 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPPO: Contrastive Perception for Vision Language Policy Optimization
Jan 01, 2026We introduce CPPO, a Contrastive Perception Policy Optimization method for finetuning vision-language models (VLMs). While reinforcement learning (RL) has advanced reasoning in language models, extending it to multimodal reasoning requires improving both the perception and reasoning aspects. Prior works tackle this challenge mainly with explicit perception rewards, but disentangling perception tokens from reasoning tokens is difficult, requiring extra LLMs, ground-truth data, forced separation of perception from reasoning by policy model, or applying rewards indiscriminately to all output tokens. CPPO addresses this problem by detecting perception tokens via entropy shifts in the model outputs under perturbed input images. CPPO then extends the RL objective function with a Contrastive Perception Loss (CPL) that enforces consistency under information-preserving perturbations and sensitivity under information-removing ones. Experiments show that CPPO surpasses previous perception-rewarding methods, while avoiding extra models, making training more efficient and scalable.
OAM-Assisted Self-Healing Is Directional, Proportional and Persistent
Apr 02, 2025



In this paper we demonstrate the postulated mechanism of self-healing specifically due to orbital-angular-momentum (OAM) in radio vortex beams having equal beam-widths. In previous work we experimentally demonstrated self-healing effects in OAM beams at 28 GHz and postulated a theoretical mechanism to account for them. In this work we further characterize the OAM self-healing mechanism theoretically and confirm those characteristics with systematic and controlled experimental measurements on a 28 GHz outdoor link. Specifically, we find that the OAM self-healing mechanism is an additional self-healing mechanism in structured electromagnetic beams which is directional with respect to the displacement of an obstruction relative to the beam axis. We also confirm our previous findings that the amount of OAM self-healing is proportional to the OAM order, and additionally find that it persists beyond the focusing region into the far field. As such, OAM-assisted self-healing brings an advantage over other so-called non-diffracting beams both in terms of the minimum distance for onset of self-healing and the amount of self-healing obtainable. We relate our findings by extending theoretical models in the literature and develop a unifying electromagnetic analysis to account for self-healing of OAM-bearing non-diffracting beams more rigorously.
CASP: Compression of Large Multimodal Models Based on Attention Sparsity
Mar 07, 2025



In this work, we propose an extreme compression technique for Large Multimodal Models (LMMs). While previous studies have explored quantization as an efficient post-training compression method for Large Language Models (LLMs), low-bit compression for multimodal models remains under-explored. The redundant nature of inputs in multimodal models results in a highly sparse attention matrix. We theoretically and experimentally demonstrate that the attention matrix's sparsity bounds the compression error of the Query and Key weight matrices. Based on this, we introduce CASP, a model compression technique for LMMs. Our approach performs a data-aware low-rank decomposition on the Query and Key weight matrix, followed by quantization across all layers based on an optimal bit allocation process. CASP is compatible with any quantization technique and enhances state-of-the-art 2-bit quantization methods (AQLM and QuIP#) by an average of 21% on image- and video-language benchmarks.
DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models
Mar 04, 2025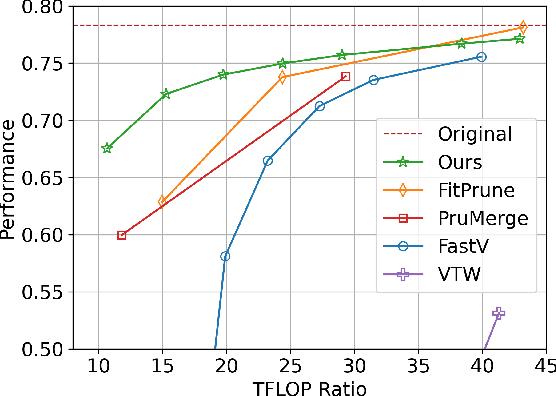
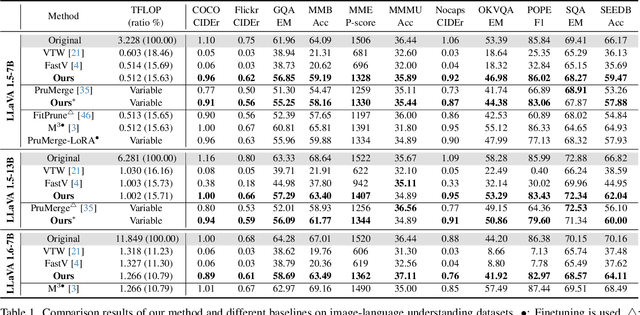
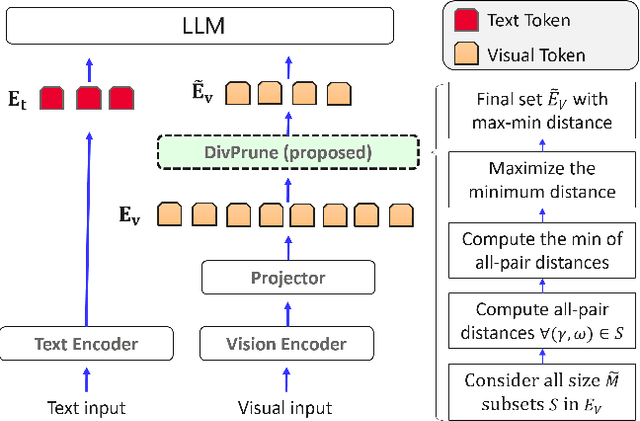

Large Multimodal Models (LMMs) have emerged as powerful models capable of understanding various data modalities, including text, images, and videos. LMMs encode both text and visual data into tokens that are then combined and processed by an integrated Large Language Model (LLM). Including visual tokens substantially increases the total token count, often by thousands. The increased input length for LLM significantly raises the complexity of inference, resulting in high latency in LMMs. To address this issue, token pruning methods, which remove part of the visual tokens, are proposed. The existing token pruning methods either require extensive calibration and fine-tuning or rely on suboptimal importance metrics which results in increased redundancy among the retained tokens. In this paper, we first formulate token pruning as Max-Min Diversity Problem (MMDP) where the goal is to select a subset such that the diversity among the selected {tokens} is maximized. Then, we solve the MMDP to obtain the selected subset and prune the rest. The proposed method, DivPrune, reduces redundancy and achieves the highest diversity of the selected tokens. By ensuring high diversity, the selected tokens better represent the original tokens, enabling effective performance even at high pruning ratios without requiring fine-tuning. Extensive experiments with various LMMs show that DivPrune achieves state-of-the-art accuracy over 16 image- and video-language datasets. Additionally, DivPrune reduces both the end-to-end latency and GPU memory usage for the tested models. The code is available $\href{https://github.com/vbdi/divprune}{\text{here}}$.
Drug-Target Interaction/Affinity Prediction: Deep Learning Models and Advances Review
Feb 21, 2025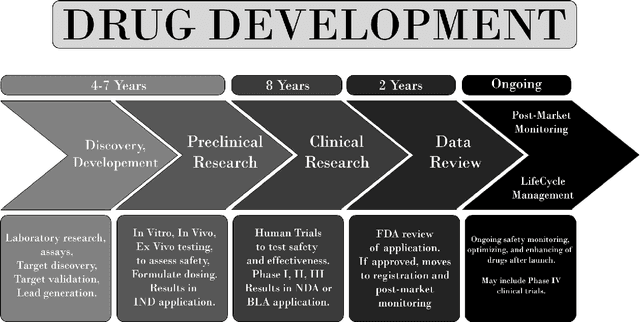
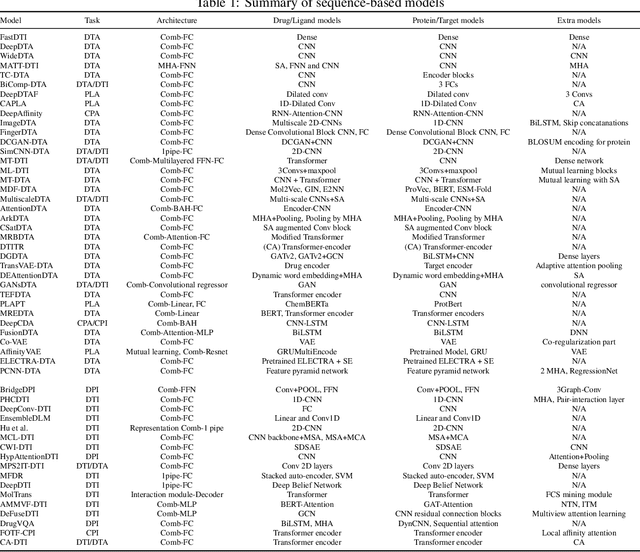
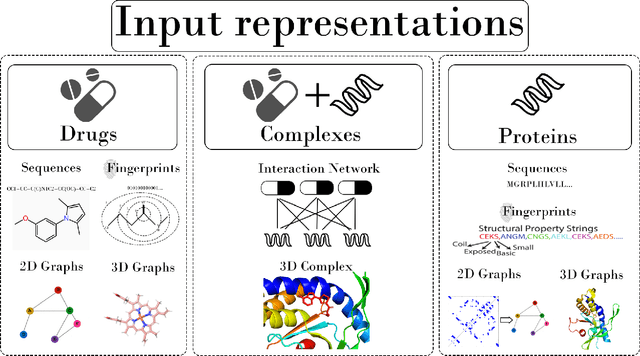
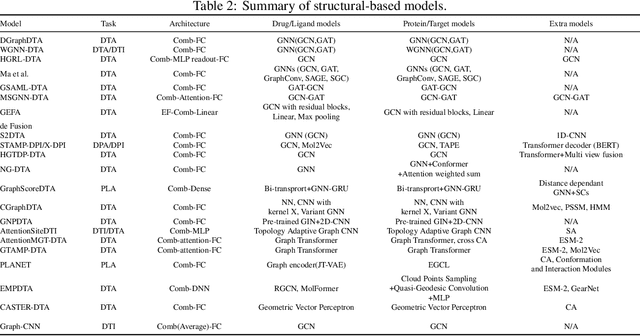
Drug discovery remains a slow and expensive process that involves many steps, from detecting the target structure to obtaining approval from the Food and Drug Administration (FDA), and is often riddled with safety concerns. Accurate prediction of how drugs interact with their targets and the development of new drugs by using better methods and technologies have immense potential to speed up this process, ultimately leading to faster delivery of life-saving medications. Traditional methods used for drug-target interaction prediction show limitations, particularly in capturing complex relationships between drugs and their targets. As an outcome, deep learning models have been presented to overcome the challenges of interaction prediction through their precise and efficient end results. By outlining promising research avenues and models, each with a different solution but similar to the problem, this paper aims to give researchers a better idea of methods for even more accurate and efficient prediction of drug-target interaction, ultimately accelerating the development of more effective drugs. A total of 180 prediction methods for drug-target interactions were analyzed throughout the period spanning 2016 to 2025 using different frameworks based on machine learning, mainly deep learning and graph neural networks. Additionally, this paper discusses the novelty, architecture, and input representation of these models.
Task-Agnostic Language Model Watermarking via High Entropy Passthrough Layers
Dec 17, 2024In the era of costly pre-training of large language models, ensuring the intellectual property rights of model owners, and insuring that said models are responsibly deployed, is becoming increasingly important. To this end, we propose model watermarking via passthrough layers, which are added to existing pre-trained networks and trained using a self-supervised loss such that the model produces high-entropy output when prompted with a unique private key, and acts normally otherwise. Unlike existing model watermarking methods, our method is fully task-agnostic, and can be applied to both classification and sequence-to-sequence tasks without requiring advanced access to downstream fine-tuning datasets. We evaluate the proposed passthrough layers on a wide range of downstream tasks, and show experimentally our watermarking method achieves a near-perfect watermark extraction accuracy and false-positive rate in most cases without damaging original model performance. Additionally, we show our method is robust to both downstream fine-tuning, fine-pruning, and layer removal attacks, and can be trained in a fraction of the time required to train the original model. Code is available in the paper.
Towards Secure and Usable 3D Assets: A Novel Framework for Automatic Visible Watermarking
Aug 31, 2024



3D models, particularly AI-generated ones, have witnessed a recent surge across various industries such as entertainment. Hence, there is an alarming need to protect the intellectual property and avoid the misuse of these valuable assets. As a viable solution to address these concerns, we rigorously define the novel task of automated 3D visible watermarking in terms of two competing aspects: watermark quality and asset utility. Moreover, we propose a method of embedding visible watermarks that automatically determines the right location, orientation, and number of watermarks to be placed on arbitrary 3D assets for high watermark quality and asset utility. Our method is based on a novel rigid-body optimization that uses back-propagation to automatically learn transforms for ideal watermark placement. In addition, we propose a novel curvature-matching method for fusing the watermark into the 3D model that further improves readability and security. Finally, we provide a detailed experimental analysis on two benchmark 3D datasets validating the superior performance of our approach in comparison to baselines. Code and demo are available.
LaWa: Using Latent Space for In-Generation Image Watermarking
Aug 11, 2024
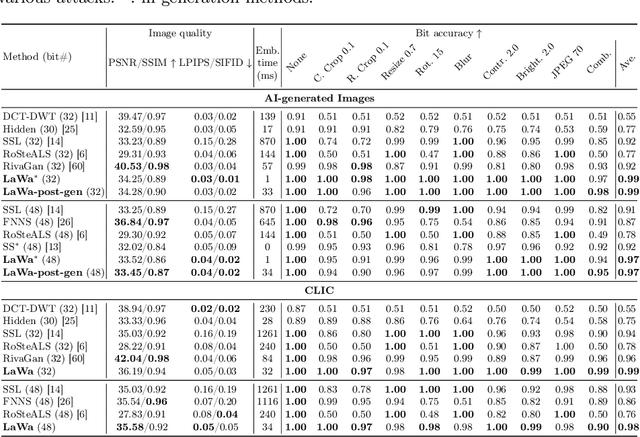
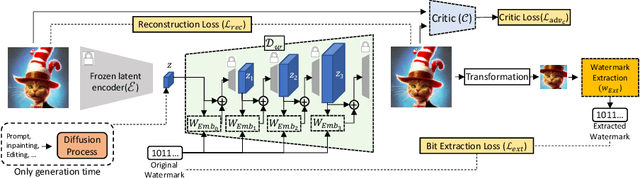

With generative models producing high quality images that are indistinguishable from real ones, there is growing concern regarding the malicious usage of AI-generated images. Imperceptible image watermarking is one viable solution towards such concerns. Prior watermarking methods map the image to a latent space for adding the watermark. Moreover, Latent Diffusion Models (LDM) generate the image in the latent space of a pre-trained autoencoder. We argue that this latent space can be used to integrate watermarking into the generation process. To this end, we present LaWa, an in-generation image watermarking method designed for LDMs. By using coarse-to-fine watermark embedding modules, LaWa modifies the latent space of pre-trained autoencoders and achieves high robustness against a wide range of image transformations while preserving perceptual quality of the image. We show that LaWa can also be used as a general image watermarking method. Through extensive experiments, we demonstrate that LaWa outperforms previous works in perceptual quality, robustness against attacks, and computational complexity, while having very low false positive rate. Code is available here.
GOLD: Generalized Knowledge Distillation via Out-of-Distribution-Guided Language Data Generation
Mar 28, 2024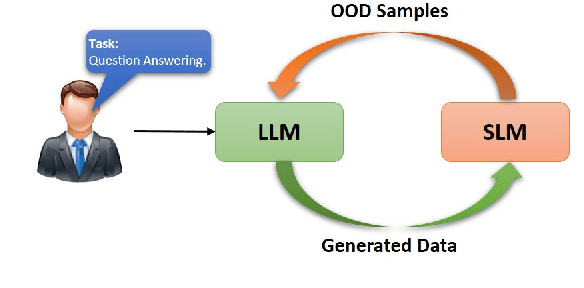

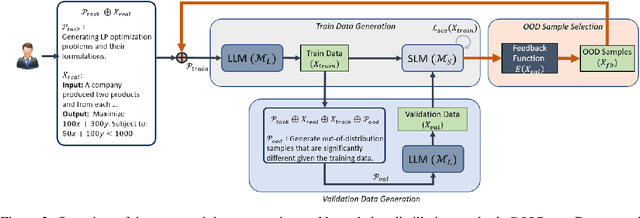
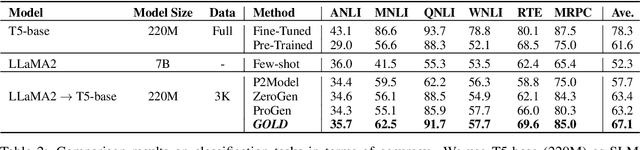
Knowledge distillation from LLMs is essential for the efficient deployment of language models. Prior works have proposed data generation using LLMs for preparing distilled models. We argue that generating data with LLMs is prone to sampling mainly from the center of original content distribution. This limitation hinders the distilled model from learning the true underlying data distribution and to forget the tails of the distributions (samples with lower probability). To this end, we propose GOLD, a task-agnostic data generation and knowledge distillation framework, which employs an iterative out-of-distribution-guided feedback mechanism for the LLM. As a result, the generated data improves the generalizability of distilled models. An energy-based OOD evaluation approach is also introduced to deal with noisy generated data. Our extensive experiments on 10 different classification and sequence-to-sequence tasks in NLP show that GOLD respectively outperforms prior arts and the LLM with an average improvement of 5% and 14%. We will also show that the proposed method is applicable to less explored and novel tasks. The code is available.
Self-Healing Effects in OAM Beams Observed on a 28 GHz Experimental Link
Feb 07, 2024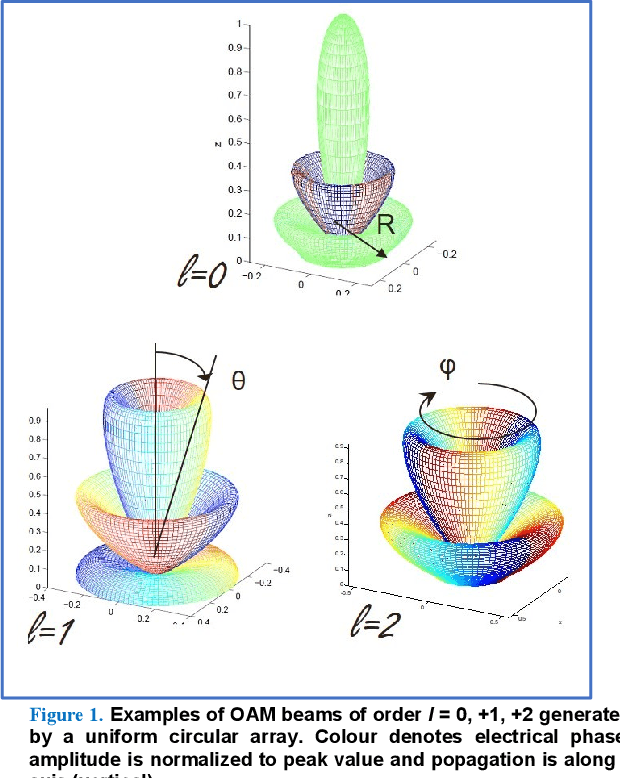
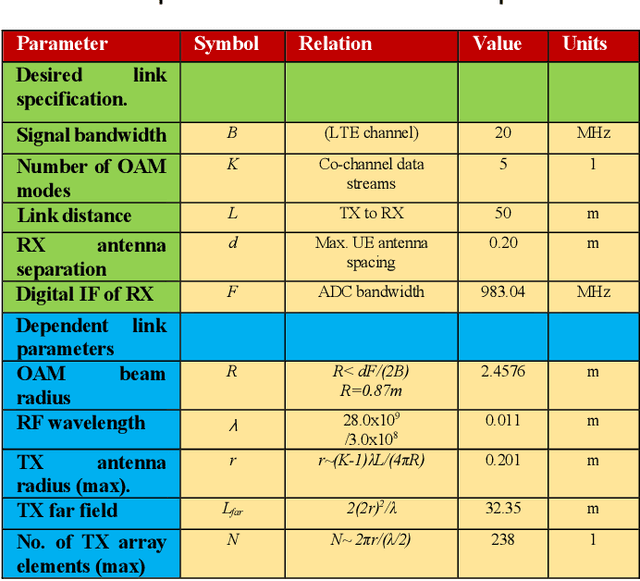

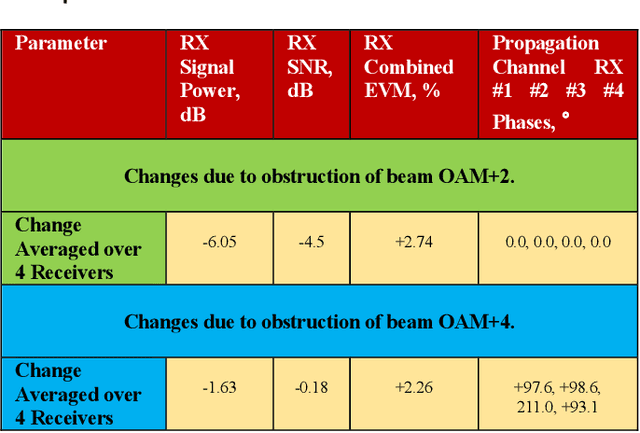
In this paper we document for the first time some of the effects of self-healing, a property of orbital-angular-momentum (OAM) or vortex beams, as observed on a millimeter-wave experimental communications link in an outdoors line-of-sight (LOS) scenario. The OAM beams have a helical phase and polarization structure and have conical amplitude shape in the far field. The Poynting vectors of the OAM beams also possess helical structures, orthogonal to the corresponding helical phase-fronts. Due to such non-planar structure in the direction orthogonal to the beam axis, OAM beams are a subset of structured light beams. Such structured beams are known to possess self-healing properties when partially obstructed along their propagation axis, especially in their near fields, resulting in partial reconstruction of their structures at larger distances along their beam axis. Various theoretical rationales have been proposed to explain, model and experimentally verify the self-healing physical effects in structured optical beams, using various types of obstructions and experimental techniques. Based on these models, we hypothesize that any self-healing observed will be greater as the OAM order increases. Here we observe the self-healing effects for the first time in structured OAM radio beams, in terms of communication signals and channel parameters rather than beam structures. We capture the effects of partial near-field obstructions of OAM beams of different orders on the communications signals and provide a physical rationale to substantiate that the self-healing effect was observed to increase with the order of OAM, agreeing with our hypothesis.