 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Perception-Distortion Trade-off with Spatial-Semantic Guided Super-Resolution
Mar 14, 2026Image super-resolution (SR) aims to reconstruct high resolution images with both high perceptual quality and low distortion, but is fundamentally limited by the perception-distortion trade-off. GAN-based SR methods reduce distortion but still struggle with realistic fine-grained textures, whereas diffusion-based approaches synthesize rich details but often deviate from the input, hallucinating structures and degrading fidelity. This tension raises a key challenge: how to exploit the powerful generative priors of diffusion models without sacrificing fidelity. To address this, we propose SpaSemSR, a spatial-semantic guided diffusion framework with two complementary guidances. First, spatial-grounded textual guidance integrates object-level spatial cues with semantic prompts, aligning textual and visual structures to reduce distortion. Second, semantic-enhanced visual guidance with a multi-encoder design and semantic degradation constraints unifies multimodal semantic priors, improving perceptual realism under severe degradations. These complementary guidances are adaptively fused into the diffusion process via spatial-semantic attention, suppressing distortion and hallucination while retaining the strengths of diffusion models. Extensive experiments on multiple benchmarks show that SpaSemSR achieves a superior perception-distortion balance, producing both realistic and faithful restorations.
Composed Vision-Language Retrieval for Skin Cancer Case Search via Joint Alignment of Global and Local Representations
Mar 10, 2026Medical image retrieval aims to identify clinically relevant lesion cases to support diagnostic decision making, education, and quality control. In practice, retrieval queries often combine a reference lesion image with textual descriptors such as dermoscopic features. We study composed vision-language retrieval for skin cancer, where each query consists of an image to text pair and the database contains biopsy-confirmed, multi-class disease cases. We propose a transformer based framework that learns hierarchical composed query representations and performs joint global-local alignment between queries and candidate images. Local alignment aggregates discriminative regions via multiple spatial attention masks, while global alignment provides holistic semantic supervision. The final similarity is computed through a convex, domain-informed weighting that emphasizes clinically salient local evidence while preserving global consistency. Experiments on the public Derm7pt dataset demonstrate consistent improvements over state-of-the-art methods. The proposed framework enables efficient access to relevant medical records and supports practical clinical deployment.
AdaIAT: Adaptively Increasing Attention to Generated Text to Alleviate Hallucinations in LVLM
Mar 05, 2026Hallucination has been a significant impediment to the development and application of current Large Vision-Language Models (LVLMs). To mitigate hallucinations, one intuitive and effective way is to directly increase attention weights to image tokens during inference. Although this effectively reduces the hallucination rate, it often induces repetitive descriptions. To address this, we first conduct an analysis of attention patterns and reveal that real object tokens tend to assign higher attention to the generated text than hallucinated ones. This inspires us to leverage the generated text, which contains instruction-related visual information and contextual knowledge, to alleviate hallucinations while maintaining linguistic coherence. We therefore propose Attention to Generated Text (IAT) and demonstrate that it significantly reduces the hallucination rate while avoiding repetitive descriptions. To prevent naive amplification from impairing the inherent prediction capabilities of LVLMs, we further explore Adaptive IAT (AdaIAT) that employs a layer-wise threshold to control intervention time and fine-grained amplification magnitude tailored to the characteristics of each attention head. Both analysis and experiments demonstrate the effectiveness of AdaIAT. Results of several LVLMs show that AdaIAT effectively alleviates hallucination (reducing hallucination rates $C_S$ and $C_I$ on LLaVA-1.5 by 35.8% and 37.1%, respectively) while preserving linguistic performance and prediction capability, achieving an attractive trade-off.
AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks
Mar 12, 2025Imperceptible adversarial attacks aim to fool DNNs by adding imperceptible perturbation to the input data. Previous methods typically improve the imperceptibility of attacks by integrating common attack paradigms with specifically designed perception-based losses or the capabilities of generative models. In this paper, we propose Adversarial Attacks in Diffusion (AdvAD), a novel modeling framework distinct from existing attack paradigms. AdvAD innovatively conceptualizes attacking as a non-parametric diffusion process by theoretically exploring basic modeling approach rather than using the denoising or generation abilities of regular diffusion models requiring neural networks. At each step, much subtler yet effective adversarial guidance is crafted using only the attacked model without any additional network, which gradually leads the end of diffusion process from the original image to a desired imperceptible adversarial example. Grounded in a solid theoretical foundation of the proposed non-parametric diffusion process, AdvAD achieves high attack efficacy and imperceptibility with intrinsically lower overall perturbation strength. Additionally, an enhanced version AdvAD-X is proposed to evaluate the extreme of our novel framework under an ideal scenario. Extensive experiments demonstrate the effectiveness of the proposed AdvAD and AdvAD-X. Compared with state-of-the-art imperceptible attacks, AdvAD achieves an average of 99.9$\%$ (+17.3$\%$) ASR with 1.34 (-0.97) $l_2$ distance, 49.74 (+4.76) PSNR and 0.9971 (+0.0043) SSIM against four prevalent DNNs with three different architectures on the ImageNet-compatible dataset. Code is available at https://github.com/XianguiKang/AdvAD.
* Accept by NeurIPS 2024. Please cite this paper using the following format: J. Li, Z. He, A. Luo, J. Hu, Z. Wang, X. Kang*, "AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks", the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, Dec 9-15, 2024. Code: https://github.com/XianguiKang/AdvAD
FlexMotion: Lightweight, Physics-Aware, and Controllable Human Motion Generation
Jan 28, 2025

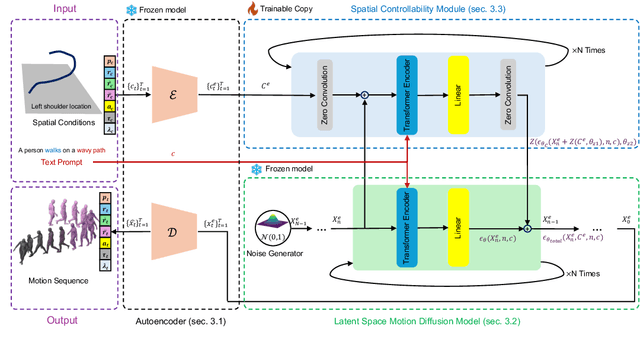

Lightweight, controllable, and physically plausible human motion synthesis is crucial for animation, virtual reality, robotics, and human-computer interaction applications. Existing methods often compromise between computational efficiency, physical realism, or spatial controllability. We propose FlexMotion, a novel framework that leverages a computationally lightweight diffusion model operating in the latent space, eliminating the need for physics simulators and enabling fast and efficient training. FlexMotion employs a multimodal pre-trained Transformer encoder-decoder, integrating joint locations, contact forces, joint actuations and muscle activations to ensure the physical plausibility of the generated motions. FlexMotion also introduces a plug-and-play module, which adds spatial controllability over a range of motion parameters (e.g., joint locations, joint actuations, contact forces, and muscle activations). Our framework achieves realistic motion generation with improved efficiency and control, setting a new benchmark for human motion synthesis. We evaluate FlexMotion on extended datasets and demonstrate its superior performance in terms of realism, physical plausibility, and controllability.
PGD-Imp: Rethinking and Unleashing Potential of Classic PGD with Dual Strategies for Imperceptible Adversarial Attacks
Dec 15, 2024



Imperceptible adversarial attacks have recently attracted increasing research interests. Existing methods typically incorporate external modules or loss terms other than a simple $l_p$-norm into the attack process to achieve imperceptibility, while we argue that such additional designs may not be necessary. In this paper, we rethink the essence of imperceptible attacks and propose two simple yet effective strategies to unleash the potential of PGD, the common and classical attack, for imperceptibility from an optimization perspective. Specifically, the Dynamic Step Size is introduced to find the optimal solution with minimal attack cost towards the decision boundary of the attacked model, and the Adaptive Early Stop strategy is adopted to reduce the redundant strength of adversarial perturbations to the minimum level. The proposed PGD-Imperceptible (PGD-Imp) attack achieves state-of-the-art results in imperceptible adversarial attacks for both untargeted and targeted scenarios. When performing untargeted attacks against ResNet-50, PGD-Imp attains 100$\%$ (+0.3$\%$) ASR, 0.89 (-1.76) $l_2$ distance, and 52.93 (+9.2) PSNR with 57s (-371s) running time, significantly outperforming existing methods.
ORB-SLAM3AB: Augmenting ORB-SLAM3 to Counteract Bumps with Optical Flow Inter-frame Matching
Nov 27, 2024



This paper proposes an enhancement to the ORB-SLAM3 algorithm, tailored for applications on rugged road surfaces. Our improved algorithm adeptly combines feature point matching with optical flow methods, capitalizing on the high robustness of optical flow in complex terrains and the high precision of feature points on smooth surfaces. By refining the inter-frame matching logic of ORB-SLAM3, we have addressed the issue of frame matching loss on uneven roads. To prevent a decrease in accuracy, an adaptive matching mechanism has been incorporated, which increases the reliance on optical flow points during periods of high vibration, thereby effectively maintaining SLAM precision. Furthermore, due to the scarcity of multi-sensor datasets suitable for environments with bumpy roads or speed bumps, we have collected LiDAR and camera data from such settings. Our enhanced algorithm, ORB-SLAM3AB, was then benchmarked against several advanced open-source SLAM algorithms that rely solely on laser or visual data. Through the analysis of Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) metrics, our results demonstrate that ORB-SLAM3AB achieves superior robustness and accuracy on rugged road surfaces.
Enhancing Adversarial Robustness via Uncertainty-Aware Distributional Adversarial Training
Nov 05, 2024

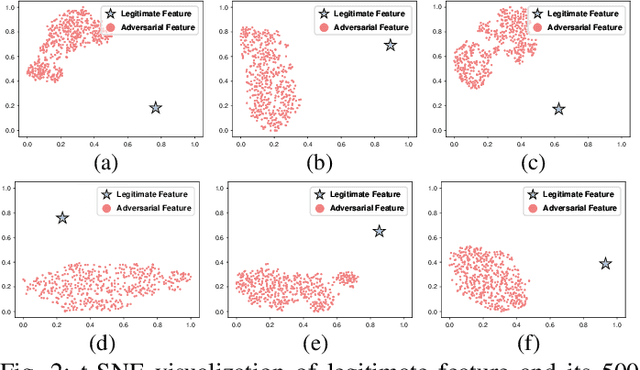
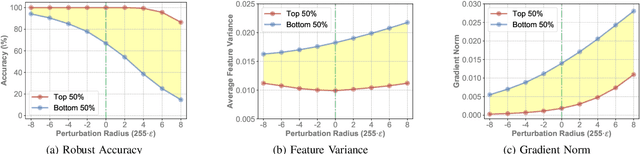
Despite remarkable achievements in deep learning across various domains, its inherent vulnerability to adversarial examples still remains a critical concern for practical deployment. Adversarial training has emerged as one of the most effective defensive techniques for improving model robustness against such malicious inputs. However, existing adversarial training schemes often lead to limited generalization ability against underlying adversaries with diversity due to their overreliance on a point-by-point augmentation strategy by mapping each clean example to its adversarial counterpart during training. In addition, adversarial examples can induce significant disruptions in the statistical information w.r.t. the target model, thereby introducing substantial uncertainty and challenges to modeling the distribution of adversarial examples. To circumvent these issues, in this paper, we propose a novel uncertainty-aware distributional adversarial training method, which enforces adversary modeling by leveraging both the statistical information of adversarial examples and its corresponding uncertainty estimation, with the goal of augmenting the diversity of adversaries. Considering the potentially negative impact induced by aligning adversaries to misclassified clean examples, we also refine the alignment reference based on the statistical proximity to clean examples during adversarial training, thereby reframing adversarial training within a distribution-to-distribution matching framework interacted between the clean and adversarial domains. Furthermore, we design an introspective gradient alignment approach via matching input gradients between these domains without introducing external models. Extensive experiments across four benchmark datasets and various network architectures demonstrate that our approach achieves state-of-the-art adversarial robustness and maintains natural performance.
Capturing complex hand movements and object interactions using machine learning-powered stretchable smart textile gloves
Oct 03, 2024Accurate real-time tracking of dexterous hand movements and interactions has numerous applications in human-computer interaction, metaverse, robotics, and tele-health. Capturing realistic hand movements is challenging because of the large number of articulations and degrees of freedom. Here, we report accurate and dynamic tracking of articulated hand and finger movements using stretchable, washable smart gloves with embedded helical sensor yarns and inertial measurement units. The sensor yarns have a high dynamic range, responding to low 0.005 % to high 155 % strains, and show stability during extensive use and washing cycles. We use multi-stage machine learning to report average joint angle estimation root mean square errors of 1.21 and 1.45 degrees for intra- and inter-subjects cross-validation, respectively, matching accuracy of costly motion capture cameras without occlusion or field of view limitations. We report a data augmentation technique that enhances robustness to noise and variations of sensors. We demonstrate accurate tracking of dexterous hand movements during object interactions, opening new avenues of applications including accurate typing on a mock paper keyboard, recognition of complex dynamic and static gestures adapted from American Sign Language and object identification.
Automatic Medical Report Generation: Methods and Applications
Aug 26, 2024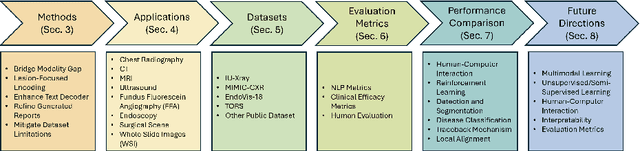
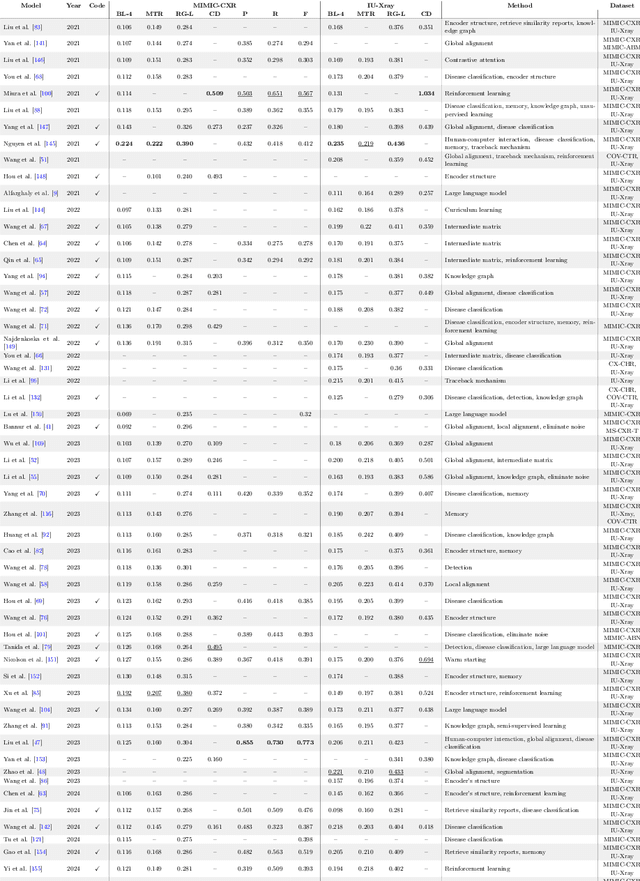
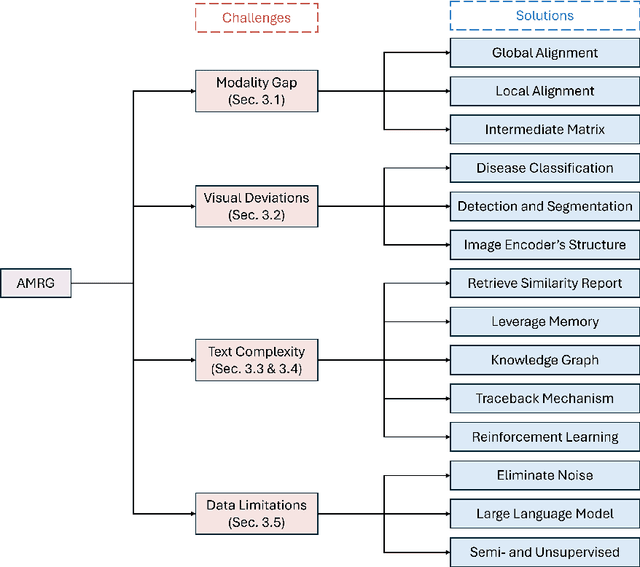
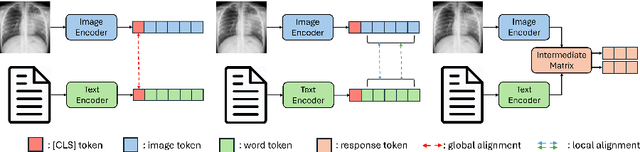
The increasing demand for medical imaging has surpassed the capacity of available radiologists, leading to diagnostic delays and potential misdiagnoses. Artificial intelligence (AI) techniques, particularly in automatic medical report generation (AMRG), offer a promising solution to this dilemma. This review comprehensively examines AMRG methods from 2021 to 2024. It (i) presents solutions to primary challenges in this field, (ii) explores AMRG applications across various imaging modalities, (iii) introduces publicly available datasets, (iv) outlines evaluation metrics, (v) identifies techniques that significantly enhance model performance, and (vi) discusses unresolved issues and potential future research directions. This paper aims to provide a comprehensive understanding of the existing literature and inspire valuable future research.