 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Federated Prompt Learning for Vision Language Model
May 29, 2025The Vision Language Model (VLM) excels in aligning vision and language representations, and prompt learning has emerged as a key technique for adapting such models to downstream tasks. However, the application of prompt learning with VLM in federated learning (\fl{}) scenarios remains underexplored. This paper systematically investigates the behavioral differences between language prompt learning (LPT) and vision prompt learning (VPT) under data heterogeneity challenges, including label skew and domain shift. We conduct extensive experiments to evaluate the impact of various \fl{} and prompt configurations, such as client scale, aggregation strategies, and prompt length, to assess the robustness of Federated Prompt Learning (FPL). Furthermore, we explore strategies for enhancing prompt learning in complex scenarios where label skew and domain shift coexist, including leveraging both prompt types when computational resources allow. Our findings offer practical insights into optimizing prompt learning in federated settings, contributing to the broader deployment of VLMs in privacy-preserving environments.
A general physics-constrained method for the modelling of equation's closure terms with sparse data
Apr 30, 2025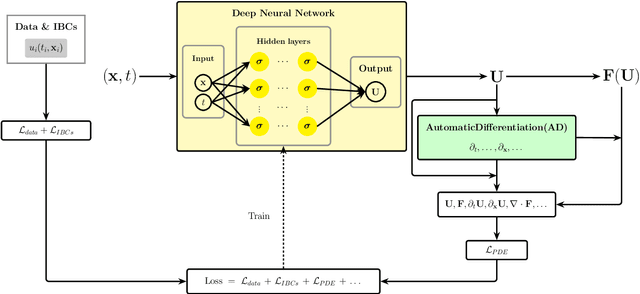
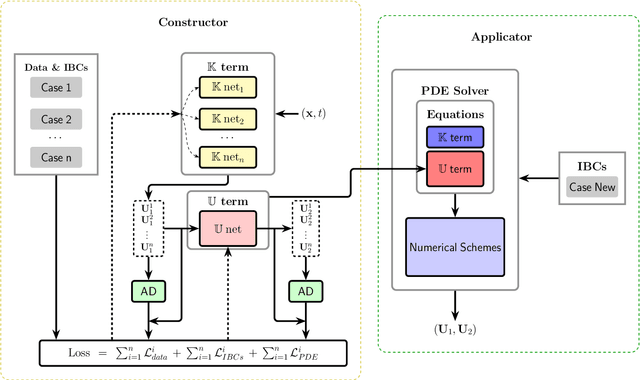

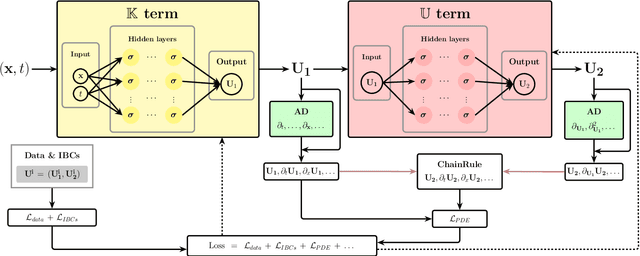
Accurate modeling of closure terms is a critical challenge in engineering and scientific research, particularly when data is sparse (scarse or incomplete), making widely applicable models difficult to develop. This study proposes a novel approach for constructing closure models in such challenging scenarios. We introduce a Series-Parallel Multi-Network Architecture that integrates Physics-Informed Neural Networks (PINNs) to incorporate physical constraints and heterogeneous data from multiple initial and boundary conditions, while employing dedicated subnetworks to independently model unknown closure terms, enhancing generalizability across diverse problems. These closure models are integrated into an accurate Partial Differential Equation (PDE) solver, enabling robust solutions to complex predictive simulations in engineering applications.
An Empirical Study of Methods for Small Object Detection from Satellite Imagery
Feb 05, 2025



This paper reviews object detection methods for finding small objects from remote sensing imagery and provides an empirical evaluation of four state-of-the-art methods to gain insights into method performance and technical challenges. In particular, we use car detection from urban satellite images and bee box detection from satellite images of agricultural lands as application scenarios. Drawing from the existing surveys and literature, we identify several top-performing methods for the empirical study. Public, high-resolution satellite image datasets are used in our experiments.
Personalized Quantum Federated Learning for Privacy Image Classification
Oct 03, 2024



Quantum federated learning has brought about the improvement of privacy image classification, while the lack of personality of the client model may contribute to the suboptimal of quantum federated learning. A personalized quantum federated learning algorithm for privacy image classification is proposed to enhance the personality of the client model in the case of an imbalanced distribution of images. First, a personalized quantum federated learning model is constructed, in which a personalized layer is set for the client model to maintain the personalized parameters. Second, a personalized quantum federated learning algorithm is introduced to secure the information exchanged between the client and server.Third, the personalized federated learning is applied to image classification on the FashionMNIST dataset, and the experimental results indicate that the personalized quantum federated learning algorithm can obtain global and local models with excellent performance, even in situations where local training samples are imbalanced. The server's accuracy is 100% with 8 clients and a distribution parameter of 100, outperforming the non-personalized model by 7%. The average client accuracy is 2.9% higher than that of the non-personalized model with 2 clients and a distribution parameter of 1. Compared to previous quantum federated learning algorithms, the proposed personalized quantum federated learning algorithm eliminates the need for additional local training while safeguarding both model and data privacy.It may facilitate broader adoption and application of quantum technologies, and pave the way for more secure, scalable, and efficient quantum distribute machine learning solutions.
Progressive Retinal Image Registration via Global and Local Deformable Transformations
Sep 02, 2024

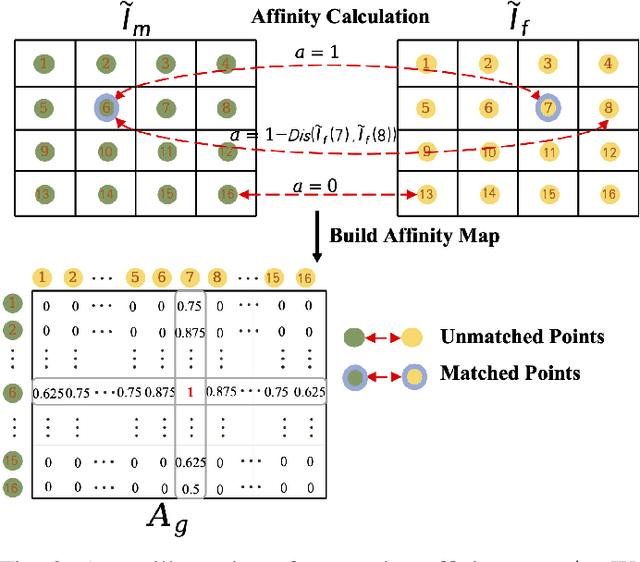

Retinal image registration plays an important role in the ophthalmological diagnosis process. Since there exist variances in viewing angles and anatomical structures across different retinal images, keypoint-based approaches become the mainstream methods for retinal image registration thanks to their robustness and low latency. These methods typically assume the retinal surfaces are planar, and adopt feature matching to obtain the homography matrix that represents the global transformation between images. Yet, such a planar hypothesis inevitably introduces registration errors since retinal surface is approximately curved. This limitation is more prominent when registering image pairs with significant differences in viewing angles. To address this problem, we propose a hybrid registration framework called HybridRetina, which progressively registers retinal images with global and local deformable transformations. For that, we use a keypoint detector and a deformation network called GAMorph to estimate the global transformation and local deformable transformation, respectively. Specifically, we integrate multi-level pixel relation knowledge to guide the training of GAMorph. Additionally, we utilize an edge attention module that includes the geometric priors of the images, ensuring the deformation field focuses more on the vascular regions of clinical interest. Experiments on two widely-used datasets, FIRE and FLoRI21, show that our proposed HybridRetina significantly outperforms some state-of-the-art methods. The code is available at https://github.com/lyp-deeplearning/awesome-retinal-registration.
Frankenstein: Generating Semantic-Compositional 3D Scenes in One Tri-Plane
Mar 24, 2024



We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. The 3D scene information is encoded in one single tri-plane tensor, from which multiple Singed Distance Function (SDF) fields can be decoded to represent the compositional shapes. During training, an auto-encoder compresses tri-planes into a latent space, and then the denoising diffusion process is employed to approximate the distribution of the compositional scenes. Frankenstein demonstrates promising results in generating room interiors as well as human avatars with automatically separated parts. The generated scenes facilitate many downstream applications, such as part-wise re-texturing, object rearrangement in the room or avatar cloth re-targeting.
Unified High-binding Watermark for Unconditional Image Generation Models
Oct 14, 2023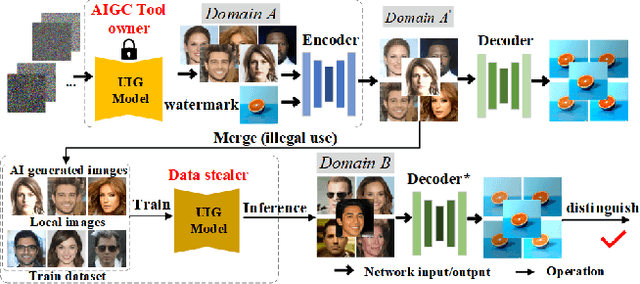
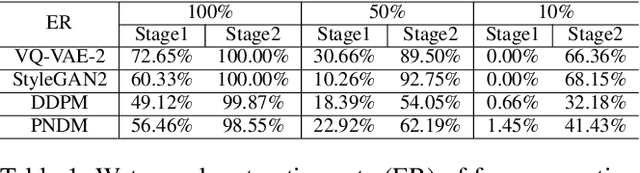
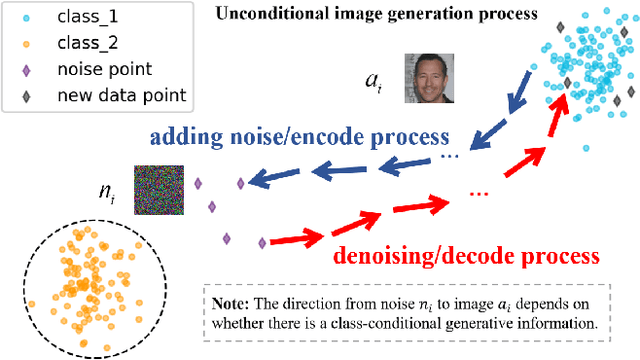
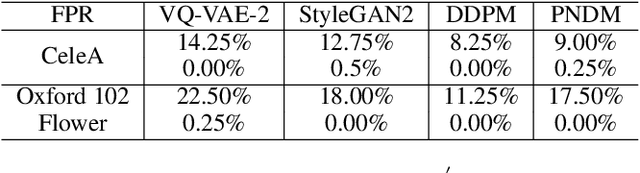
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.
Flover: A Temporal Fusion Framework for Efficient Autoregressive Model Parallel Inference
May 24, 2023



In the rapidly evolving field of deep learning, the performance of model inference has become a pivotal aspect as models become more complex and are deployed in diverse applications. Among these, autoregressive models stand out due to their state-of-the-art performance in numerous generative tasks. These models, by design, harness a temporal dependency structure, where the current token's probability distribution is conditioned on preceding tokens. This inherently sequential characteristic, however, adheres to the Markov Chain assumption and lacks temporal parallelism, which poses unique challenges. Particularly in industrial contexts where inference requests, following a Poisson time distribution, necessitate diverse response lengths, this absence of parallelism is more profound. Existing solutions, such as dynamic batching and concurrent model instances, nevertheless, come with severe overheads and a lack of flexibility, these coarse-grained methods fall short of achieving optimal latency and throughput. To address these shortcomings, we propose Flavor -- a temporal fusion framework for efficient inference in autoregressive models, eliminating the need for heuristic settings and applies to a wide range of inference scenarios. By providing more fine-grained parallelism on the temporality of requests and employing an efficient memory shuffle algorithm, Flover achieves up to 11x faster inference on GPT models compared to the cutting-edge solutions provided by NVIDIA Triton FasterTransformer. Crucially, by leveraging the advanced tensor parallel technique, Flover proves efficacious across diverse computational landscapes, from single-GPU setups to multi-node scenarios, thereby offering robust performance optimization that transcends hardware boundaries.
Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version
Mar 09, 2023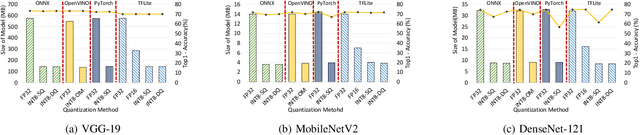

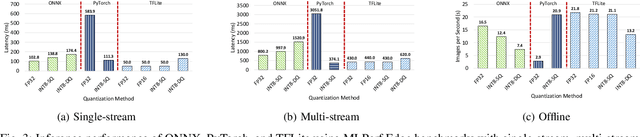
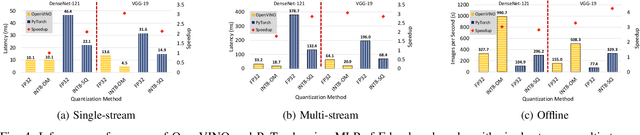
Quantization is a popular technique used in Deep Neural Networks (DNN) inference to reduce the size of models and improve the overall numerical performance by exploiting native hardware. This paper attempts to conduct an elaborate performance characterization of the benefits of using quantization techniques -- mainly FP16/INT8 variants with static and dynamic schemes -- using the MLPerf Edge Inference benchmarking methodology. The study is conducted on Intel x86 processors and Raspberry Pi device with ARM processor. The paper uses a number of DNN inference frameworks, including OpenVINO (for Intel CPUs only), TensorFlow Lite (TFLite), ONNX, and PyTorch with MobileNetV2, VGG-19, and DenseNet-121. The single-stream, multi-stream, and offline scenarios of the MLPerf Edge Inference benchmarks are used for measuring latency and throughput in our experiments. Our evaluation reveals that OpenVINO and TFLite are the most optimized frameworks for Intel CPUs and Raspberry Pi device, respectively. We observe no loss in accuracy except for the static quantization techniques. We also observed the benefits of using quantization for these optimized frameworks. For example, INT8-based quantized models deliver $3.3\times$ and $4\times$ better performance over FP32 using OpenVINO on Intel CPU and TFLite on Raspberry Pi device, respectively, for the MLPerf offline scenario. To the best of our knowledge, this paper is the first one that presents a unique characterization study characterizing the impact of quantization for a range of DNN inference frameworks -- including OpenVINO, TFLite, PyTorch, and ONNX -- on Intel x86 processors and Raspberry Pi device with ARM processor using the MLPerf Edge Inference benchmark methodology.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021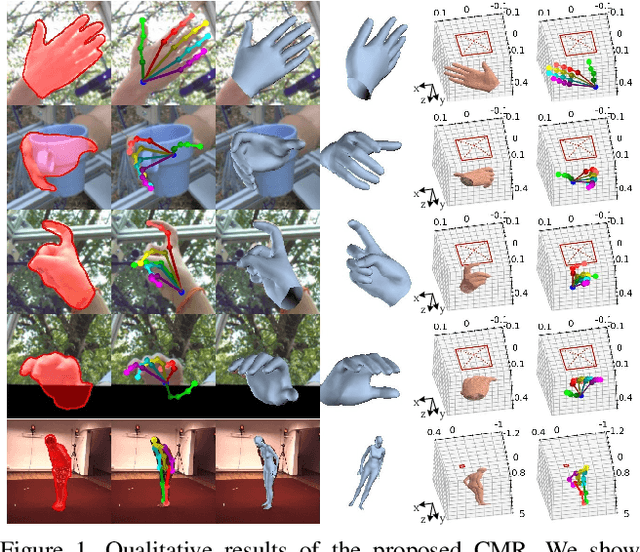
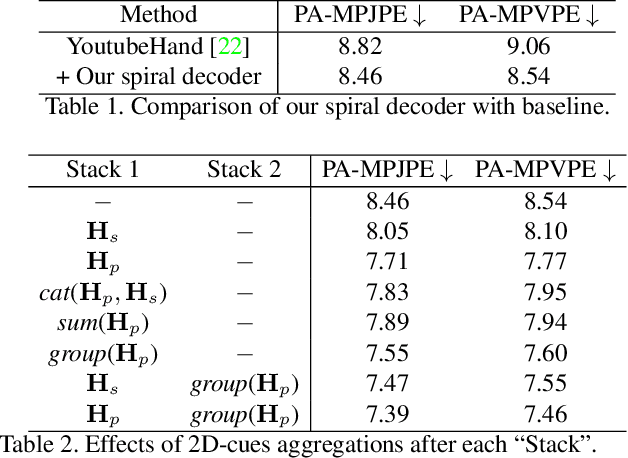
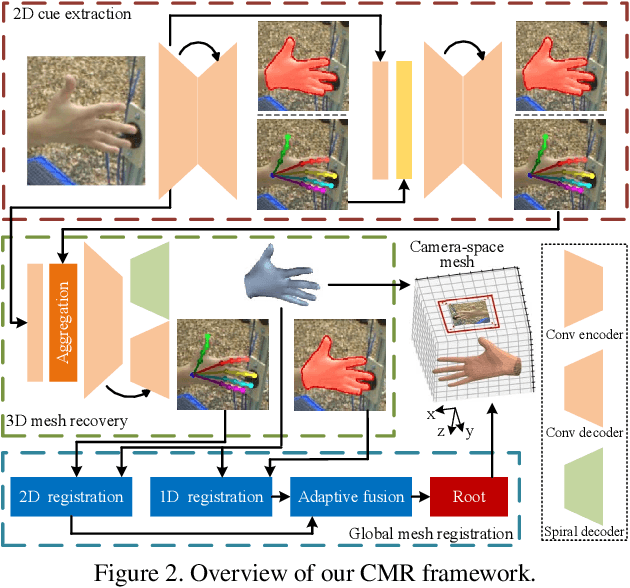
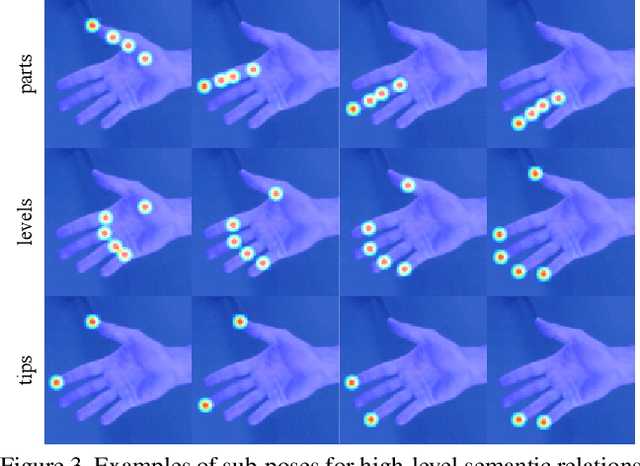
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.