 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Training with Hybrid GPU-based Compression
Sep 04, 2024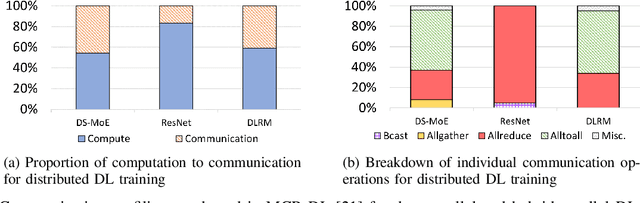
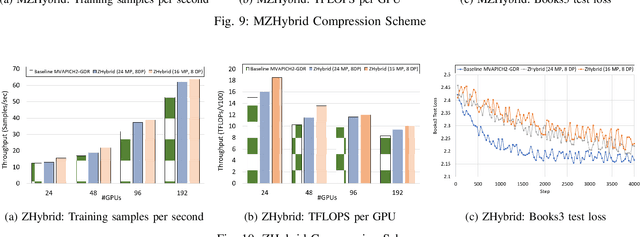
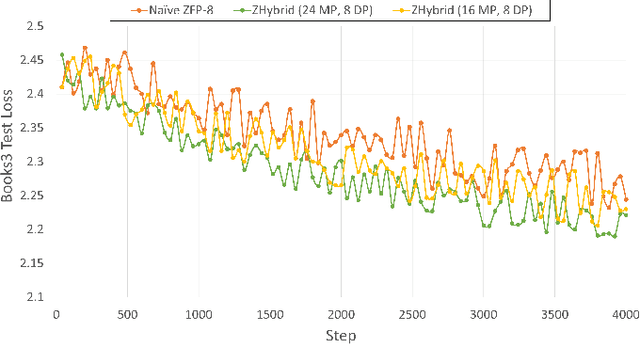
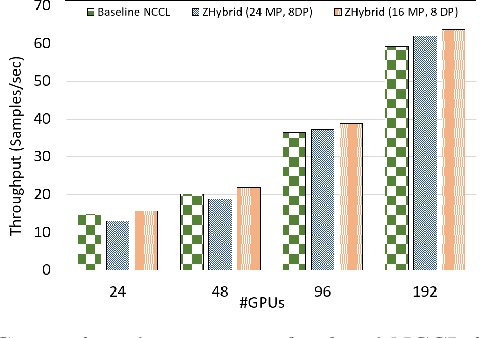
Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) are the three strategies widely adopted to enable fast and efficient Large Language Model (LLM) training. However, these approaches rely on data-intensive communication routines to collect, aggregate, and re-distribute gradients, activations, and other important model information, which pose significant overhead. Co-designed with GPU-based compression libraries, MPI libraries have been proven to reduce message size significantly, and leverage interconnect bandwidth, thus increasing training efficiency while maintaining acceptable accuracy. In this work, we investigate the efficacy of compression-assisted MPI collectives under the context of distributed LLM training using 3D parallelism and ZeRO optimizations. We scaled up to 192 V100 GPUs on the Lassen supercomputer. First, we enabled a na\"ive compression scheme across all collectives and observed a 22.5\% increase in TFLOPS per GPU and a 23.6\% increase in samples per second for GPT-NeoX-20B training. Nonetheless, such a strategy ignores the sparsity discrepancy among messages communicated in each parallelism degree, thus introducing more errors and causing degradation in training loss. Therefore, we incorporated hybrid compression settings toward each parallel dimension and adjusted the compression intensity accordingly. Given their low-rank structure (arXiv:2301.02654), we apply aggressive compression on gradients when performing DP All-reduce. We adopt milder compression to preserve precision while communicating activations, optimizer states, and model parameters in TP and PP. Using the adjusted hybrid compression scheme, we demonstrate a 17.3\% increase in TFLOPS per GPU and a 12.7\% increase in samples per second while reaching baseline loss convergence.
Flover: A Temporal Fusion Framework for Efficient Autoregressive Model Parallel Inference
May 24, 2023



In the rapidly evolving field of deep learning, the performance of model inference has become a pivotal aspect as models become more complex and are deployed in diverse applications. Among these, autoregressive models stand out due to their state-of-the-art performance in numerous generative tasks. These models, by design, harness a temporal dependency structure, where the current token's probability distribution is conditioned on preceding tokens. This inherently sequential characteristic, however, adheres to the Markov Chain assumption and lacks temporal parallelism, which poses unique challenges. Particularly in industrial contexts where inference requests, following a Poisson time distribution, necessitate diverse response lengths, this absence of parallelism is more profound. Existing solutions, such as dynamic batching and concurrent model instances, nevertheless, come with severe overheads and a lack of flexibility, these coarse-grained methods fall short of achieving optimal latency and throughput. To address these shortcomings, we propose Flavor -- a temporal fusion framework for efficient inference in autoregressive models, eliminating the need for heuristic settings and applies to a wide range of inference scenarios. By providing more fine-grained parallelism on the temporality of requests and employing an efficient memory shuffle algorithm, Flover achieves up to 11x faster inference on GPT models compared to the cutting-edge solutions provided by NVIDIA Triton FasterTransformer. Crucially, by leveraging the advanced tensor parallel technique, Flover proves efficacious across diverse computational landscapes, from single-GPU setups to multi-node scenarios, thereby offering robust performance optimization that transcends hardware boundaries.
Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version
Mar 09, 2023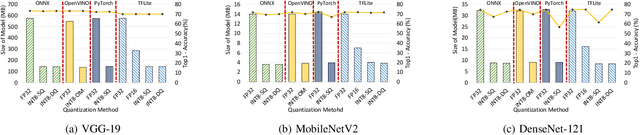

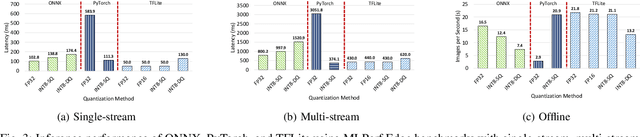
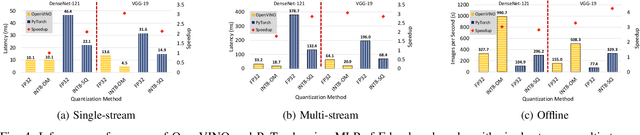
Quantization is a popular technique used in Deep Neural Networks (DNN) inference to reduce the size of models and improve the overall numerical performance by exploiting native hardware. This paper attempts to conduct an elaborate performance characterization of the benefits of using quantization techniques -- mainly FP16/INT8 variants with static and dynamic schemes -- using the MLPerf Edge Inference benchmarking methodology. The study is conducted on Intel x86 processors and Raspberry Pi device with ARM processor. The paper uses a number of DNN inference frameworks, including OpenVINO (for Intel CPUs only), TensorFlow Lite (TFLite), ONNX, and PyTorch with MobileNetV2, VGG-19, and DenseNet-121. The single-stream, multi-stream, and offline scenarios of the MLPerf Edge Inference benchmarks are used for measuring latency and throughput in our experiments. Our evaluation reveals that OpenVINO and TFLite are the most optimized frameworks for Intel CPUs and Raspberry Pi device, respectively. We observe no loss in accuracy except for the static quantization techniques. We also observed the benefits of using quantization for these optimized frameworks. For example, INT8-based quantized models deliver $3.3\times$ and $4\times$ better performance over FP32 using OpenVINO on Intel CPU and TFLite on Raspberry Pi device, respectively, for the MLPerf offline scenario. To the best of our knowledge, this paper is the first one that presents a unique characterization study characterizing the impact of quantization for a range of DNN inference frameworks -- including OpenVINO, TFLite, PyTorch, and ONNX -- on Intel x86 processors and Raspberry Pi device with ARM processor using the MLPerf Edge Inference benchmark methodology.
OMB-Py: Python Micro-Benchmarks for Evaluating Performance of MPI Libraries on HPC Systems
Oct 20, 2021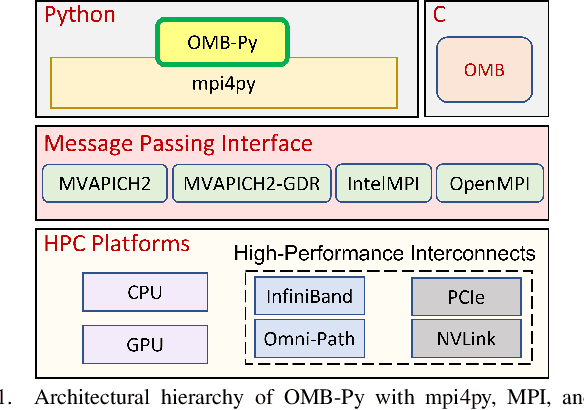
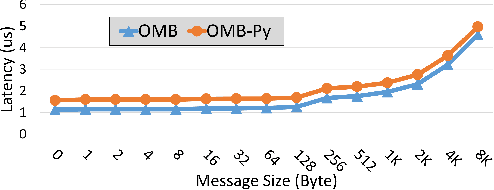
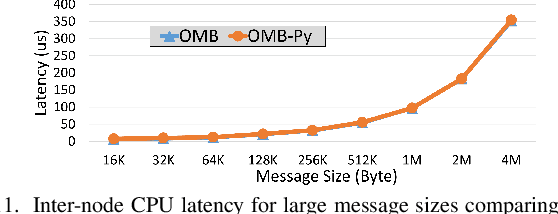
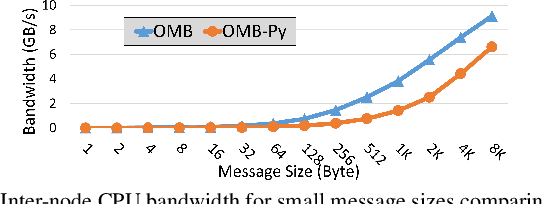
Python has become a dominant programming language for emerging areas like Machine Learning (ML), Deep Learning (DL), and Data Science (DS). An attractive feature of Python is that it provides easy-to-use programming interface while allowing library developers to enhance performance of their applications by harnessing the computing power offered by High Performance Computing (HPC) platforms. Efficient communication is key to scaling applications on parallel systems, which is typically enabled by the Message Passing Interface (MPI) standard and compliant libraries on HPC hardware. mpi4py is a Python-based communication library that provides an MPI-like interface for Python applications allowing application developers to utilize parallel processing elements including GPUs. However, there is currently no benchmark suite to evaluate communication performance of mpi4py -- and Python MPI codes in general -- on modern HPC systems. In order to bridge this gap, we propose OMB-Py -- Python extensions to the open-source OSU Micro-Benchmark (OMB) suite -- aimed to evaluate communication performance of MPI-based parallel applications in Python. To the best of our knowledge, OMB-Py is the first communication benchmark suite for parallel Python applications. OMB-Py consists of a variety of point-to-point and collective communication benchmark tests that are implemented for a range of popular Python libraries including NumPy, CuPy, Numba, and PyCUDA. We also provide Python implementation for several distributed ML algorithms as benchmarks to understand the potential gain in performance for ML/DL workloads. Our evaluation reveals that mpi4py introduces a small overhead when compared to native MPI libraries. We also evaluate the ML/DL workloads and report up to 106x speedup on 224 CPU cores compared to sequential execution. We plan to publicly release OMB-Py to benefit Python HPC community.