 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Video Diffusion
Dec 10, 2024



Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting their use on mobile devices. This paper introduces the first mobile-optimized video diffusion model. Starting from a spatio-temporal UNet from Stable Video Diffusion (SVD), we reduce memory and computational cost by reducing the frame resolution, incorporating multi-scale temporal representations, and introducing two novel pruning schema to reduce the number of channels and temporal blocks. Furthermore, we employ adversarial finetuning to reduce the denoising to a single step. Our model, coined as MobileVD, is 523x more efficient (1817.2 vs. 4.34 TFLOPs) with a slight quality drop (FVD 149 vs. 171), generating latents for a 14x512x256 px clip in 1.7 seconds on a Xiaomi-14 Pro. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-diffusion/
VaLID: Variable-Length Input Diffusion for Novel View Synthesis
Dec 14, 2023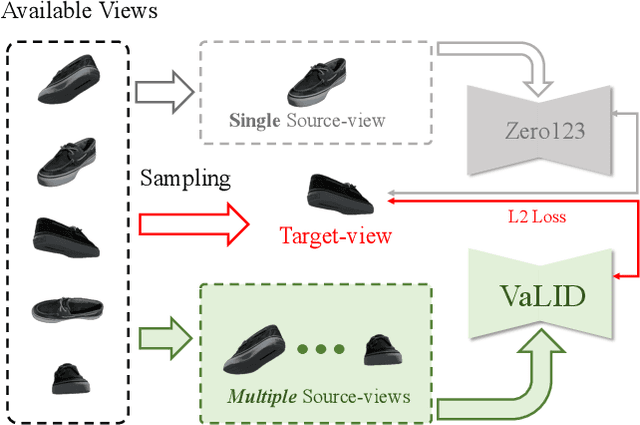

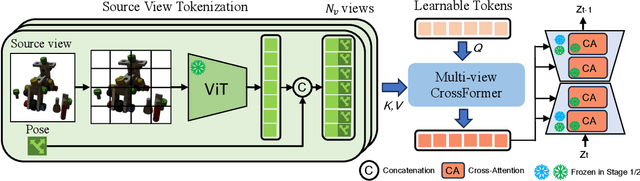
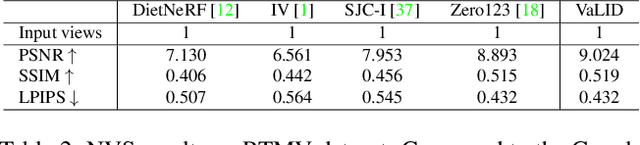
Novel View Synthesis (NVS), which tries to produce a realistic image at the target view given source view images and their corresponding poses, is a fundamental problem in 3D Vision. As this task is heavily under-constrained, some recent work, like Zero123, tries to solve this problem with generative modeling, specifically using pre-trained diffusion models. Although this strategy generalizes well to new scenes, compared to neural radiance field-based methods, it offers low levels of flexibility. For example, it can only accept a single-view image as input, despite realistic applications often offering multiple input images. This is because the source-view images and corresponding poses are processed separately and injected into the model at different stages. Thus it is not trivial to generalize the model into multi-view source images, once they are available. To solve this issue, we try to process each pose image pair separately and then fuse them as a unified visual representation which will be injected into the model to guide image synthesis at the target-views. However, inconsistency and computation costs increase as the number of input source-view images increases. To solve these issues, the Multi-view Cross Former module is proposed which maps variable-length input data to fix-size output data. A two-stage training strategy is introduced to further improve the efficiency during training time. Qualitative and quantitative evaluation over multiple datasets demonstrates the effectiveness of the proposed method against previous approaches. The code will be released according to the acceptance.
ResQ: Residual Quantization for Video Perception
Aug 18, 2023



This paper accelerates video perception, such as semantic segmentation and human pose estimation, by levering cross-frame redundancies. Unlike the existing approaches, which avoid redundant computations by warping the past features using optical-flow or by performing sparse convolutions on frame differences, we approach the problem from a new perspective: low-bit quantization. We observe that residuals, as the difference in network activations between two neighboring frames, exhibit properties that make them highly quantizable. Based on this observation, we propose a novel quantization scheme for video networks coined as Residual Quantization. ResQ extends the standard, frame-by-frame, quantization scheme by incorporating temporal dependencies that lead to better performance in terms of accuracy vs. bit-width. Furthermore, we extend our model to dynamically adjust the bit-width proportional to the amount of changes in the video. We demonstrate the superiority of our model, against the standard quantization and existing efficient video perception models, using various architectures on semantic segmentation and human pose estimation benchmarks.
Simple and Efficient Architectures for Semantic Segmentation
Jun 16, 2022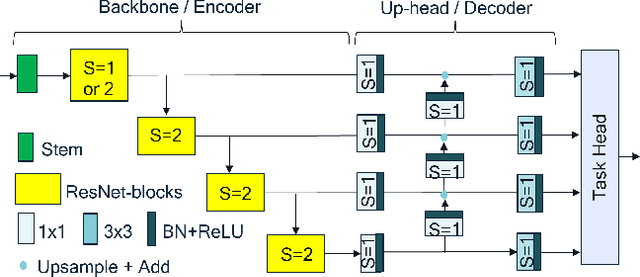
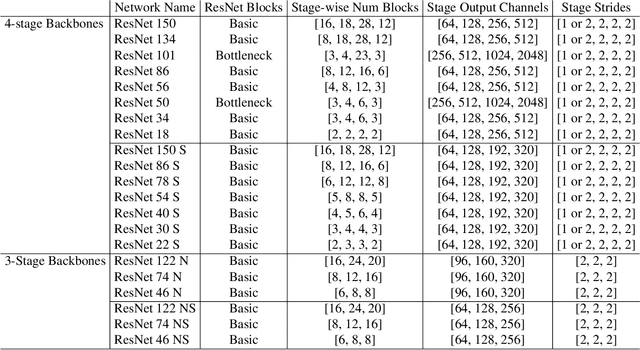
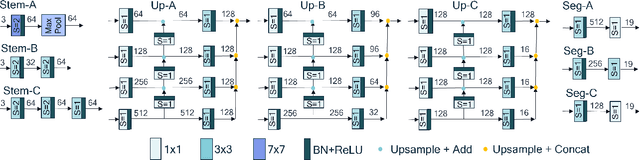
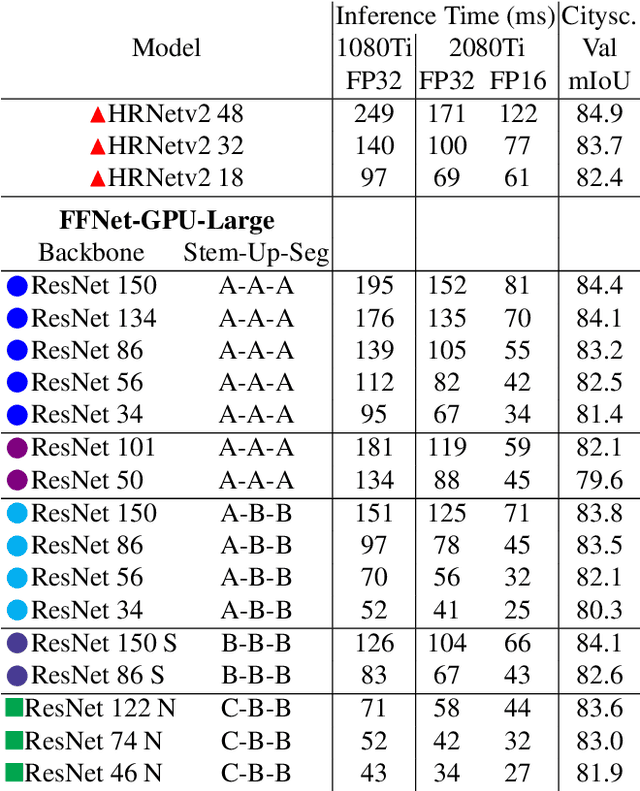
Though the state-of-the architectures for semantic segmentation, such as HRNet, demonstrate impressive accuracy, the complexity arising from their salient design choices hinders a range of model acceleration tools, and further they make use of operations that are inefficient on current hardware. This paper demonstrates that a simple encoder-decoder architecture with a ResNet-like backbone and a small multi-scale head, performs on-par or better than complex semantic segmentation architectures such as HRNet, FANet and DDRNets. Naively applying deep backbones designed for Image Classification to the task of Semantic Segmentation leads to sub-par results, owing to a much smaller effective receptive field of these backbones. Implicit among the various design choices put forth in works like HRNet, DDRNet, and FANet are networks with a large effective receptive field. It is natural to ask if a simple encoder-decoder architecture would compare favorably if comprised of backbones that have a larger effective receptive field, though without the use of inefficient operations like dilated convolutions. We show that with minor and inexpensive modifications to ResNets, enlarging the receptive field, very simple and competitive baselines can be created for Semantic Segmentation. We present a family of such simple architectures for desktop as well as mobile targets, which match or exceed the performance of complex models on the Cityscapes dataset. We hope that our work provides simple yet effective baselines for practitioners to develop efficient semantic segmentation models.
Delta Distillation for Efficient Video Processing
Mar 17, 2022
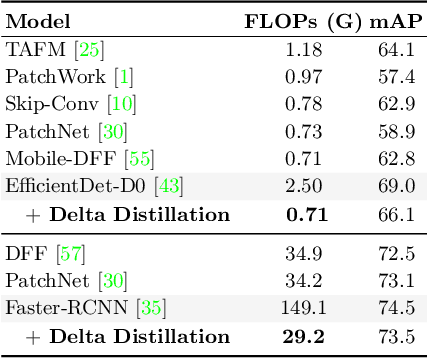

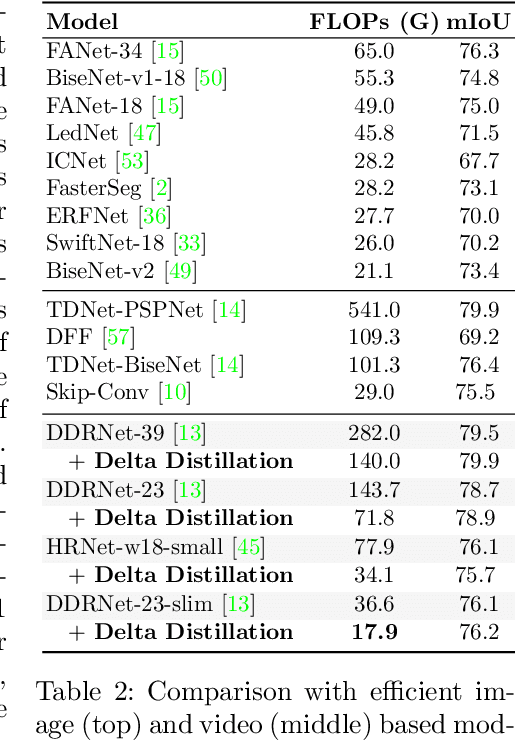
This paper aims to accelerate video stream processing, such as object detection and semantic segmentation, by leveraging the temporal redundancies that exist between video frames. Instead of propagating and warping features using motion alignment, such as optical flow, we propose a novel knowledge distillation schema coined as Delta Distillation. In our proposal, the student learns the variations in the teacher's intermediate features over time. We demonstrate that these temporal variations can be effectively distilled due to the temporal redundancies within video frames. During inference, both teacher and student cooperate for providing predictions: the former by providing initial representations extracted only on the key-frame, and the latter by iteratively estimating and applying deltas for the successive frames. Moreover, we consider various design choices to learn optimal student architectures including an end-to-end learnable architecture search. By extensive experiments on a wide range of architectures, including the most efficient ones, we demonstrate that delta distillation sets a new state of the art in terms of accuracy vs. efficiency trade-off for semantic segmentation and object detection in videos. Finally, we show that, as a by-product, delta distillation improves the temporal consistency of the teacher model.