 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiPViT: Patch-based Visual Interpretable Prototypes for Retinal Image Analysis
Jun 12, 2025



Background and Objective: Prototype-based methods improve interpretability by learning fine-grained part-prototypes; however, their visualization in the input pixel space is not always consistent with human-understandable biomarkers. In addition, well-known prototype-based approaches typically learn extremely granular prototypes that are less interpretable in medical imaging, where both the presence and extent of biomarkers and lesions are critical. Methods: To address these challenges, we propose PiPViT (Patch-based Visual Interpretable Prototypes), an inherently interpretable prototypical model for image recognition. Leveraging a vision transformer (ViT), PiPViT captures long-range dependencies among patches to learn robust, human-interpretable prototypes that approximate lesion extent only using image-level labels. Additionally, PiPViT benefits from contrastive learning and multi-resolution input processing, which enables effective localization of biomarkers across scales. Results: We evaluated PiPViT on retinal OCT image classification across four datasets, where it achieved competitive quantitative performance compared to state-of-the-art methods while delivering more meaningful explanations. Moreover, quantitative evaluation on a hold-out test set confirms that the learned prototypes are semantically and clinically relevant. We believe PiPViT can transparently explain its decisions and assist clinicians in understanding diagnostic outcomes. Github page: https://github.com/marziehoghbaie/PiPViT
MIRAGE: Multimodal foundation model and benchmark for comprehensive retinal OCT image analysis
Jun 11, 2025Artificial intelligence (AI) has become a fundamental tool for assisting clinicians in analyzing ophthalmic images, such as optical coherence tomography (OCT). However, developing AI models often requires extensive annotation, and existing models tend to underperform on independent, unseen data. Foundation models (FMs), large AI models trained on vast unlabeled datasets, have shown promise in overcoming these challenges. Nonetheless, available FMs for ophthalmology lack extensive validation, especially for segmentation tasks, and focus on a single imaging modality. In this context, we propose MIRAGE, a novel multimodal FM for the analysis of OCT and scanning laser ophthalmoscopy (SLO) images. Additionally, we propose a new evaluation benchmark with OCT/SLO classification and segmentation tasks. The comparison with general and specialized FMs and segmentation methods shows the superiority of MIRAGE in both types of tasks, highlighting its suitability as a basis for the development of robust AI systems for retinal OCT image analysis. Both MIRAGE and the evaluation benchmark are publicly available: https://github.com/j-morano/MIRAGE.
Automatic detection and prediction of nAMD activity change in retinal OCT using Siamese networks and Wasserstein Distance for ordinality
Jan 24, 2025Neovascular age-related macular degeneration (nAMD) is a leading cause of vision loss among older adults, where disease activity detection and progression prediction are critical for nAMD management in terms of timely drug administration and improving patient outcomes. Recent advancements in deep learning offer a promising solution for predicting changes in AMD from optical coherence tomography (OCT) retinal volumes. In this work, we proposed deep learning models for the two tasks of the public MARIO Challenge at MICCAI 2024, designed to detect and forecast changes in nAMD severity with longitudinal retinal OCT. For the first task, we employ a Vision Transformer (ViT) based Siamese Network to detect changes in AMD severity by comparing scan embeddings of a patient from different time points. To train a model to forecast the change after 3 months, we exploit, for the first time, an Earth Mover (Wasserstein) Distance-based loss to harness the ordinal relation within the severity change classes. Both models ranked high on the preliminary leaderboard, demonstrating that their predictive capabilities could facilitate nAMD treatment management.
Pretrained Deep 2.5D Models for Efficient Predictive Modeling from Retinal OCT
Jul 25, 2023In the field of medical imaging, 3D deep learning models play a crucial role in building powerful predictive models of disease progression. However, the size of these models presents significant challenges, both in terms of computational resources and data requirements. Moreover, achieving high-quality pretraining of 3D models proves to be even more challenging. To address these issues, hybrid 2.5D approaches provide an effective solution for utilizing 3D volumetric data efficiently using 2D models. Combining 2D and 3D techniques offers a promising avenue for optimizing performance while minimizing memory requirements. In this paper, we explore 2.5D architectures based on a combination of convolutional neural networks (CNNs), long short-term memory (LSTM), and Transformers. In addition, leveraging the benefits of recent non-contrastive pretraining approaches in 2D, we enhanced the performance and data efficiency of 2.5D techniques even further. We demonstrate the effectiveness of architectures and associated pretraining on a task of predicting progression to wet age-related macular degeneration (AMD) within a six-month period on two large longitudinal OCT datasets.
Transformer-based end-to-end classification of variable-length volumetric data
Jul 21, 2023



The automatic classification of 3D medical data is memory-intensive. Also, variations in the number of slices between samples is common. Na\"ive solutions such as subsampling can solve these problems, but at the cost of potentially eliminating relevant diagnosis information. Transformers have shown promising performance for sequential data analysis. However, their application for long sequences is data, computationally, and memory demanding. In this paper, we propose an end-to-end Transformer-based framework that allows to classify volumetric data of variable length in an efficient fashion. Particularly, by randomizing the input volume-wise resolution(#slices) during training, we enhance the capacity of the learnable positional embedding assigned to each volume slice. Consequently, the accumulated positional information in each positional embedding can be generalized to the neighbouring slices, even for high-resolution volumes at the test time. By doing so, the model will be more robust to variable volume length and amenable to different computational budgets. We evaluated the proposed approach in retinal OCT volume classification and achieved 21.96% average improvement in balanced accuracy on a 9-class diagnostic task, compared to state-of-the-art video transformers. Our findings show that varying the volume-wise resolution of the input during training results in more informative volume representation as compared to training with fixed number of slices per volume.
Deep Learning meets Liveness Detection: Recent Advancements and Challenges
Dec 29, 2021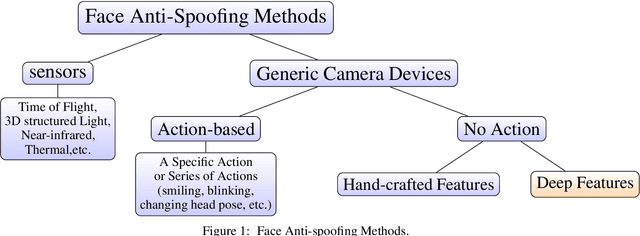
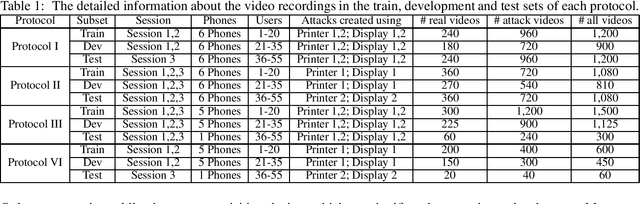
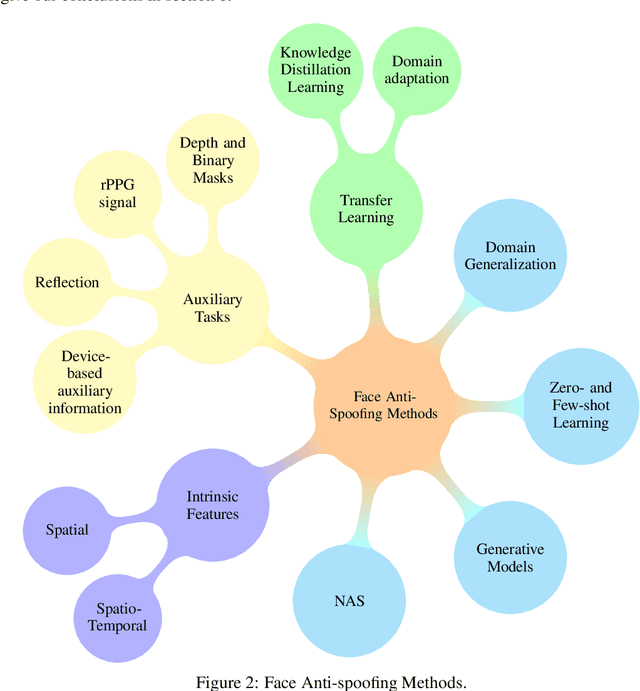
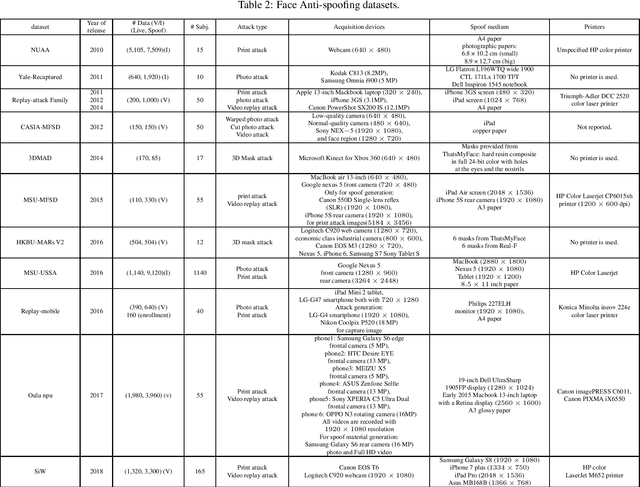
Facial biometrics has been recently received tremendous attention as a convenient replacement for traditional authentication systems. Consequently, detecting malicious attempts has found great significance, leading to extensive studies in face anti-spoofing~(FAS),i.e., face presentation attack detection. Deep feature learning and techniques, as opposed to hand-crafted features, have promised a dramatic increase in the FAS systems' accuracy, tackling the key challenges of materializing the real-world application of such systems. Hence, a new research area dealing with the development of more generalized as well as accurate models is increasingly attracting the attention of the research community and industry. In this paper, we present a comprehensive survey on the literature related to deep-feature-based FAS methods since 2017. To shed light on this topic, a semantic taxonomy based on various features and learning methodologies is represented. Further, we cover predominant public datasets for FAS in chronological order, their evolutional progress, and the evaluation criteria (both intra-dataset and inter-dataset). Finally, we discuss the open research challenges and future directions.
Advances and Challenges in Deep Lip Reading
Oct 15, 2021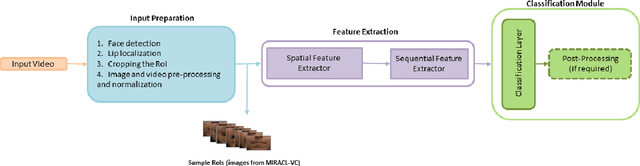
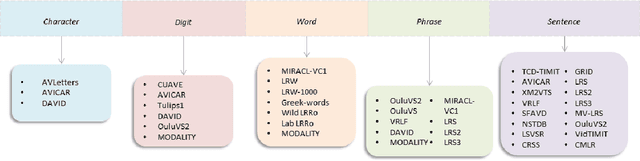
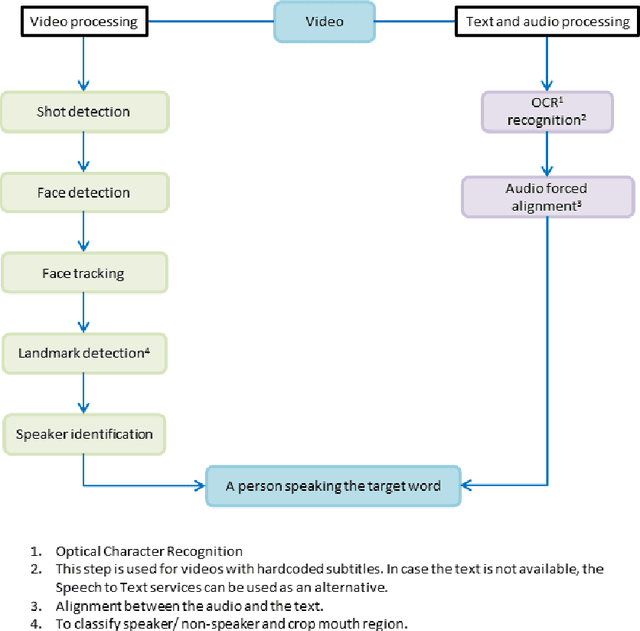
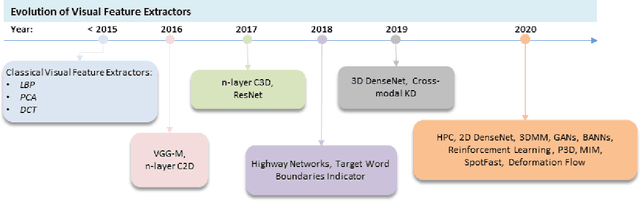
Driven by deep learning techniques and large-scale datasets, recent years have witnessed a paradigm shift in automatic lip reading. While the main thrust of Visual Speech Recognition (VSR) was improving accuracy of Audio Speech Recognition systems, other potential applications, such as biometric identification, and the promised gains of VSR systems, have motivated extensive efforts on developing the lip reading technology. This paper provides a comprehensive survey of the state-of-the-art deep learning based VSR research with a focus on data challenges, task-specific complications, and the corresponding solutions. Advancements in these directions will expedite the transformation of silent speech interface from theory to practice. We also discuss the main modules of a VSR pipeline and the influential datasets. Finally, we introduce some typical VSR application concerns and impediments to real-world scenarios as well as future research directions.