 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedOpenClaw: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies
Mar 25, 2026Currently, evaluating vision-language models (VLMs) in medical imaging tasks oversimplifies clinical reality by relying on pre-selected 2D images that demand significant manual labor to curate. This setup misses the core challenge of realworld diagnostics: a true clinical agent must actively navigate full 3D volumes across multiple sequences or modalities to gather evidence and ultimately support a final decision. To address this, we propose MEDOPENCLAW, an auditable runtime designed to let VLMs operate dynamically within standard medical tools or viewers (e.g., 3D Slicer). On top of this runtime, we introduce MEDFLOWBENCH, a full-study medical imaging benchmark covering multi-sequence brain MRI and lung CT/PET. It systematically evaluates medical agentic capabilities across viewer-only, tool-use, and open-method tracks. Initial results reveal a critical insight: while state-of-the-art LLMs/VLMs (e.g., Gemini 3.1 Pro and GPT-5.4) can successfully navigate the viewer to solve basic study-level tasks, their performance paradoxically degrades when given access to professional support tools due to a lack of precise spatial grounding. By bridging the gap between static-image perception and interactive clinical workflows, MEDOPENCLAW and MEDFLOWBENCH establish a reproducible foundation for developing auditable, full-study medical imaging agents.
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
Self-Discovering Interpretable Diffusion Latent Directions for Responsible Text-to-Image Generation
Nov 28, 2023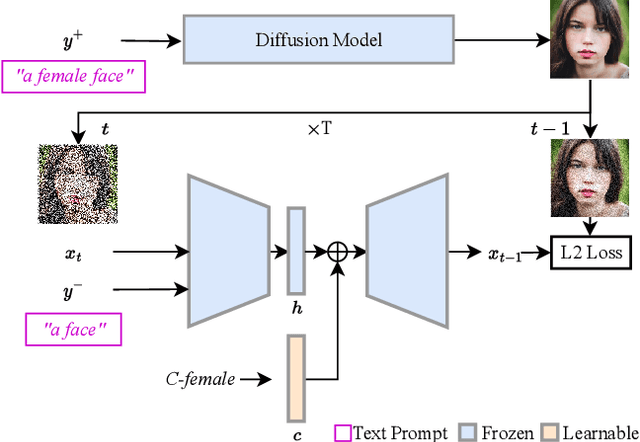
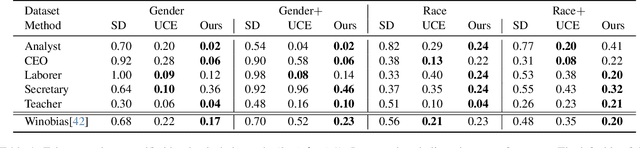
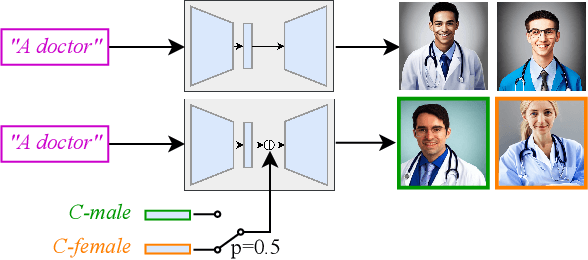

Diffusion-based models have gained significant popularity for text-to-image generation due to their exceptional image-generation capabilities. A risk with these models is the potential generation of inappropriate content, such as biased or harmful images. However, the underlying reasons for generating such undesired content from the perspective of the diffusion model's internal representation remain unclear. Previous work interprets vectors in an interpretable latent space of diffusion models as semantic concepts. However, existing approaches cannot discover directions for arbitrary concepts, such as those related to inappropriate concepts. In this work, we propose a novel self-supervised approach to find interpretable latent directions for a given concept. With the discovered vectors, we further propose a simple approach to mitigate inappropriate generation. Extensive experiments have been conducted to verify the effectiveness of our mitigation approach, namely, for fair generation, safe generation, and responsible text-enhancing generation.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023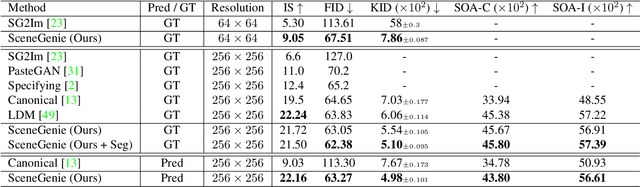
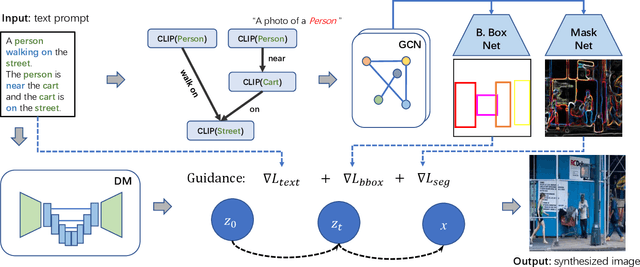
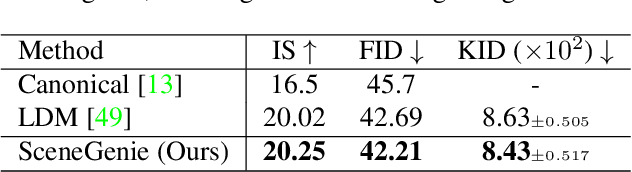
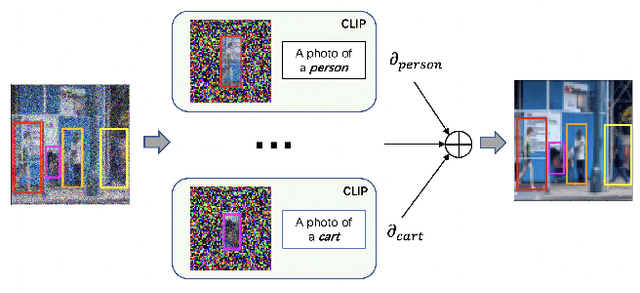
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.