 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Siamese MAE Pretraining for Longitudinal Medical Images
Dec 29, 2025Temporally aware image representations are crucial for capturing disease progression in 3D volumes of longitudinal medical datasets. However, recent state-of-the-art self-supervised learning approaches like Masked Autoencoding (MAE), despite their strong representation learning capabilities, lack temporal awareness. In this paper, we propose STAMP (Stochastic Temporal Autoencoder with Masked Pretraining), a Siamese MAE framework that encodes temporal information through a stochastic process by conditioning on the time difference between the 2 input volumes. Unlike deterministic Siamese approaches, which compare scans from different time points but fail to account for the inherent uncertainty in disease evolution, STAMP learns temporal dynamics stochastically by reframing the MAE reconstruction loss as a conditional variational inference objective. We evaluated STAMP on two OCT and one MRI datasets with multiple visits per patient. STAMP pretrained ViT models outperformed both existing temporal MAE methods and foundation models on different late stage Age-Related Macular Degeneration and Alzheimer's Disease progression prediction which require models to learn the underlying non-deterministic temporal dynamics of the diseases.
PSScreen V2: Partially Supervised Multiple Retinal Disease Screening
Oct 26, 2025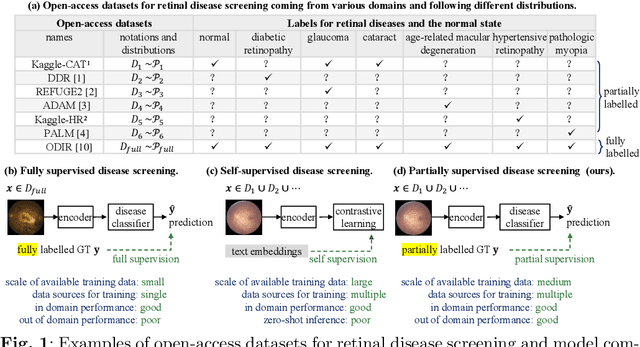
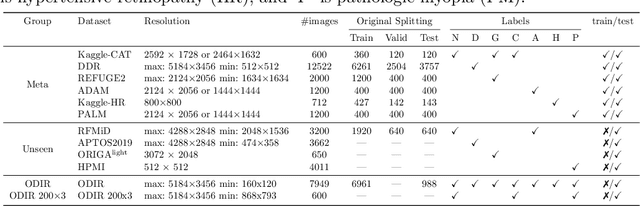
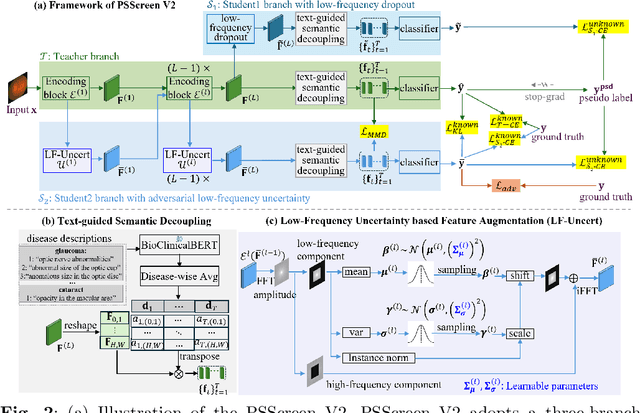
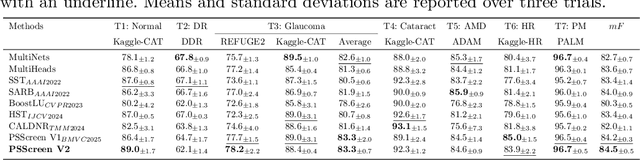
In this work, we propose PSScreen V2, a partially supervised self-training framework for multiple retinal disease screening. Unlike previous methods that rely on fully labelled or single-domain datasets, PSScreen V2 is designed to learn from multiple partially labelled datasets with different distributions, addressing both label absence and domain shift challenges. To this end, PSScreen V2 adopts a three-branch architecture with one teacher and two student networks. The teacher branch generates pseudo labels from weakly augmented images to address missing labels, while the two student branches introduce novel feature augmentation strategies: Low-Frequency Dropout (LF-Dropout), which enhances domain robustness by randomly discarding domain-related low-frequency components, and Low-Frequency Uncertainty (LF-Uncert), which estimates uncertain domain variability via adversarially learned Gaussian perturbations of low-frequency statistics. Extensive experiments on multiple in-domain and out-of-domain fundus datasets demonstrate that PSScreen V2 achieves state-of-the-art performance and superior domain generalization ability. Furthermore, compatibility tests with diverse backbones, including the vision foundation model DINOv2, as well as evaluations on chest X-ray datasets, highlight the universality and adaptability of the proposed framework. The codes are available at https://github.com/boyiZheng99/PSScreen_V2.
PiPViT: Patch-based Visual Interpretable Prototypes for Retinal Image Analysis
Jun 12, 2025Background and Objective: Prototype-based methods improve interpretability by learning fine-grained part-prototypes; however, their visualization in the input pixel space is not always consistent with human-understandable biomarkers. In addition, well-known prototype-based approaches typically learn extremely granular prototypes that are less interpretable in medical imaging, where both the presence and extent of biomarkers and lesions are critical. Methods: To address these challenges, we propose PiPViT (Patch-based Visual Interpretable Prototypes), an inherently interpretable prototypical model for image recognition. Leveraging a vision transformer (ViT), PiPViT captures long-range dependencies among patches to learn robust, human-interpretable prototypes that approximate lesion extent only using image-level labels. Additionally, PiPViT benefits from contrastive learning and multi-resolution input processing, which enables effective localization of biomarkers across scales. Results: We evaluated PiPViT on retinal OCT image classification across four datasets, where it achieved competitive quantitative performance compared to state-of-the-art methods while delivering more meaningful explanations. Moreover, quantitative evaluation on a hold-out test set confirms that the learned prototypes are semantically and clinically relevant. We believe PiPViT can transparently explain its decisions and assist clinicians in understanding diagnostic outcomes. Github page: https://github.com/marziehoghbaie/PiPViT
MIRAGE: Multimodal foundation model and benchmark for comprehensive retinal OCT image analysis
Jun 11, 2025Artificial intelligence (AI) has become a fundamental tool for assisting clinicians in analyzing ophthalmic images, such as optical coherence tomography (OCT). However, developing AI models often requires extensive annotation, and existing models tend to underperform on independent, unseen data. Foundation models (FMs), large AI models trained on vast unlabeled datasets, have shown promise in overcoming these challenges. Nonetheless, available FMs for ophthalmology lack extensive validation, especially for segmentation tasks, and focus on a single imaging modality. In this context, we propose MIRAGE, a novel multimodal FM for the analysis of OCT and scanning laser ophthalmoscopy (SLO) images. Additionally, we propose a new evaluation benchmark with OCT/SLO classification and segmentation tasks. The comparison with general and specialized FMs and segmentation methods shows the superiority of MIRAGE in both types of tasks, highlighting its suitability as a basis for the development of robust AI systems for retinal OCT image analysis. Both MIRAGE and the evaluation benchmark are publicly available: https://github.com/j-morano/MIRAGE.
Automatic detection and prediction of nAMD activity change in retinal OCT using Siamese networks and Wasserstein Distance for ordinality
Jan 24, 2025Neovascular age-related macular degeneration (nAMD) is a leading cause of vision loss among older adults, where disease activity detection and progression prediction are critical for nAMD management in terms of timely drug administration and improving patient outcomes. Recent advancements in deep learning offer a promising solution for predicting changes in AMD from optical coherence tomography (OCT) retinal volumes. In this work, we proposed deep learning models for the two tasks of the public MARIO Challenge at MICCAI 2024, designed to detect and forecast changes in nAMD severity with longitudinal retinal OCT. For the first task, we employ a Vision Transformer (ViT) based Siamese Network to detect changes in AMD severity by comparing scan embeddings of a patient from different time points. To train a model to forecast the change after 3 months, we exploit, for the first time, an Earth Mover (Wasserstein) Distance-based loss to harness the ordinal relation within the severity change classes. Both models ranked high on the preliminary leaderboard, demonstrating that their predictive capabilities could facilitate nAMD treatment management.
Forecasting Disease Progression with Parallel Hyperplanes in Longitudinal Retinal OCT
Sep 30, 2024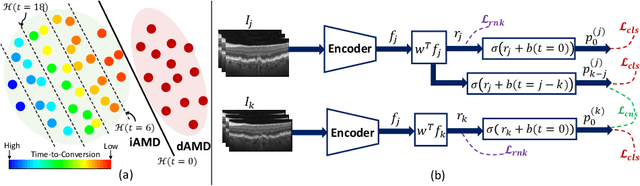
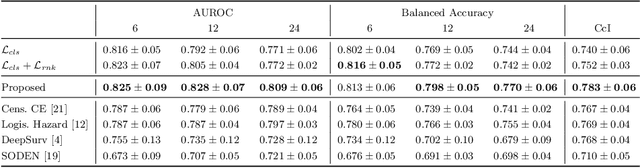
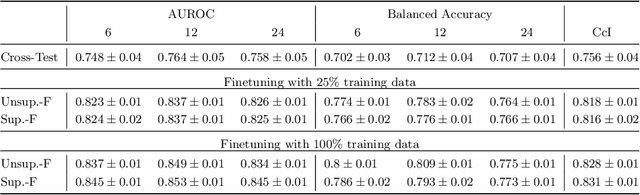
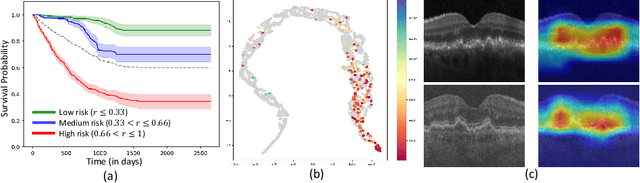
Predicting future disease progression risk from medical images is challenging due to patient heterogeneity, and subtle or unknown imaging biomarkers. Moreover, deep learning (DL) methods for survival analysis are susceptible to image domain shifts across scanners. We tackle these issues in the task of predicting late dry Age-related Macular Degeneration (dAMD) onset from retinal OCT scans. We propose a novel DL method for survival prediction to jointly predict from the current scan a risk score, inversely related to time-to-conversion, and the probability of conversion within a time interval $t$. It uses a family of parallel hyperplanes generated by parameterizing the bias term as a function of $t$. In addition, we develop unsupervised losses based on intra-subject image pairs to ensure that risk scores increase over time and that future conversion predictions are consistent with AMD stage prediction using actual scans of future visits. Such losses enable data-efficient fine-tuning of the trained model on new unlabeled datasets acquired with a different scanner. Extensive evaluation on two large datasets acquired with different scanners resulted in a mean AUROCs of 0.82 for Dataset-1 and 0.83 for Dataset-2, across prediction intervals of 6,12 and 24 months.
Specialist vision-language models for clinical ophthalmology
Jul 11, 2024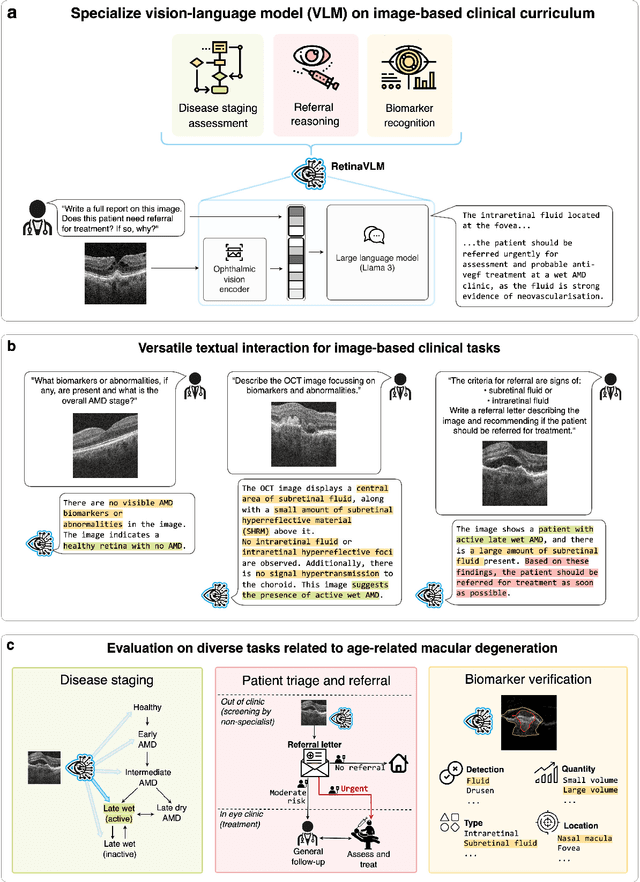

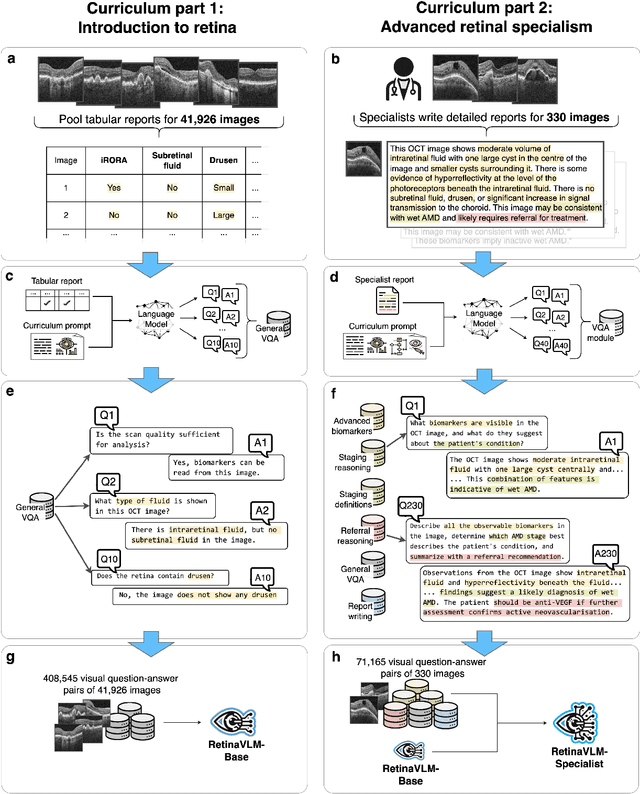

Clinicians spend a significant amount of time reviewing medical images and transcribing their findings regarding patient diagnosis, referral and treatment in text form. Vision-language models (VLMs), which automatically interpret images and summarize their findings as text, have enormous potential to alleviate clinical workloads and increase patient access to high-quality medical care. While foundational models have stirred considerable interest in the medical community, it is unclear whether their general capabilities translate to real-world clinical utility. In this work, we show that foundation VLMs markedly underperform compared to practicing ophthalmologists on specialist tasks crucial to the care of patients with age-related macular degeneration (AMD). To address this, we initially identified the essential capabilities required for image-based clinical decision-making, and then developed a curriculum to selectively train VLMs in these skills. The resulting model, RetinaVLM, can be instructed to write reports that significantly outperform those written by leading foundation medical VLMs in disease staging (F1 score of 0.63 vs. 0.11) and patient referral (0.67 vs. 0.39), and approaches the diagnostic performance of junior ophthalmologists (who achieve 0.77 and 0.78 on the respective tasks). Furthermore, in a reader study involving two senior ophthalmologists with up to 32 years of experience, RetinaVLM's reports were found to be similarly correct (78.6% vs. 82.1%) and complete (both 78.6%) as reports written by junior ophthalmologists with up to 10 years of experience. These results demonstrate that our curriculum-based approach provides a blueprint for specializing generalist foundation medical VLMs to handle real-world clinical tasks.
Time-Equivariant Contrastive Learning for Degenerative Disease Progression in Retinal OCT
May 15, 2024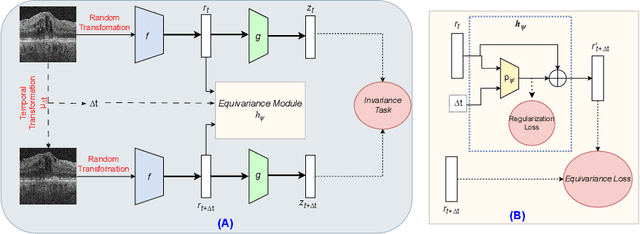
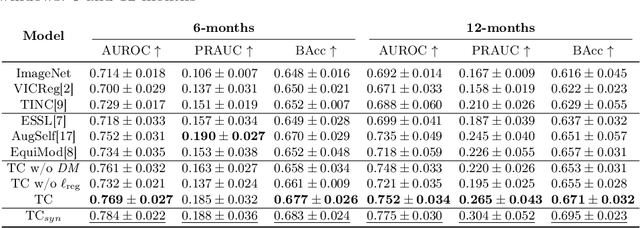
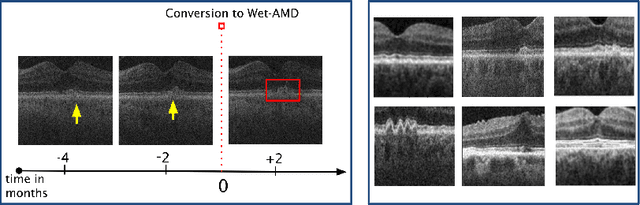
Contrastive pretraining provides robust representations by ensuring their invariance to different image transformations while simultaneously preventing representational collapse. Equivariant contrastive learning, on the other hand, provides representations sensitive to specific image transformations while remaining invariant to others. By introducing equivariance to time-induced transformations, such as disease-related anatomical changes in longitudinal imaging, the model can effectively capture such changes in the representation space. In this work, we pro-pose a Time-equivariant Contrastive Learning (TC) method. First, an encoder embeds two unlabeled scans from different time points of the same patient into the representation space. Next, a temporal equivariance module is trained to predict the representation of a later visit based on the representation from one of the previous visits and the corresponding time interval with a novel regularization loss term while preserving the invariance property to irrelevant image transformations. On a large longitudinal dataset, our model clearly outperforms existing equivariant contrastive methods in predicting progression from intermediate age-related macular degeneration (AMD) to advanced wet-AMD within a specified time-window.
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
RRWNet: Recursive Refinement Network for Effective Retinal Artery/Vein Segmentation and Classification
Feb 05, 2024



The caliber and configuration of retinal blood vessels serve as important biomarkers for various diseases and medical conditions. A thorough analysis of the retinal vasculature requires the segmentation of blood vessels and their classification into arteries and veins, which is typically performed on color fundus images obtained by retinography, a widely used imaging technique. Nonetheless, manually performing these tasks is labor-intensive and prone to human error. Various automated methods have been proposed to address this problem. However, the current state of art in artery/vein segmentation and classification faces challenges due to manifest classification errors that affect the topological consistency of segmentation maps. This study presents an innovative end-to-end framework, RRWNet, designed to recursively refine semantic segmentation maps and correct manifest classification errors. The framework consists of a fully convolutional neural network with a Base subnetwork that generates base segmentation maps from input images, and a Recursive Refinement subnetwork that iteratively and recursively improves these maps. Evaluation on public datasets demonstrates the state-of-the-art performance of the proposed method, yielding more topologically consistent segmentation maps with fewer manifest classification errors than existing approaches. In addition, the Recursive Refinement module proves effective in post-processing segmentation maps from other methods, automatically correcting classification errors and improving topological consistency. The model code, weights, and predictions are publicly available at https://github.com/j-morano/rrwnet.