 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-Aware Resilient Neural Training
Jul 31, 2025This paper introduces Stress-Aware Learning, a resilient neural training paradigm in which deep neural networks dynamically adjust their optimization behavior - whether under stable training regimes or in settings with uncertain dynamics - based on the concept of Temporary (Elastic) and Permanent (Plastic) Deformation, inspired by structural fatigue in materials science. To instantiate this concept, we propose Plastic Deformation Optimizer, a stress-aware mechanism that injects adaptive noise into model parameters whenever an internal stress signal - reflecting stagnation in training loss and accuracy - indicates persistent optimization difficulty. This enables the model to escape sharp minima and converge toward flatter, more generalizable regions of the loss landscape. Experiments across six architectures, four optimizers, and seven vision benchmarks demonstrate improved robustness and generalization with minimal computational overhead. The code and 3D visuals will be available on GitHub: https://github.com/Stress-Aware-Learning/SAL.
Unit-Based Histopathology Tissue Segmentation via Multi-Level Feature Representation
Jul 16, 2025We propose UTS, a unit-based tissue segmentation framework for histopathology that classifies each fixed-size 32 * 32 tile, rather than each pixel, as the segmentation unit. This approach reduces annotation effort and improves computational efficiency without compromising accuracy. To implement this approach, we introduce a Multi-Level Vision Transformer (L-ViT), which benefits the multi-level feature representation to capture both fine-grained morphology and global tissue context. Trained to segment breast tissue into three categories (infiltrating tumor, non-neoplastic stroma, and fat), UTS supports clinically relevant tasks such as tumor-stroma quantification and surgical margin assessment. Evaluated on 386,371 tiles from 459 H&E-stained regions, it outperforms U-Net variants and transformer-based baselines. Code and Dataset will be available at GitHub.
PhenoKG: Knowledge Graph-Driven Gene Discovery and Patient Insights from Phenotypes Alone
Jun 16, 2025Identifying causative genes from patient phenotypes remains a significant challenge in precision medicine, with important implications for the diagnosis and treatment of genetic disorders. We propose a novel graph-based approach for predicting causative genes from patient phenotypes, with or without an available list of candidate genes, by integrating a rare disease knowledge graph (KG). Our model, combining graph neural networks and transformers, achieves substantial improvements over the current state-of-the-art. On the real-world MyGene2 dataset, it attains a mean reciprocal rank (MRR) of 24.64\% and nDCG@100 of 33.64\%, surpassing the best baseline (SHEPHERD) at 19.02\% MRR and 30.54\% nDCG@100. We perform extensive ablation studies to validate the contribution of each model component. Notably, the approach generalizes to cases where only phenotypic data are available, addressing key challenges in clinical decision support when genomic information is incomplete.
VeLU: Variance-enhanced Learning Unit for Deep Neural Networks
Apr 21, 2025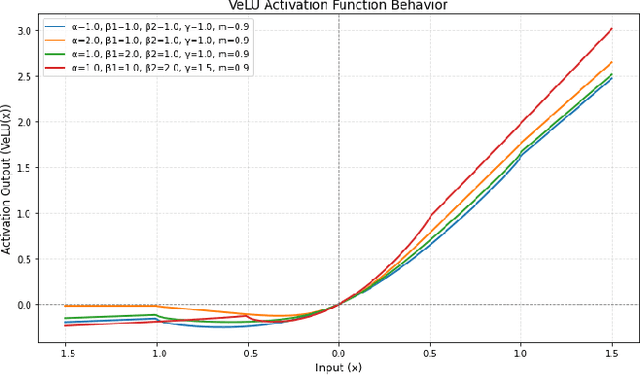
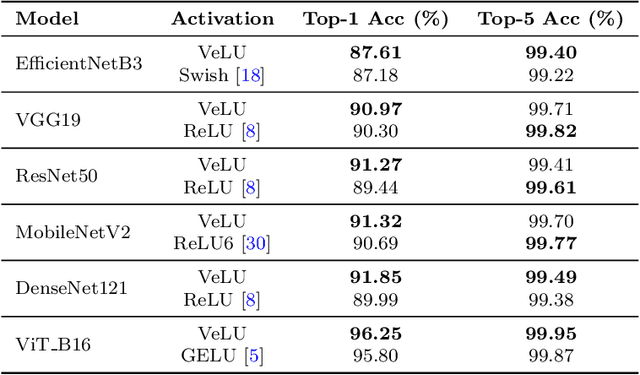
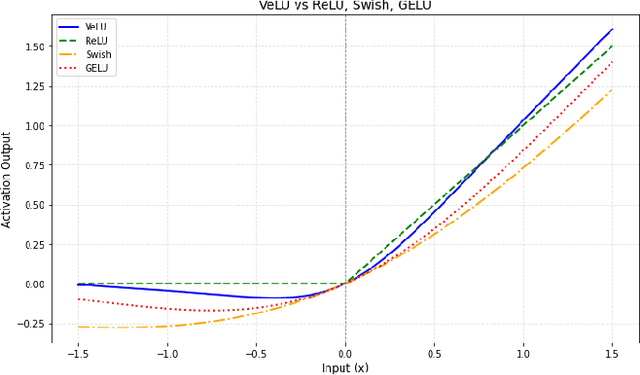
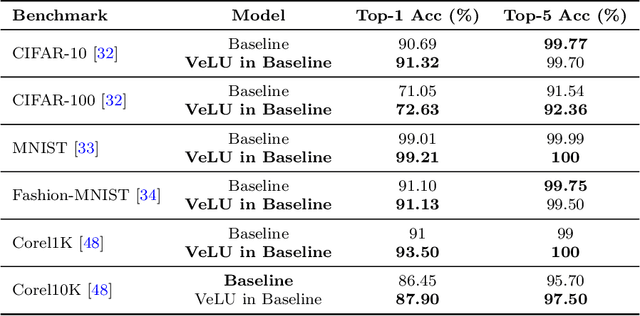
Activation functions are fundamental in deep neural networks and directly impact gradient flow, optimization stability, and generalization. Although ReLU remains standard because of its simplicity, it suffers from vanishing gradients and lacks adaptability. Alternatives like Swish and GELU introduce smooth transitions, but fail to dynamically adjust to input statistics. We propose VeLU, a Variance-enhanced Learning Unit as an activation function that dynamically scales based on input variance by integrating ArcTan-Sin transformations and Wasserstein-2 regularization, effectively mitigating covariate shifts and stabilizing optimization. Extensive experiments on ViT_B16, VGG19, ResNet50, DenseNet121, MobileNetV2, and EfficientNetB3 confirm VeLU's superiority over ReLU, ReLU6, Swish, and GELU on six vision benchmarks. The codes of VeLU are publicly available on GitHub.
Latent Drifting in Diffusion Models for Counterfactual Medical Image Synthesis
Dec 30, 2024



Scaling by training on large datasets has been shown to enhance the quality and fidelity of image generation and manipulation with diffusion models; however, such large datasets are not always accessible in medical imaging due to cost and privacy issues, which contradicts one of the main applications of such models to produce synthetic samples where real data is scarce. Also, finetuning on pre-trained general models has been a challenge due to the distribution shift between the medical domain and the pre-trained models. Here, we propose Latent Drift (LD) for diffusion models that can be adopted for any fine-tuning method to mitigate the issues faced by the distribution shift or employed in inference time as a condition. Latent Drifting enables diffusion models to be conditioned for medical images fitted for the complex task of counterfactual image generation, which is crucial to investigate how parameters such as gender, age, and adding or removing diseases in a patient would alter the medical images. We evaluate our method on three public longitudinal benchmark datasets of brain MRI and chest X-rays for counterfactual image generation. Our results demonstrate significant performance gains in various scenarios when combined with different fine-tuning schemes. The source code of this work will be publicly released upon its acceptance.
Conformable Convolution for Topologically Aware Learning of Complex Anatomical Structures
Dec 29, 2024While conventional computer vision emphasizes pixel-level and feature-based objectives, medical image analysis of intricate biological structures necessitates explicit representation of their complex topological properties. Despite their successes, deep learning models often struggle to accurately capture the connectivity and continuity of fine, sometimes pixel-thin, yet critical structures due to their reliance on implicit learning from data. Such shortcomings can significantly impact the reliability of analysis results and hinder clinical decision-making. To address this challenge, we introduce Conformable Convolution, a novel convolutional layer designed to explicitly enforce topological consistency. Conformable Convolution learns adaptive kernel offsets that preferentially focus on regions of high topological significance within an image. This prioritization is guided by our proposed Topological Posterior Generator (TPG) module, which leverages persistent homology. The TPG module identifies key topological features and guides the convolutional layers by applying persistent homology to feature maps transformed into cubical complexes. Our proposed modules are architecture-agnostic, enabling them to be integrated seamlessly into various architectures. We showcase the effectiveness of our framework in the segmentation task, where preserving the interconnectedness of structures is critical. Experimental results on three diverse datasets demonstrate that our framework effectively preserves the topology in the segmentation downstream task, both quantitatively and qualitatively.
WiCV@CVPR2024: The Thirteenth Women In Computer Vision Workshop at the Annual CVPR Conference
Nov 03, 2024In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2024, organized alongside the CVPR 2024 in Seattle, Washington, United States. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a)~opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate financial burdens and d)~a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2024 workshop.
SANGRIA: Surgical Video Scene Graph Optimization for Surgical Workflow Prediction
Jul 29, 2024Graph-based holistic scene representations facilitate surgical workflow understanding and have recently demonstrated significant success. However, this task is often hindered by the limited availability of densely annotated surgical scene data. In this work, we introduce an end-to-end framework for the generation and optimization of surgical scene graphs on a downstream task. Our approach leverages the flexibility of graph-based spectral clustering and the generalization capability of foundation models to generate unsupervised scene graphs with learnable properties. We reinforce the initial spatial graph with sparse temporal connections using local matches between consecutive frames to predict temporally consistent clusters across a temporal neighborhood. By jointly optimizing the spatiotemporal relations and node features of the dynamic scene graph with the downstream task of phase segmentation, we address the costly and annotation-burdensome task of semantic scene comprehension and scene graph generation in surgical videos using only weak surgical phase labels. Further, by incorporating effective intermediate scene representation disentanglement steps within the pipeline, our solution outperforms the SOTA on the CATARACTS dataset by 8% accuracy and 10% F1 score in surgical workflow recognition
PRISM: Progressive Restoration for Scene Graph-based Image Manipulation
Nov 03, 2023
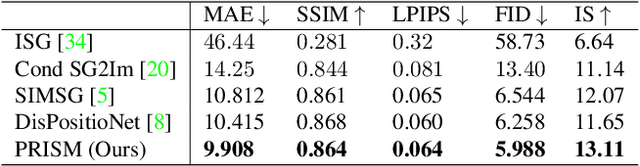
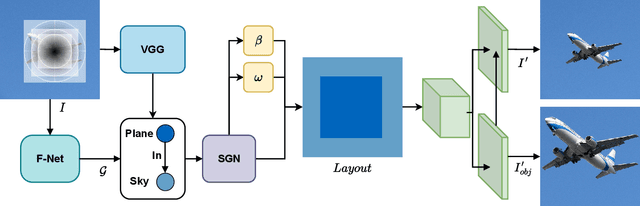

Scene graphs have emerged as accurate descriptive priors for image generation and manipulation tasks, however, their complexity and diversity of the shapes and relations of objects in data make it challenging to incorporate them into the models and generate high-quality results. To address these challenges, we propose PRISM, a novel progressive multi-head image manipulation approach to improve the accuracy and quality of the manipulated regions in the scene. Our image manipulation framework is trained using an end-to-end denoising masked reconstruction proxy task, where the masked regions are progressively unmasked from the outer regions to the inner part. We take advantage of the outer part of the masked area as they have a direct correlation with the context of the scene. Moreover, our multi-head architecture simultaneously generates detailed object-specific regions in addition to the entire image to produce higher-quality images. Our model outperforms the state-of-the-art methods in the semantic image manipulation task on the CLEVR and Visual Genome datasets. Our results demonstrate the potential of our approach for enhancing the quality and precision of scene graph-based image manipulation.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023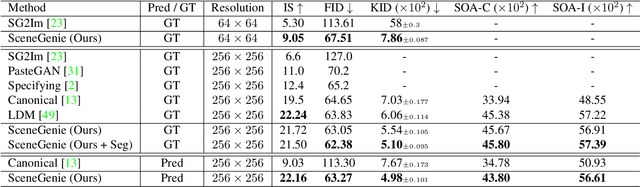
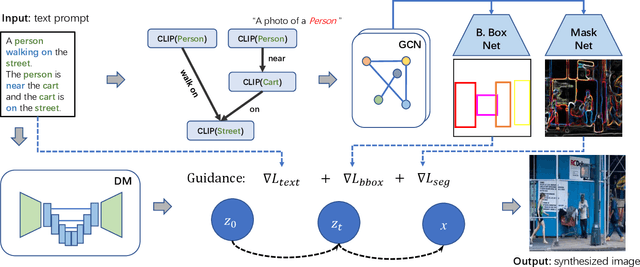
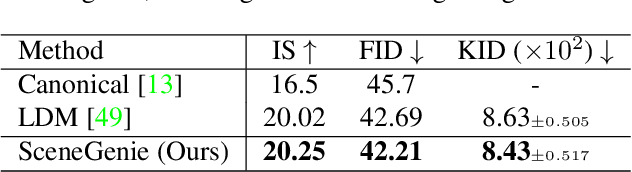
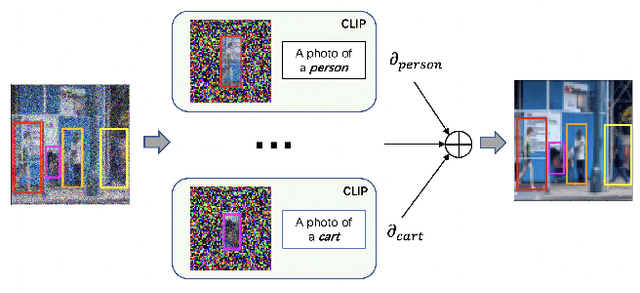
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.