 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Uniformity and Alignment for Multimodal Representation Learning
Feb 10, 2026Multimodal representation learning aims to construct a shared embedding space in which heterogeneous modalities are semantically aligned. Despite strong empirical results, InfoNCE-based objectives introduce inherent conflicts that yield distribution gaps across modalities. In this work, we identify two conflicts in the multimodal regime, both exacerbated as the number of modalities increases: (i) an alignment-uniformity conflict, whereby the repulsion of uniformity undermines pairwise alignment, and (ii) an intra-alignment conflict, where aligning multiple modalities induces competing alignment directions. To address these issues, we propose a principled decoupling of alignment and uniformity for multimodal representations, providing a conflict-free recipe for multimodal learning that simultaneously supports discriminative and generative use cases without task-specific modules. We then provide a theoretical guarantee that our method acts as an efficient proxy for a global Hölder divergence over multiple modality distributions, and thus reduces the distribution gap among modalities. Extensive experiments on retrieval and UnCLIP-style generation demonstrate consistent gains.
Superposition as Lossy Compression: Measure with Sparse Autoencoders and Connect to Adversarial Vulnerability
Dec 15, 2025Neural networks achieve remarkable performance through superposition: encoding multiple features as overlapping directions in activation space rather than dedicating individual neurons to each feature. This challenges interpretability, yet we lack principled methods to measure superposition. We present an information-theoretic framework measuring a neural representation's effective degrees of freedom. We apply Shannon entropy to sparse autoencoder activations to compute the number of effective features as the minimum neurons needed for interference-free encoding. Equivalently, this measures how many "virtual neurons" the network simulates through superposition. When networks encode more effective features than actual neurons, they must accept interference as the price of compression. Our metric strongly correlates with ground truth in toy models, detects minimal superposition in algorithmic tasks, and reveals systematic reduction under dropout. Layer-wise patterns mirror intrinsic dimensionality studies on Pythia-70M. The metric also captures developmental dynamics, detecting sharp feature consolidation during grokking. Surprisingly, adversarial training can increase effective features while improving robustness, contradicting the hypothesis that superposition causes vulnerability. Instead, the effect depends on task complexity and network capacity: simple tasks with ample capacity allow feature expansion (abundance regime), while complex tasks or limited capacity force reduction (scarcity regime). By defining superposition as lossy compression, this work enables principled measurement of how neural networks organize information under computational constraints, connecting superposition to adversarial robustness.
* Accepted to TMLR, view HTML here: https://leonardbereska.github.io/blog/2025/superposition/
Unleashing Uncertainty: Efficient Machine Unlearning for Generative AI
Aug 28, 2025We introduce SAFEMax, a novel method for Machine Unlearning in diffusion models. Grounded in information-theoretic principles, SAFEMax maximizes the entropy in generated images, causing the model to generate Gaussian noise when conditioned on impermissible classes by ultimately halting its denoising process. Also, our method controls the balance between forgetting and retention by selectively focusing on the early diffusion steps, where class-specific information is prominent. Our results demonstrate the effectiveness of SAFEMax and highlight its substantial efficiency gains over state-of-the-art methods.
MoSiC: Optimal-Transport Motion Trajectory for Dense Self-Supervised Learning
Jun 10, 2025



Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to the complexity of motion dynamics. Existing approaches struggle as they rely on static augmentations that fail under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. We propose a motion-guided self-supervised learning framework that clusters dense point tracks to learn spatiotemporally consistent representations. By leveraging an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering through a momentum-encoder-based optimal transport mechanism. To ensure temporal coherence, we propagate cluster assignments along tracked points, enforcing feature consistency across views despite viewpoint changes. Integrating motion as an implicit supervisory signal, our method learns representations that generalize across frames, improving robustness in dynamic scenes and challenging occlusion scenarios. By initializing from strong image-pretrained models and leveraging video data for training, we improve state-of-the-art by 1% to 6% on six image and video datasets and four evaluation benchmarks. The implementation is publicly available at our GitHub repository: https://github.com/SMSD75/MoSiC/tree/main
Probabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
May 03, 2025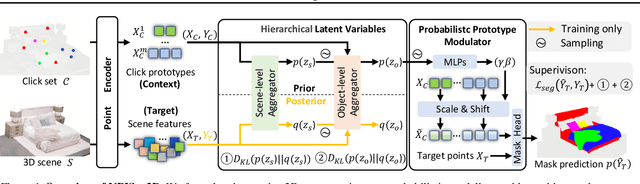
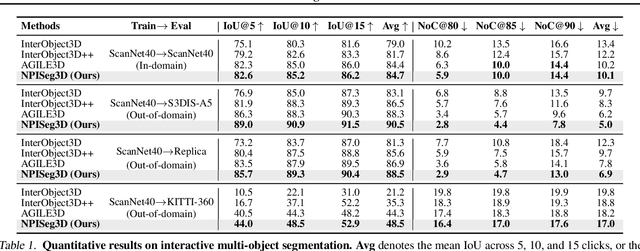
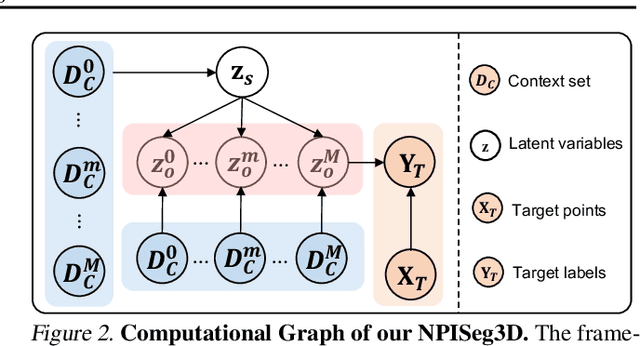
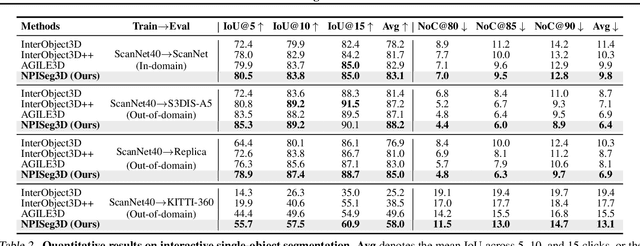
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model's ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning
Mar 27, 2025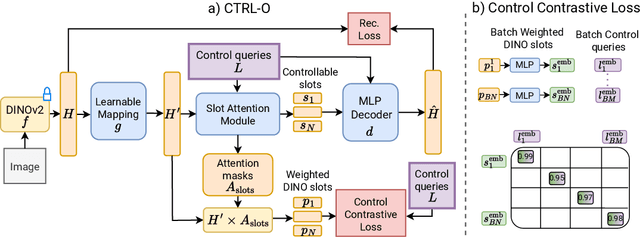

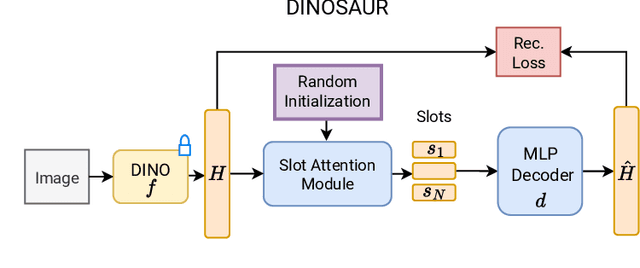
Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. Current state-of-the-art object-centric models have shown remarkable success in object discovery in diverse domains, including complex real-world scenes. However, these models suffer from a key limitation: they lack controllability. Specifically, current object-centric models learn representations based on their preconceived understanding of objects, without allowing user input to guide which objects are represented. Introducing controllability into object-centric models could unlock a range of useful capabilities, such as the ability to extract instance-specific representations from a scene. In this work, we propose a novel approach for user-directed control over slot representations by conditioning slots on language descriptions. The proposed ConTRoLlable Object-centric representation learning approach, which we term CTRL-O, achieves targeted object-language binding in complex real-world scenes without requiring mask supervision. Next, we apply these controllable slot representations on two downstream vision language tasks: text-to-image generation and visual question answering. The proposed approach enables instance-specific text-to-image generation and also achieves strong performance on visual question answering.
Mechanistic PDE Networks for Discovery of Governing Equations
Feb 25, 2025



We present Mechanistic PDE Networks -- a model for discovery of governing partial differential equations from data. Mechanistic PDE Networks represent spatiotemporal data as space-time dependent linear partial differential equations in neural network hidden representations. The represented PDEs are then solved and decoded for specific tasks. The learned PDE representations naturally express the spatiotemporal dynamics in data in neural network hidden space, enabling increased power for dynamical modeling. Solving the PDE representations in a compute and memory-efficient way, however, is a significant challenge. We develop a native, GPU-capable, parallel, sparse, and differentiable multigrid solver specialized for linear partial differential equations that acts as a module in Mechanistic PDE Networks. Leveraging the PDE solver, we propose a discovery architecture that can discover nonlinear PDEs in complex settings while also being robust to noise. We validate PDE discovery on a number of PDEs, including reaction-diffusion and Navier-Stokes equations.
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Geometric Neural Process Fields
Feb 04, 2025This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.
ECTIL: Label-efficient Computational Tumour Infiltrating Lymphocyte (TIL) assessment in breast cancer: Multicentre validation in 2,340 patients with breast cancer
Jan 24, 2025



The level of tumour-infiltrating lymphocytes (TILs) is a prognostic factor for patients with (triple-negative) breast cancer (BC). Computational TIL assessment (CTA) has the potential to assist pathologists in this labour-intensive task, but current CTA models rely heavily on many detailed annotations. We propose and validate a fundamentally simpler deep learning based CTA that can be trained in only ten minutes on hundredfold fewer pathologist annotations. We collected whole slide images (WSIs) with TILs scores and clinical data of 2,340 patients with BC from six cohorts including three randomised clinical trials. Morphological features were extracted from whole slide images (WSIs) using a pathology foundation model. Our label-efficient Computational stromal TIL assessment model (ECTIL) directly regresses the TILs score from these features. ECTIL trained on only a few hundred samples (ECTIL-TCGA) showed concordance with the pathologist over five heterogeneous external cohorts (r=0.54-0.74, AUROC=0.80-0.94). Training on all slides of five cohorts (ECTIL-combined) improved results on a held-out test set (r=0.69, AUROC=0.85). Multivariable Cox regression analyses indicated that every 10% increase of ECTIL scores was associated with improved overall survival independent of clinicopathological variables (HR 0.86, p<0.01), similar to the pathologist score (HR 0.87, p<0.001). We demonstrate that ECTIL is highly concordant with an expert pathologist and obtains a similar hazard ratio. ECTIL has a fundamentally simpler design than existing methods and can be trained on orders of magnitude fewer annotations. Such a CTA may be used to pre-screen patients for, e.g., immunotherapy clinical trial inclusion, or as a tool to assist clinicians in the diagnostic work-up of patients with BC. Our model is available under an open source licence (https://github.com/nki-ai/ectil).