 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkelSplat: Robust Multi-view 3D Human Pose Estimation with Differentiable Gaussian Rendering
Nov 11, 2025Accurate 3D human pose estimation is fundamental for applications such as augmented reality and human-robot interaction. State-of-the-art multi-view methods learn to fuse predictions across views by training on large annotated datasets, leading to poor generalization when the test scenario differs. To overcome these limitations, we propose SkelSplat, a novel framework for multi-view 3D human pose estimation based on differentiable Gaussian rendering. Human pose is modeled as a skeleton of 3D Gaussians, one per joint, optimized via differentiable rendering to enable seamless fusion of arbitrary camera views without 3D ground-truth supervision. Since Gaussian Splatting was originally designed for dense scene reconstruction, we propose a novel one-hot encoding scheme that enables independent optimization of human joints. SkelSplat outperforms approaches that do not rely on 3D ground truth in Human3.6M and CMU, while reducing the cross-dataset error up to 47.8% compared to learning-based methods. Experiments on Human3.6M-Occ and Occlusion-Person demonstrate robustness to occlusions, without scenario-specific fine-tuning. Our project page is available here: https://skelsplat.github.io.
Calib3R: A 3D Foundation Model for Multi-Camera to Robot Calibration and 3D Metric-Scaled Scene Reconstruction
Sep 10, 2025Robots often rely on RGB images for tasks like manipulation and navigation. However, reliable interaction typically requires a 3D scene representation that is metric-scaled and aligned with the robot reference frame. This depends on accurate camera-to-robot calibration and dense 3D reconstruction, tasks usually treated separately, despite both relying on geometric correspondences from RGB data. Traditional calibration needs patterns, while RGB-based reconstruction yields geometry with an unknown scale in an arbitrary frame. Multi-camera setups add further complexity, as data must be expressed in a shared reference frame. We present Calib3R, a patternless method that jointly performs camera-to-robot calibration and metric-scaled 3D reconstruction via unified optimization. Calib3R handles single- and multi-camera setups on robot arms or mobile robots. It builds on the 3D foundation model MASt3R to extract pointmaps from RGB images, which are combined with robot poses to reconstruct a scaled 3D scene aligned with the robot. Experiments on diverse datasets show that Calib3R achieves accurate calibration with less than 10 images, outperforming target-less and marker-based methods.
Stress-Aware Resilient Neural Training
Jul 31, 2025This paper introduces Stress-Aware Learning, a resilient neural training paradigm in which deep neural networks dynamically adjust their optimization behavior - whether under stable training regimes or in settings with uncertain dynamics - based on the concept of Temporary (Elastic) and Permanent (Plastic) Deformation, inspired by structural fatigue in materials science. To instantiate this concept, we propose Plastic Deformation Optimizer, a stress-aware mechanism that injects adaptive noise into model parameters whenever an internal stress signal - reflecting stagnation in training loss and accuracy - indicates persistent optimization difficulty. This enables the model to escape sharp minima and converge toward flatter, more generalizable regions of the loss landscape. Experiments across six architectures, four optimizers, and seven vision benchmarks demonstrate improved robustness and generalization with minimal computational overhead. The code and 3D visuals will be available on GitHub: https://github.com/Stress-Aware-Learning/SAL.
Unit-Based Histopathology Tissue Segmentation via Multi-Level Feature Representation
Jul 16, 2025We propose UTS, a unit-based tissue segmentation framework for histopathology that classifies each fixed-size 32 * 32 tile, rather than each pixel, as the segmentation unit. This approach reduces annotation effort and improves computational efficiency without compromising accuracy. To implement this approach, we introduce a Multi-Level Vision Transformer (L-ViT), which benefits the multi-level feature representation to capture both fine-grained morphology and global tissue context. Trained to segment breast tissue into three categories (infiltrating tumor, non-neoplastic stroma, and fat), UTS supports clinically relevant tasks such as tumor-stroma quantification and surgical margin assessment. Evaluated on 386,371 tiles from 459 H&E-stained regions, it outperforms U-Net variants and transformer-based baselines. Code and Dataset will be available at GitHub.
VeLU: Variance-enhanced Learning Unit for Deep Neural Networks
Apr 21, 2025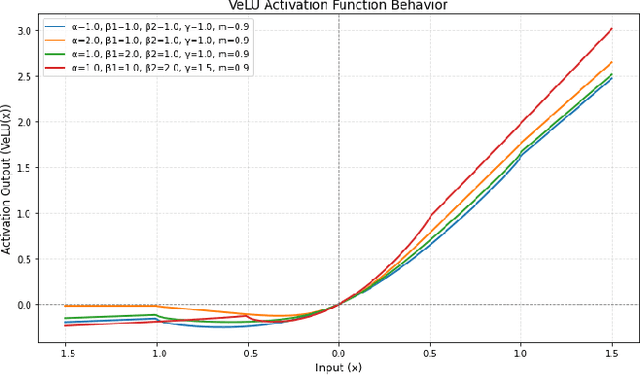
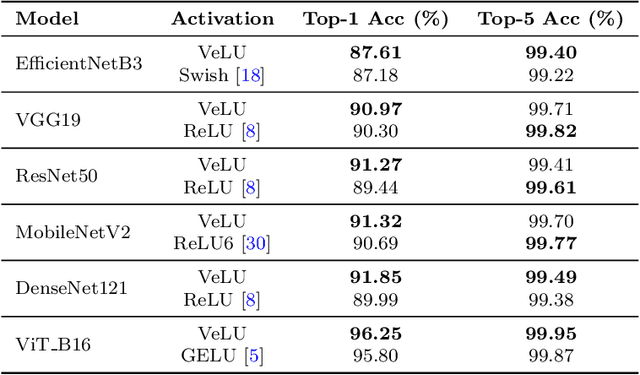
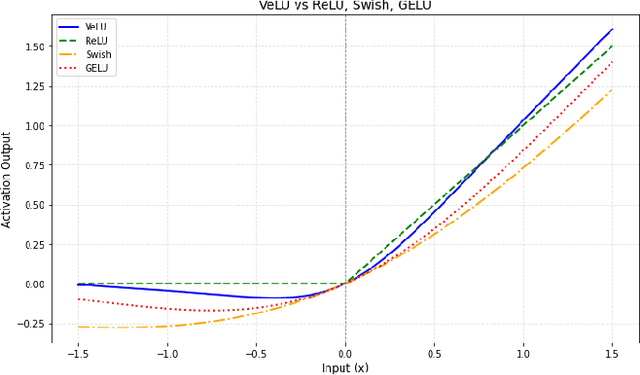
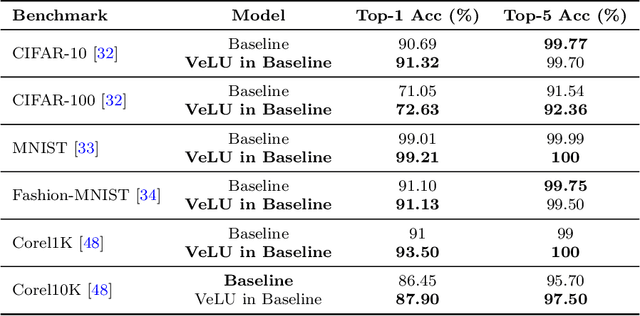
Activation functions are fundamental in deep neural networks and directly impact gradient flow, optimization stability, and generalization. Although ReLU remains standard because of its simplicity, it suffers from vanishing gradients and lacks adaptability. Alternatives like Swish and GELU introduce smooth transitions, but fail to dynamically adjust to input statistics. We propose VeLU, a Variance-enhanced Learning Unit as an activation function that dynamically scales based on input variance by integrating ArcTan-Sin transformations and Wasserstein-2 regularization, effectively mitigating covariate shifts and stabilizing optimization. Extensive experiments on ViT_B16, VGG19, ResNet50, DenseNet121, MobileNetV2, and EfficientNetB3 confirm VeLU's superiority over ReLU, ReLU6, Swish, and GELU on six vision benchmarks. The codes of VeLU are publicly available on GitHub.
Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
Dec 19, 2024A world model provides an agent with a representation of its environment, enabling it to predict the causal consequences of its actions. Current world models typically cannot directly and explicitly imitate the actual environment in front of a robot, often resulting in unrealistic behaviors and hallucinations that make them unsuitable for real-world applications. In this paper, we introduce a new paradigm for constructing world models that are explicit representations of the real world and its dynamics. By integrating cutting-edge advances in real-time photorealism with Gaussian Splatting and physics simulators, we propose the first compositional manipulation world model, which we call DreMa. DreMa replicates the observed world and its dynamics, allowing it to imagine novel configurations of objects and predict the future consequences of robot actions. We leverage this capability to generate new data for imitation learning by applying equivariant transformations to a small set of demonstrations. Our evaluations across various settings demonstrate significant improvements in both accuracy and robustness by incrementing actions and object distributions, reducing the data needed to learn a policy and improving the generalization of the agents. As a highlight, we show that a real Franka Emika Panda robot, powered by DreMa's imagination, can successfully learn novel physical tasks from just a single example per task variation (one-shot policy learning). Our project page and source code can be found in https://leobarcellona.github.io/DreamToManipulate/
MEMROC: Multi-Eye to Mobile RObot Calibration
Oct 11, 2024This paper presents MEMROC (Multi-Eye to Mobile RObot Calibration), a novel motion-based calibration method that simplifies the process of accurately calibrating multiple cameras relative to a mobile robot's reference frame. MEMROC utilizes a known calibration pattern to facilitate accurate calibration with a lower number of images during the optimization process. Additionally, it leverages robust ground plane detection for comprehensive 6-DoF extrinsic calibration, overcoming a critical limitation of many existing methods that struggle to estimate the complete camera pose. The proposed method addresses the need for frequent recalibration in dynamic environments, where cameras may shift slightly or alter their positions due to daily usage, operational adjustments, or vibrations from mobile robot movements. MEMROC exhibits remarkable robustness to noisy odometry data, requiring minimal calibration input data. This combination makes it highly suitable for daily operations involving mobile robots. A comprehensive set of experiments on both synthetic and real data proves MEMROC's efficiency, surpassing existing state-of-the-art methods in terms of accuracy, robustness, and ease of use. To facilitate further research, we have made our code publicly available at https://github.com/davidea97/MEMROC.git.
WasteGAN: Data Augmentation for Robotic Waste Sorting through Generative Adversarial Networks
Sep 25, 2024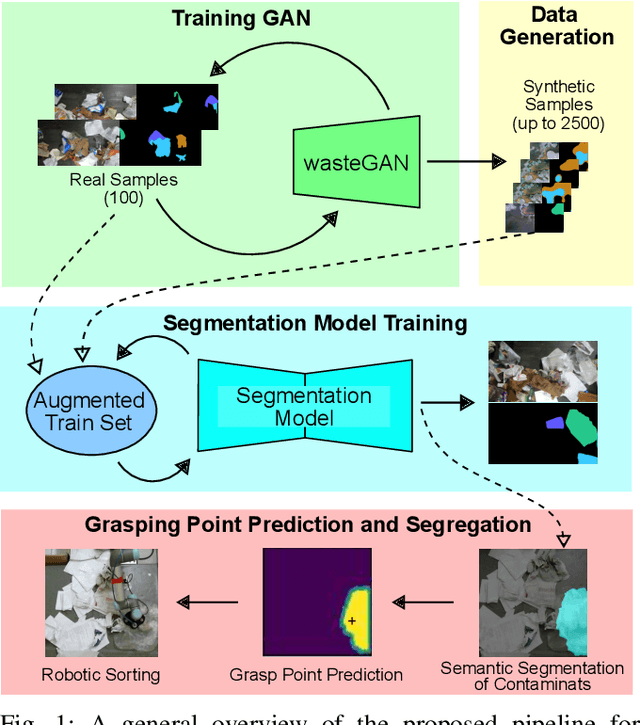
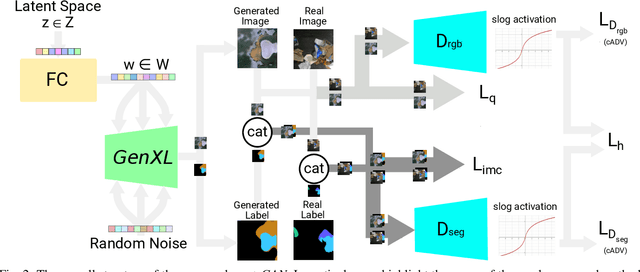
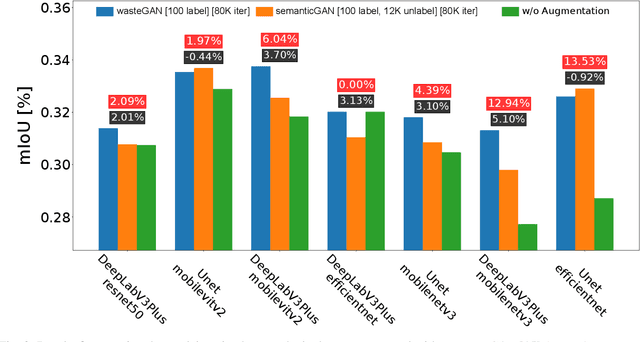
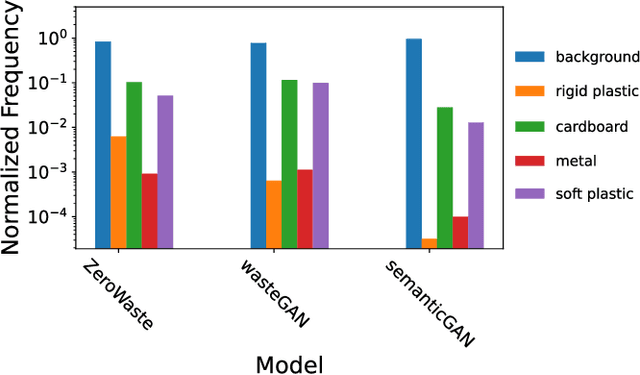
Robotic waste sorting poses significant challenges in both perception and manipulation, given the extreme variability of objects that should be recognized on a cluttered conveyor belt. While deep learning has proven effective in solving complex tasks, the necessity for extensive data collection and labeling limits its applicability in real-world scenarios like waste sorting. To tackle this issue, we introduce a data augmentation method based on a novel GAN architecture called wasteGAN. The proposed method allows to increase the performance of semantic segmentation models, starting from a very limited bunch of labeled examples, such as few as 100. The key innovations of wasteGAN include a novel loss function, a novel activation function, and a larger generator block. Overall, such innovations helps the network to learn from limited number of examples and synthesize data that better mirrors real-world distributions. We then leverage the higher-quality segmentation masks predicted from models trained on the wasteGAN synthetic data to compute semantic-aware grasp poses, enabling a robotic arm to effectively recognizing contaminants and separating waste in a real-world scenario. Through comprehensive evaluation encompassing dataset-based assessments and real-world experiments, our methodology demonstrated promising potential for robotic waste sorting, yielding performance gains of up to 5.8\% in picking contaminants. The project page is available at https://github.com/bach05/wasteGAN.git
SOOD-ImageNet: a Large-Scale Dataset for Semantic Out-Of-Distribution Image Classification and Semantic Segmentation
Sep 02, 2024



Out-of-Distribution (OOD) detection in computer vision is a crucial research area, with related benchmarks playing a vital role in assessing the generalizability of models and their applicability in real-world scenarios. However, existing OOD benchmarks in the literature suffer from two main limitations: (1) they often overlook semantic shift as a potential challenge, and (2) their scale is limited compared to the large datasets used to train modern models. To address these gaps, we introduce SOOD-ImageNet, a novel dataset comprising around 1.6M images across 56 classes, designed for common computer vision tasks such as image classification and semantic segmentation under OOD conditions, with a particular focus on the issue of semantic shift. We ensured the necessary scalability and quality by developing an innovative data engine that leverages the capabilities of modern vision-language models, complemented by accurate human checks. Through extensive training and evaluation of various models on SOOD-ImageNet, we showcase its potential to significantly advance OOD research in computer vision. The project page is available at https://github.com/bach05/SOODImageNet.git.
Multi-view Pose Fusion for Occlusion-Aware 3D Human Pose Estimation
Aug 28, 2024



Robust 3D human pose estimation is crucial to ensure safe and effective human-robot collaboration. Accurate human perception,however, is particularly challenging in these scenarios due to strong occlusions and limited camera viewpoints. Current 3D human pose estimation approaches are rather vulnerable in such conditions. In this work we present a novel approach for robust 3D human pose estimation in the context of human-robot collaboration. Instead of relying on noisy 2D features triangulation, we perform multi-view fusion on 3D skeletons provided by absolute monocular methods. Accurate 3D pose estimation is then obtained via reprojection error optimization, introducing limbs length symmetry constraints. We evaluate our approach on the public dataset Human3.6M and on a novel version Human3.6M-Occluded, derived adding synthetic occlusions on the camera views with the purpose of testing pose estimation algorithms under severe occlusions. We further validate our method on real human-robot collaboration workcells, in which we strongly surpass current 3D human pose estimation methods. Our approach outperforms state-of-the-art multi-view human pose estimation techniques and demonstrates superior capabilities in handling challenging scenarios with strong occlusions, representing a reliable and effective solution for real human-robot collaboration setups.