 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitC-3DGS: High-Capacity 3D Gaussian Splatting Watermarking via Bit Compression
May 28, 2026High-capacity watermarking is necessary for 3D Gaussian Splatting (3DGS) assets to embed rich information (e.g., ownership, provenance, and authentication codes), enabling reliable identification and integrity verification in large-scale 3D asset pipelines. Existing bit-to-token watermarking methods based on a pre-trained text encoder are limited to 77-bit messages due to CLIP's fixed 77-token context length, as tokens beyond this limit are unsupported by learned positional embeddings. To address this limitation, we introduce BitC-3DGS, a bit-compression framework that encodes multiple message bits per token. It employs a bit-compressed tokenization scheme that encodes multiple bits within the same chunk into a single semantic token. To enable recovery of the compressed information, it further introduces a dual-branch architecture for joint chunk decompression and bit decoding, along with a hard-message sampling strategy to improve combinatorial coverage during decoder training. Extensive experiments on the Blender and LLFF datasets demonstrate the effectiveness of BitC-3DGS for high-capacity watermarking, achieving high message recovery accuracy and rendering fidelity. For example, it supports 128-bit message capacity with recovery accuracy comparable to that of 64-bit messages in recent state-of-the-art methods.
OGA-AID: Clinician-in-the-loop AI Report Drafting Assistant for Multimodal Observational Gait Analysis in Post-Stroke Rehabilitation
Apr 07, 2026Gait analysis is essential in post-stroke rehabilitation but remains time-intensive and cognitively demanding, especially when clinicians must integrate gait videos and motion-capture data into structured reports. We present OGA-AID, a clinician-in-the-loop multi-agent large language model system for multimodal report drafting. The system coordinates 3 specialized agents to synthesize patient movement recordings, kinematic trajectories, and clinical profiles into structured assessments. Evaluated with expert physiotherapists on real patient data, OGA-AID consistently outperforms single-pass multimodal baselines with low error. In clinician-in-the-loop settings, brief expert preliminary notes further reduce error compared to reference assessments. Our findings demonstrate the feasibility of multimodal agentic systems for structured clinical gait assessment and highlight the complementary relationship between AI-assisted analysis and human clinical judgment in rehabilitation workflows.
SteelDefectX: A Coarse-to-Fine Vision-Language Dataset and Benchmark for Generalizable Steel Surface Defect Detection
Mar 23, 2026Steel surface defect detection is essential for ensuring product quality and reliability in modern manufacturing. Current methods often rely on basic image classification models trained on label-only datasets, which limits their interpretability and generalization. To address these challenges, we introduce SteelDefectX, a vision-language dataset containing 7,778 images across 25 defect categories, annotated with coarse-to-fine textual descriptions. At the coarse-grained level, the dataset provides class-level information, including defect categories, representative visual attributes, and associated industrial causes. At the fine-grained level, it captures sample-specific attributes, such as shape, size, depth, position, and contrast, enabling models to learn richer and more detailed defect representations. We further establish a benchmark comprising four tasks, vision-only classification, vision-language classification, few/zero-shot recognition, and zero-shot transfer, to evaluate model performance and generalization. Experiments with several baseline models demonstrate that coarse-to-fine textual annotations significantly improve interpretability, generalization, and transferability. We hope that SteelDefectX will serve as a valuable resource for advancing research on explainable, generalizable steel surface defect detection. The data will be publicly available on https://github.com/Zhaosxian/SteelDefectX.
TimeAPN: Adaptive Amplitude-Phase Non-Stationarity Normalization for Time Series Forecasting
Mar 18, 2026Non-stationarity is a fundamental challenge in multivariate long-term time series forecasting, often manifested as rapid changes in amplitude and phase. These variations lead to severe distribution shifts and consequently degrade predictive performance. Existing normalization-based methods primarily rely on first- and second-order statistics, implicitly assuming that distributions evolve smoothly and overlooking fine-grained temporal dynamics. To address these limitations, we propose TimeAPN, an Adaptive Amplitude-Phase Non-Stationarity Normalization framework that explicitly models and predicts non-stationary factors from both the time and frequency domains. Specifically, TimeAPN first models the mean sequence jointly in the time and frequency domains, and then forecasts its evolution over future horizons. Meanwhile, phase information is extracted in the frequency domain, and the phase discrepancy between the predicted and ground-truth future sequences is explicitly modeled to capture temporal misalignment. Furthermore, TimeAPN incorporates amplitude information into an adaptive normalization mechanism, enabling the model to effectively account for abrupt fluctuations in signal energy. The predicted non-stationary factors are subsequently integrated with the backbone forecasting outputs through a collaborative de-normalization process to reconstruct the final non-stationary time series. The proposed framework is model-agnostic and can be seamlessly integrated with various forecasting backbones. Extensive experiments on seven real-world multivariate datasets demonstrate that TimeAPN consistently improves long-term forecasting accuracy across multiple prediction horizons and outperforms state-of-the-art reversible normalization methods.
Recycling Failures: Salvaging Exploration in RLVR via Fine-Grained Off-Policy Guidance
Feb 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the complex reasoning capabilities of Large Reasoning Models. However, standard outcome-based supervision suffers from a critical limitation that penalizes trajectories that are largely correct but fail due to several missteps as heavily as completely erroneous ones. This coarse feedback signal causes the model to discard valuable largely correct rollouts, leading to a degradation in rollout diversity that prematurely narrows the exploration space. Process Reward Models have demonstrated efficacy in providing reliable step-wise verification for test-time scaling, naively integrating these signals into RLVR as dense rewards proves ineffective.Prior methods attempt to introduce off-policy guided whole-trajectory replacement that often outside the policy model's distribution, but still fail to utilize the largely correct rollouts generated by the model itself and thus do not effectively mitigate the narrowing of the exploration space. To address these issues, we propose SCOPE (Step-wise Correction for On-Policy Exploration), a novel framework that utilizes Process Reward Models to pinpoint the first erroneous step in suboptimal rollouts and applies fine-grained, step-wise off-policy rectification. By applying precise refinement on partially correct rollout, our method effectively salvages partially correct trajectories and increases diversity score by 13.5%, thereby sustaining a broad exploration space. Extensive experiments demonstrate that our approach establishes new state-of-the-art results, achieving an average accuracy of 46.6% on math reasoning and exhibiting robust generalization with 53.4% accuracy on out-of-distribution reasoning tasks.
Toward Fine-Grained Facial Control in 3D Talking Head Generation
Feb 10, 2026Audio-driven talking head generation is a core component of digital avatars, and 3D Gaussian Splatting has shown strong performance in real-time rendering of high-fidelity talking heads. However, achieving precise control over fine-grained facial movements remains a significant challenge, particularly due to lip-synchronization inaccuracies and facial jitter, both of which can contribute to the uncanny valley effect. To address these challenges, we propose Fine-Grained 3D Gaussian Splatting (FG-3DGS), a novel framework that enables temporally consistent and high-fidelity talking head generation. Our method introduces a frequency-aware disentanglement strategy to explicitly model facial regions based on their motion characteristics. Low-frequency regions, such as the cheeks, nose, and forehead, are jointly modeled using a standard MLP, while high-frequency regions, including the eyes and mouth, are captured separately using a dedicated network guided by facial area masks. The predicted motion dynamics, represented as Gaussian deltas, are applied to the static Gaussians to generate the final head frames, which are rendered via a rasterizer using frame-specific camera parameters. Additionally, a high-frequency-refined post-rendering alignment mechanism, learned from large-scale audio-video pairs by a pretrained model, is incorporated to enhance per-frame generation and achieve more accurate lip synchronization. Extensive experiments on widely used datasets for talking head generation demonstrate that our method outperforms recent state-of-the-art approaches in producing high-fidelity, lip-synced talking head videos.
Towards Reliable Medical LLMs: Benchmarking and Enhancing Confidence Estimation of Large Language Models in Medical Consultation
Jan 22, 2026Large-scale language models (LLMs) often offer clinical judgments based on incomplete information, increasing the risk of misdiagnosis. Existing studies have primarily evaluated confidence in single-turn, static settings, overlooking the coupling between confidence and correctness as clinical evidence accumulates during real consultations, which limits their support for reliable decision-making. We propose the first benchmark for assessing confidence in multi-turn interaction during realistic medical consultations. Our benchmark unifies three types of medical data for open-ended diagnostic generation and introduces an information sufficiency gradient to characterize the confidence-correctness dynamics as evidence increases. We implement and compare 27 representative methods on this benchmark; two key insights emerge: (1) medical data amplifies the inherent limitations of token-level and consistency-level confidence methods, and (2) medical reasoning must be evaluated for both diagnostic accuracy and information completeness. Based on these insights, we present MedConf, an evidence-grounded linguistic self-assessment framework that constructs symptom profiles via retrieval-augmented generation, aligns patient information with supporting, missing, and contradictory relations, and aggregates them into an interpretable confidence estimate through weighted integration. Across two LLMs and three medical datasets, MedConf consistently outperforms state-of-the-art methods on both AUROC and Pearson correlation coefficient metrics, maintaining stable performance under conditions of information insufficiency and multimorbidity. These results demonstrate that information adequacy is a key determinant of credible medical confidence modeling, providing a new pathway toward building more reliable and interpretable large medical models.
Cross-Sample Augmented Test-Time Adaptation for Personalized Intraoperative Hypotension Prediction
Dec 12, 2025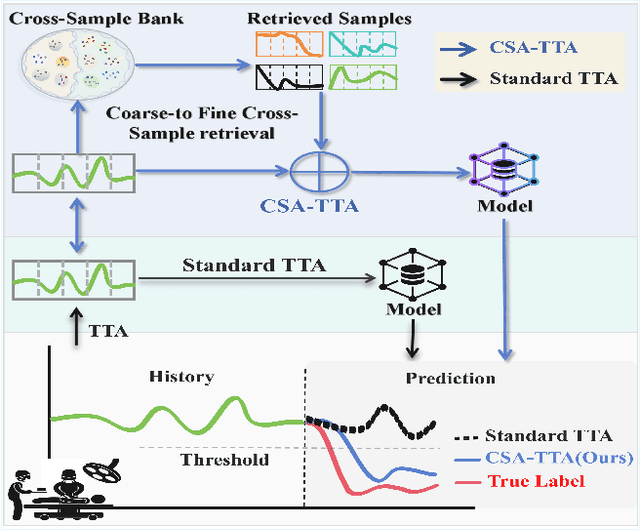
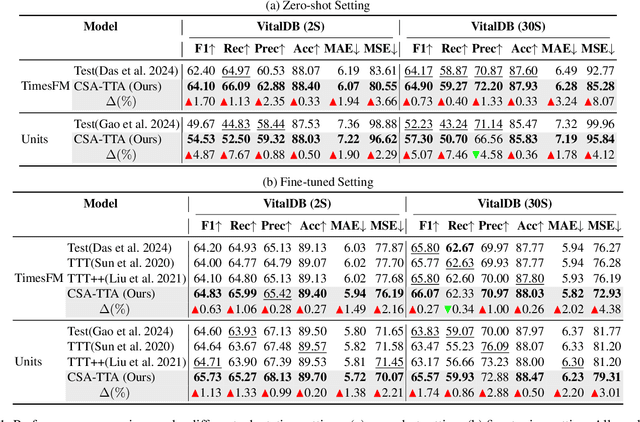
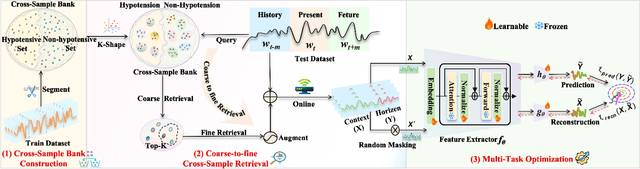
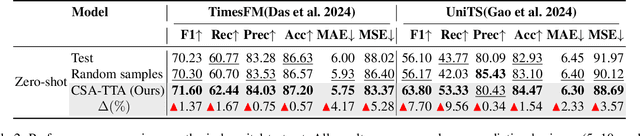
Intraoperative hypotension (IOH) poses significant surgical risks, but accurate prediction remains challenging due to patient-specific variability. While test-time adaptation (TTA) offers a promising approach for personalized prediction, the rarity of IOH events often leads to unreliable test-time training. To address this, we propose CSA-TTA, a novel Cross-Sample Augmented Test-Time Adaptation framework that enhances training by incorporating hypotension events from other individuals. Specifically, we first construct a cross-sample bank by segmenting historical data into hypotensive and non-hypotensive samples. Then, we introduce a coarse-to-fine retrieval strategy for building test-time training data: we initially apply K-Shape clustering to identify representative cluster centers and subsequently retrieve the top-K semantically similar samples based on the current patient signal. Additionally, we integrate both self-supervised masked reconstruction and retrospective sequence forecasting signals during training to enhance model adaptability to rapid and subtle intraoperative dynamics. We evaluate the proposed CSA-TTA on both the VitalDB dataset and a real-world in-hospital dataset by integrating it with state-of-the-art time series forecasting models, including TimesFM and UniTS. CSA-TTA consistently enhances performance across settings-for instance, on VitalDB, it improves Recall and F1 scores by +1.33% and +1.13%, respectively, under fine-tuning, and by +7.46% and +5.07% in zero-shot scenarios-demonstrating strong robustness and generalization.
Remodeling Semantic Relationships in Vision-Language Fine-Tuning
Nov 13, 2025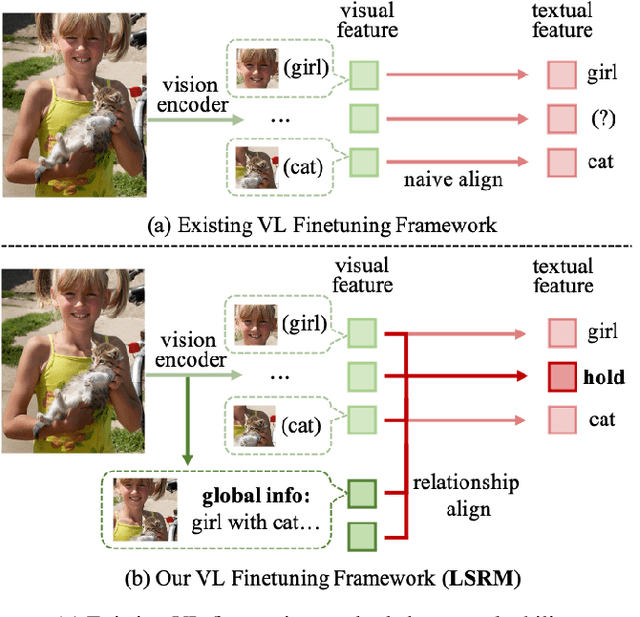


Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods.
Bi-Level Optimization for Self-Supervised AI-Generated Face Detection
Jul 30, 2025



AI-generated face detectors trained via supervised learning typically rely on synthesized images from specific generators, limiting their generalization to emerging generative techniques. To overcome this limitation, we introduce a self-supervised method based on bi-level optimization. In the inner loop, we pretrain a vision encoder only on photographic face images using a set of linearly weighted pretext tasks: classification of categorical exchangeable image file format (EXIF) tags, ranking of ordinal EXIF tags, and detection of artificial face manipulations. The outer loop then optimizes the relative weights of these pretext tasks to enhance the coarse-grained detection of manipulated faces, serving as a proxy task for identifying AI-generated faces. In doing so, it aligns self-supervised learning more closely with the ultimate goal of AI-generated face detection. Once pretrained, the encoder remains fixed, and AI-generated faces are detected either as anomalies under a Gaussian mixture model fitted to photographic face features or by a lightweight two-layer perceptron serving as a binary classifier. Extensive experiments demonstrate that our detectors significantly outperform existing approaches in both one-class and binary classification settings, exhibiting strong generalization to unseen generators.