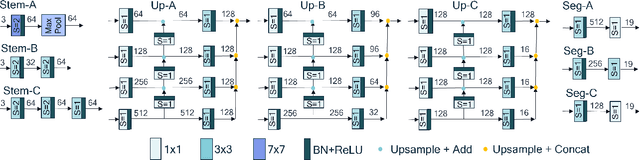
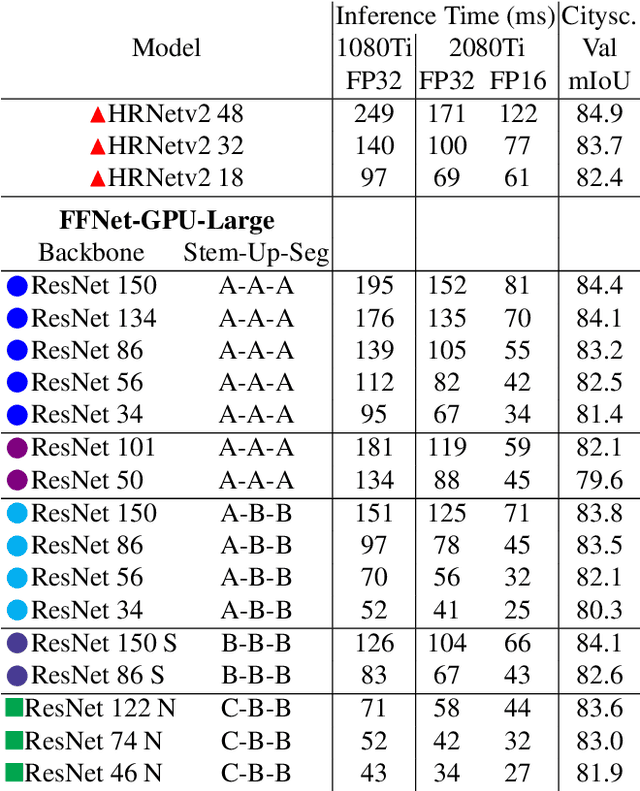
Though the state-of-the architectures for semantic segmentation, such as HRNet, demonstrate impressive accuracy, the complexity arising from their salient design choices hinders a range of model acceleration tools, and further they make use of operations that are inefficient on current hardware. This paper demonstrates that a simple encoder-decoder architecture with a ResNet-like backbone and a small multi-scale head, performs on-par or better than complex semantic segmentation architectures such as HRNet, FANet and DDRNets. Naively applying deep backbones designed for Image Classification to the task of Semantic Segmentation leads to sub-par results, owing to a much smaller effective receptive field of these backbones. Implicit among the various design choices put forth in works like HRNet, DDRNet, and FANet are networks with a large effective receptive field. It is natural to ask if a simple encoder-decoder architecture would compare favorably if comprised of backbones that have a larger effective receptive field, though without the use of inefficient operations like dilated convolutions. We show that with minor and inexpensive modifications to ResNets, enlarging the receptive field, very simple and competitive baselines can be created for Semantic Segmentation. We present a family of such simple architectures for desktop as well as mobile targets, which match or exceed the performance of complex models on the Cityscapes dataset. We hope that our work provides simple yet effective baselines for practitioners to develop efficient semantic segmentation models.
Cyclical Pruning for Sparse Neural Networks
Feb 02, 2022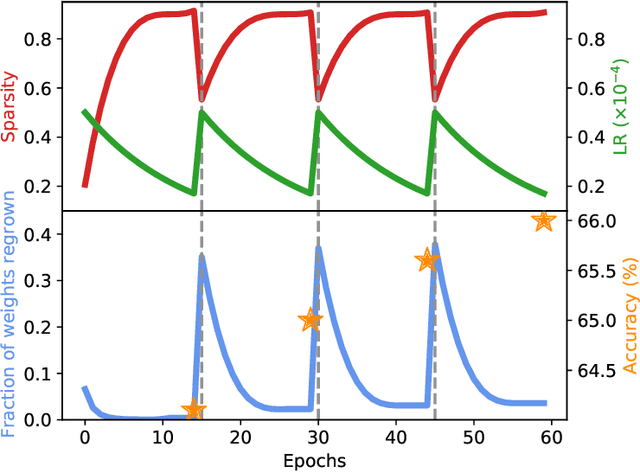
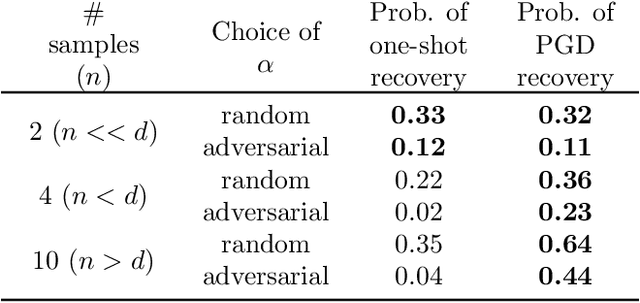
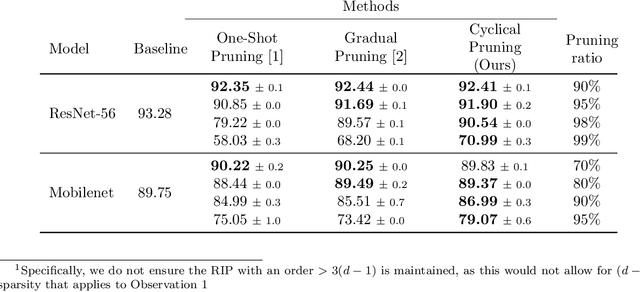
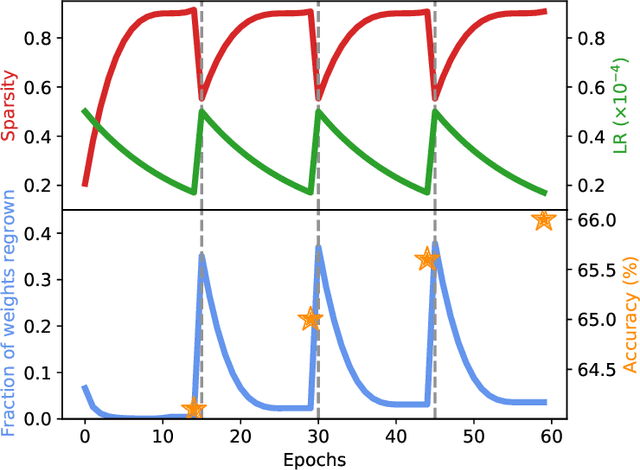
Current methods for pruning neural network weights iteratively apply magnitude-based pruning on the model weights and re-train the resulting model to recover lost accuracy. In this work, we show that such strategies do not allow for the recovery of erroneously pruned weights. To enable weight recovery, we propose a simple strategy called \textit{cyclical pruning} which requires the pruning schedule to be periodic and allows for weights pruned erroneously in one cycle to recover in subsequent ones. Experimental results on both linear models and large-scale deep neural networks show that cyclical pruning outperforms existing pruning algorithms, especially at high sparsity ratios. Our approach is easy to tune and can be readily incorporated into existing pruning pipelines to boost performance.
Distilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Dec 16, 2020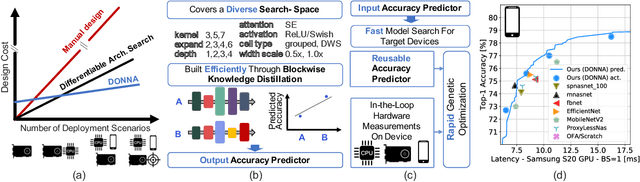



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.