 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Precipitation Nowcasting Horizons via Spectral Fusion of Radar Observations and Foundation Model Priors
Mar 23, 2026Precipitation nowcasting is critical for disaster mitigation and aviation safety. However, radar-only models frequently suffer from a lack of large-scale atmospheric context, leading to performance degradation at longer lead times. While integrating meteorological variables predicted by weather foundation models offers a potential remedy, existing architectures fail to reconcile the profound representational heterogeneities between radar imagery and meteorological data. To bridge this gap, we propose PW-FouCast, a novel frequency-domain fusion framework that leverages Pangu-Weather forecasts as spectral priors within a Fourier-based backbone. Our architecture introduces three key innovations: (i) Pangu-Weather-guided Frequency Modulation to align spectral magnitudes and phases with meteorological priors; (ii) Frequency Memory to correct phase discrepancies and preserve temporal evolution; and (iii) Inverted Frequency Attention to reconstruct high-frequency details typically lost in spectral filtering. Extensive experiments on the SEVIR and MeteoNet benchmarks demonstrate that PW-FouCast achieves state-of-the-art performance, effectively extending the reliable forecast horizon while maintaining structural fidelity. Our code is available at https://github.com/Onemissed/PW-FouCast.
Towards Minimizing Feature Drift in Model Merging: Layer-wise Task Vector Fusion for Adaptive Knowledge Integration
May 29, 2025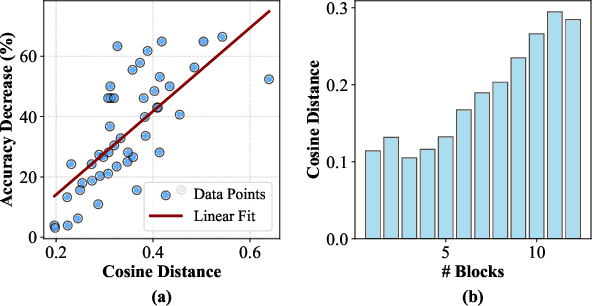
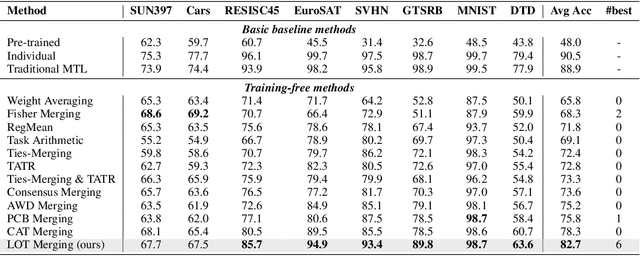
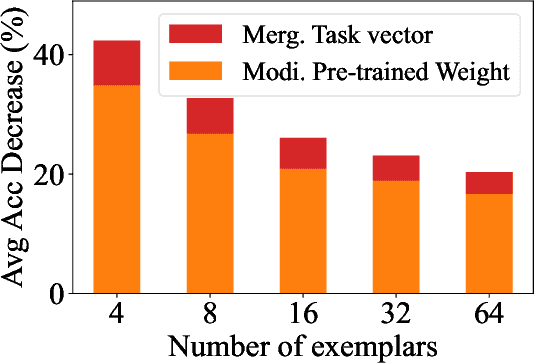
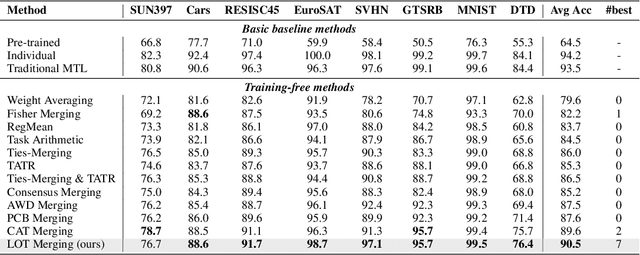
Multi-task model merging aims to consolidate knowledge from multiple fine-tuned task-specific experts into a unified model while minimizing performance degradation. Existing methods primarily approach this by minimizing differences between task-specific experts and the unified model, either from a parameter-level or a task-loss perspective. However, parameter-level methods exhibit a significant performance gap compared to the upper bound, while task-loss approaches entail costly secondary training procedures. In contrast, we observe that performance degradation closely correlates with feature drift, i.e., differences in feature representations of the same sample caused by model merging. Motivated by this observation, we propose Layer-wise Optimal Task Vector Merging (LOT Merging), a technique that explicitly minimizes feature drift between task-specific experts and the unified model in a layer-by-layer manner. LOT Merging can be formulated as a convex quadratic optimization problem, enabling us to analytically derive closed-form solutions for the parameters of linear and normalization layers. Consequently, LOT Merging achieves efficient model consolidation through basic matrix operations. Extensive experiments across vision and vision-language benchmarks demonstrate that LOT Merging significantly outperforms baseline methods, achieving improvements of up to 4.4% (ViT-B/32) over state-of-the-art approaches.
CAT Merging: A Training-Free Approach for Resolving Conflicts in Model Merging
May 14, 2025Multi-task model merging offers a promising paradigm for integrating multiple expert models into a unified model without additional training. Existing state-of-the-art techniques, such as Task Arithmetic and its variants, merge models by accumulating task vectors -- the parameter differences between pretrained and finetuned models. However, task vector accumulation is often hindered by knowledge conflicts, leading to performance degradation. To address this challenge, we propose Conflict-Aware Task Merging (CAT Merging), a novel training-free framework that selectively trims conflict-prone components from the task vectors. CAT Merging introduces several parameter-specific strategies, including projection for linear weights and masking for scaling and shifting parameters in normalization layers. Extensive experiments on vision, language, and vision-language tasks demonstrate that CAT Merging effectively suppresses knowledge conflicts, achieving average accuracy improvements of up to 2.5% (ViT-B/32) and 2.0% (ViT-L/14) over state-of-the-art methods.
Task Arithmetic in Trust Region: A Training-Free Model Merging Approach to Navigate Knowledge Conflicts
Jan 25, 2025



Multi-task model merging offers an efficient solution for integrating knowledge from multiple fine-tuned models, mitigating the significant computational and storage demands associated with multi-task training. As a key technique in this field, Task Arithmetic (TA) defines task vectors by subtracting the pre-trained model ($\theta_{\text{pre}}$) from the fine-tuned task models in parameter space, then adjusting the weight between these task vectors and $\theta_{\text{pre}}$ to balance task-generalized and task-specific knowledge. Despite the promising performance of TA, conflicts can arise among the task vectors, particularly when different tasks require distinct model adaptations. In this paper, we formally define this issue as knowledge conflicts, characterized by the performance degradation of one task after merging with a model fine-tuned for another task. Through in-depth analysis, we show that these conflicts stem primarily from the components of task vectors that align with the gradient of task-specific losses at $\theta_{\text{pre}}$. To address this, we propose Task Arithmetic in Trust Region (TATR), which defines the trust region as dimensions in the model parameter space that cause only small changes (corresponding to the task vector components with gradient orthogonal direction) in the task-specific losses. Restricting parameter merging within this trust region, TATR can effectively alleviate knowledge conflicts. Moreover, TATR serves as both an independent approach and a plug-and-play module compatible with a wide range of TA-based methods. Extensive empirical evaluations on eight distinct datasets robustly demonstrate that TATR improves the multi-task performance of several TA-based model merging methods by an observable margin.
ORB-SLAM3AB: Augmenting ORB-SLAM3 to Counteract Bumps with Optical Flow Inter-frame Matching
Nov 27, 2024



This paper proposes an enhancement to the ORB-SLAM3 algorithm, tailored for applications on rugged road surfaces. Our improved algorithm adeptly combines feature point matching with optical flow methods, capitalizing on the high robustness of optical flow in complex terrains and the high precision of feature points on smooth surfaces. By refining the inter-frame matching logic of ORB-SLAM3, we have addressed the issue of frame matching loss on uneven roads. To prevent a decrease in accuracy, an adaptive matching mechanism has been incorporated, which increases the reliance on optical flow points during periods of high vibration, thereby effectively maintaining SLAM precision. Furthermore, due to the scarcity of multi-sensor datasets suitable for environments with bumpy roads or speed bumps, we have collected LiDAR and camera data from such settings. Our enhanced algorithm, ORB-SLAM3AB, was then benchmarked against several advanced open-source SLAM algorithms that rely solely on laser or visual data. Through the analysis of Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) metrics, our results demonstrate that ORB-SLAM3AB achieves superior robustness and accuracy on rugged road surfaces.
Towards Plastic and Stable Exemplar-Free Incremental Learning: A Dual-Learner Framework with Cumulative Parameter Averaging
Oct 28, 2023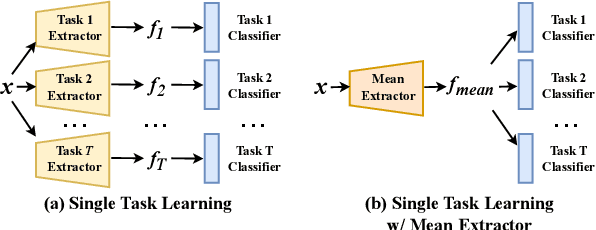

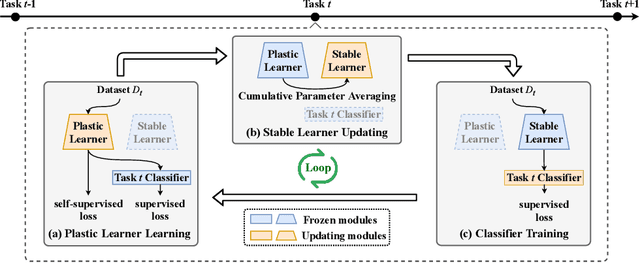
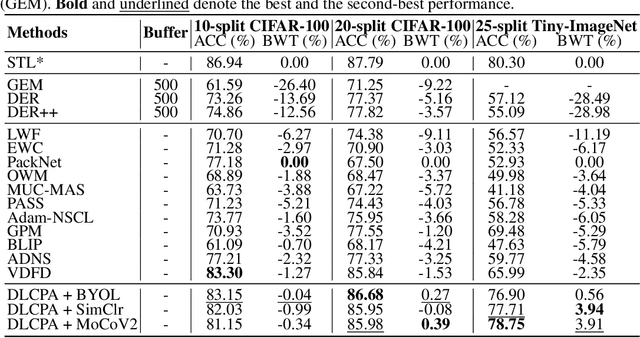
The dilemma between plasticity and stability presents a significant challenge in Incremental Learning (IL), especially in the exemplar-free scenario where accessing old-task samples is strictly prohibited during the learning of a new task. A straightforward solution to this issue is learning and storing an independent model for each task, known as Single Task Learning (STL). Despite the linear growth in model storage with the number of tasks in STL, we empirically discover that averaging these model parameters can potentially preserve knowledge across all tasks. Inspired by this observation, we propose a Dual-Learner framework with Cumulative Parameter Averaging (DLCPA). DLCPA employs a dual-learner design: a plastic learner focused on acquiring new-task knowledge and a stable learner responsible for accumulating all learned knowledge. The knowledge from the plastic learner is transferred to the stable learner via cumulative parameter averaging. Additionally, several task-specific classifiers work in cooperation with the stable learner to yield the final prediction. Specifically, when learning a new task, these modules are updated in a cyclic manner: i) the plastic learner is initially optimized using a self-supervised loss besides the supervised loss to enhance the feature extraction robustness; ii) the stable learner is then updated with respect to the plastic learner in a cumulative parameter averaging manner to maintain its task-wise generalization; iii) the task-specific classifier is accordingly optimized to align with the stable learner. Experimental results on CIFAR-100 and Tiny-ImageNet show that DLCPA outperforms several state-of-the-art exemplar-free baselines in both Task-IL and Class-IL settings.
Exemplar-free Class Incremental Learning via Discriminative and Comparable One-class Classifiers
Jan 05, 2022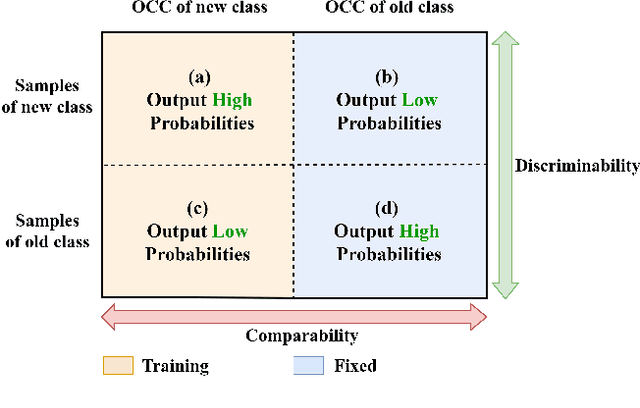
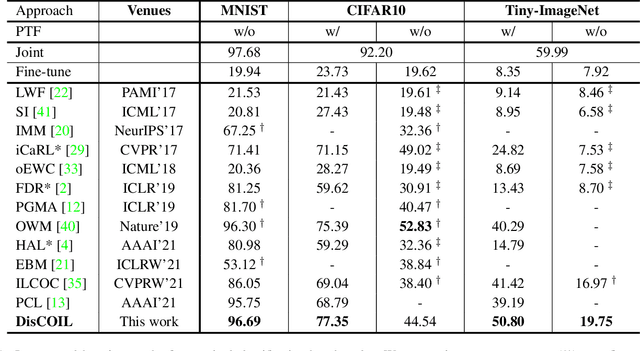
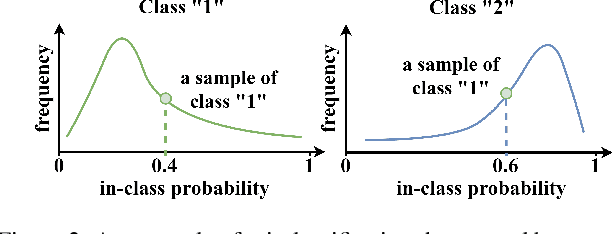
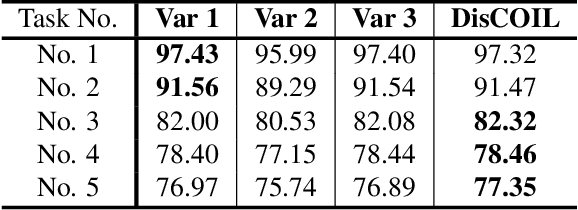
The exemplar-free class incremental learning requires classification models to learn new class knowledge incrementally without retaining any old samples. Recently, the framework based on parallel one-class classifiers (POC), which trains a one-class classifier (OCC) independently for each category, has attracted extensive attention, since it can naturally avoid catastrophic forgetting. POC, however, suffers from weak discriminability and comparability due to its independent training strategy for different OOCs. To meet this challenge, we propose a new framework, named Discriminative and Comparable One-class classifiers for Incremental Learning (DisCOIL). DisCOIL follows the basic principle of POC, but it adopts variational auto-encoders (VAE) instead of other well-established one-class classifiers (e.g. deep SVDD), because a trained VAE can not only identify the probability of an input sample belonging to a class but also generate pseudo samples of the class to assist in learning new tasks. With this advantage, DisCOIL trains a new-class VAE in contrast with the old-class VAEs, which forces the new-class VAE to reconstruct better for new-class samples but worse for the old-class pseudo samples, thus enhancing the comparability. Furthermore, DisCOIL introduces a hinge reconstruction loss to ensure the discriminability. We evaluate our method extensively on MNIST, CIFAR10, and Tiny-ImageNet. The experimental results show that DisCOIL achieves state-of-the-art performance.
TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition
Jun 28, 2021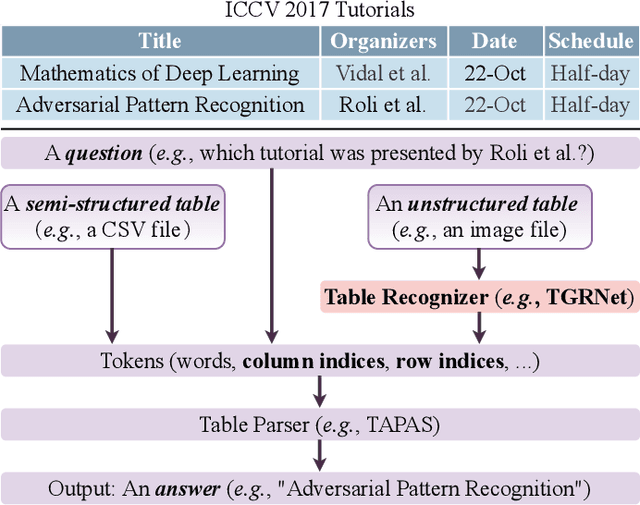
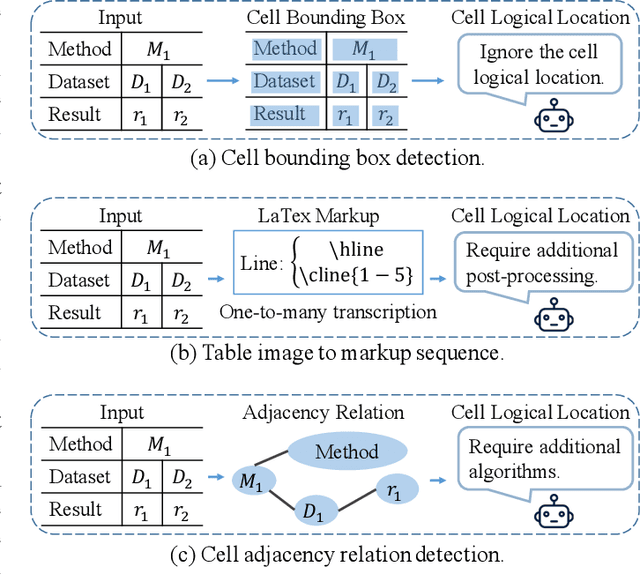
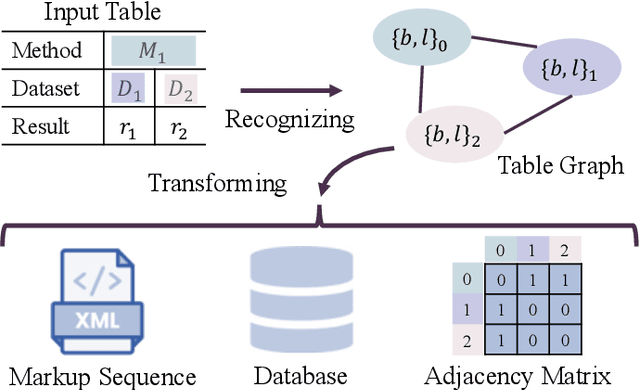
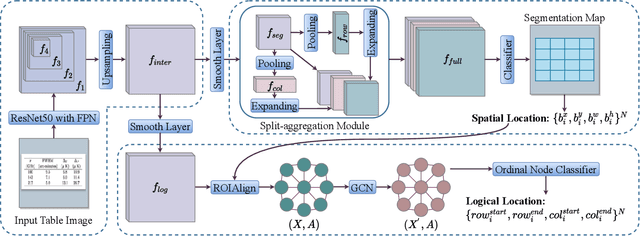
A table arranging data in rows and columns is a very effective data structure, which has been widely used in business and scientific research. Considering large-scale tabular data in online and offline documents, automatic table recognition has attracted increasing attention from the document analysis community. Though human can easily understand the structure of tables, it remains a challenge for machines to understand that, especially due to a variety of different table layouts and styles. Existing methods usually model a table as either the markup sequence or the adjacency matrix between different table cells, failing to address the importance of the logical location of table cells, e.g., a cell is located in the first row and the second column of the table. In this paper, we reformulate the problem of table structure recognition as the table graph reconstruction, and propose an end-to-end trainable table graph reconstruction network (TGRNet) for table structure recognition. Specifically, the proposed method has two main branches, a cell detection branch and a cell logical location branch, to jointly predict the spatial location and the logical location of different cells. Experimental results on three popular table recognition datasets and a new dataset with table graph annotations (TableGraph-350K) demonstrate the effectiveness of the proposed TGRNet for table structure recognition. Code and annotations will be made publicly available.
MTNet: A Multi-Task Neural Network for On-Field Calibration of Low-Cost Air Monitoring Sensors
May 10, 2021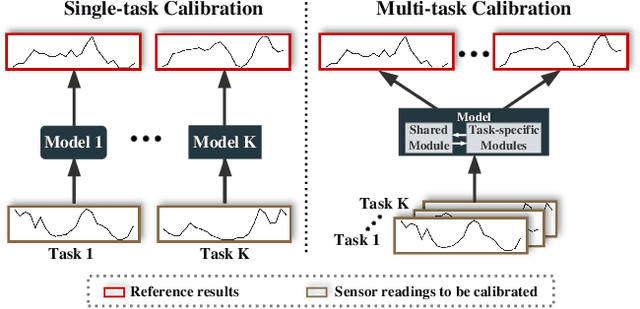
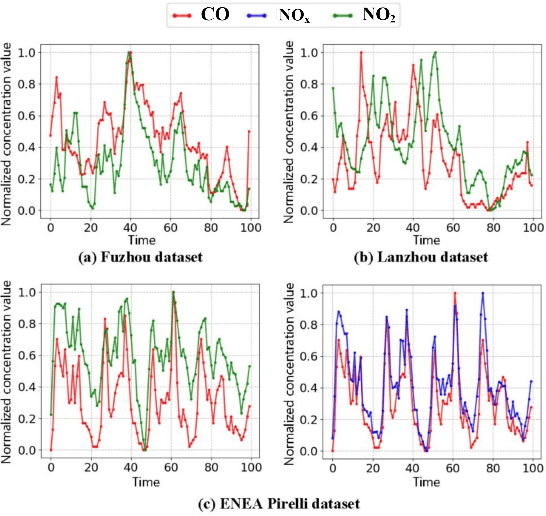
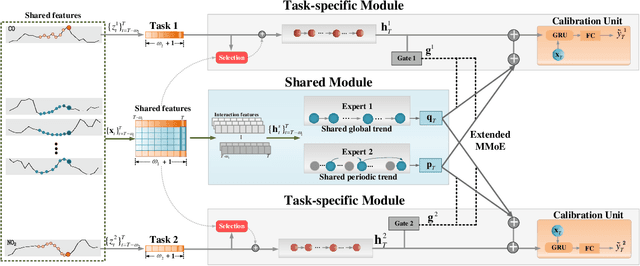
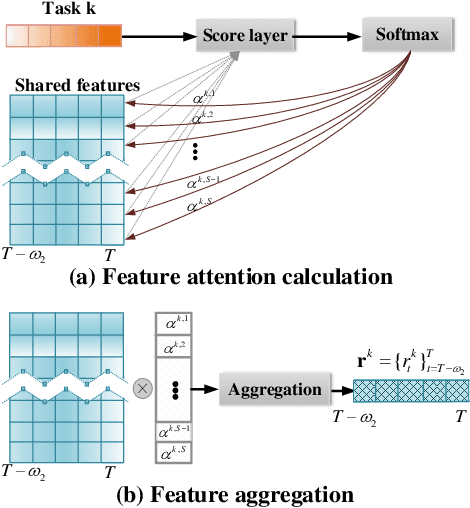
The advances of sensor technology enable people to monitor air quality through widely distributed low-cost sensors. However, measurements from these sensors usually encounter high biases and require a calibration step to reach an acceptable performance in down-streaming analytical tasks. Most existing calibration methods calibrate one type of sensor at a time, which we call single-task calibration. Despite the popularity of this single-task schema, it may neglect interactions among calibration tasks of different sensors, which encompass underlying information to promote calibration performance. In this paper, we propose a multi-task calibration network (MTNet) to calibrate multiple sensors (e.g., carbon monoxide and nitrogen oxide sensors) simultaneously, modeling the interactions among tasks. MTNet consists of a single shared module, and several task-specific modules. Specifically, in the shared module, we extend the multi-gate mixture-of-experts structure to harmonize the task conflicts and correlations among different tasks; in each task-specific module, we introduce a feature selection strategy to customize the input for the specific task. These improvements allow MTNet to learn interaction information shared across different tasks, and task-specific information for each calibration task as well. We evaluate MTNet on three real-world datasets and compare it with several established baselines. The experimental results demonstrate that MTNet achieves the state-of-the-art performance.
Multi-Component Graph Convolutional Collaborative Filtering
Nov 25, 2019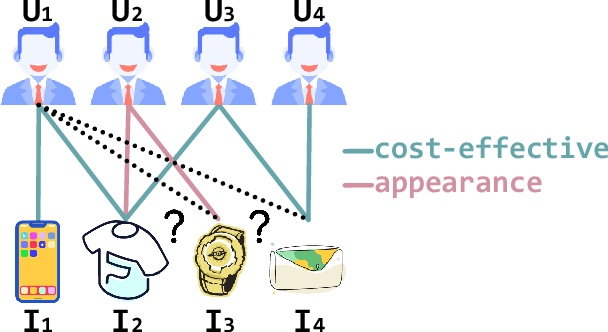

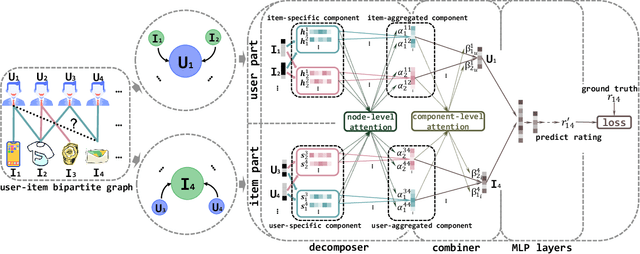
The interactions of users and items in recommender system could be naturally modeled as a user-item bipartite graph. In recent years, we have witnessed an emerging research effort in exploring user-item graph for collaborative filtering methods. Nevertheless, the formation of user-item interactions typically arises from highly complex latent purchasing motivations, such as high cost performance or eye-catching appearance, which are indistinguishably represented by the edges. The existing approaches still remain the differences between various purchasing motivations unexplored, rendering the inability to capture fine-grained user preference. Therefore, in this paper we propose a novel Multi-Component graph convolutional Collaborative Filtering (MCCF) approach to distinguish the latent purchasing motivations underneath the observed explicit user-item interactions. Specifically, there are two elaborately designed modules, decomposer and combiner, inside MCCF. The former first decomposes the edges in user-item graph to identify the latent components that may cause the purchasing relationship; the latter then recombines these latent components automatically to obtain unified embeddings for prediction. Furthermore, the sparse regularizer and weighted random sample strategy are utilized to alleviate the overfitting problem and accelerate the optimization. Empirical results on three real datasets and a synthetic dataset not only show the significant performance gains of MCCF, but also well demonstrate the necessity of considering multiple components.