 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Training with Hybrid GPU-based Compression
Sep 04, 2024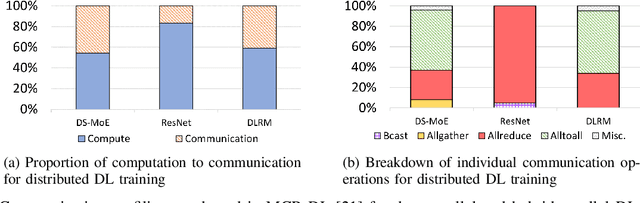
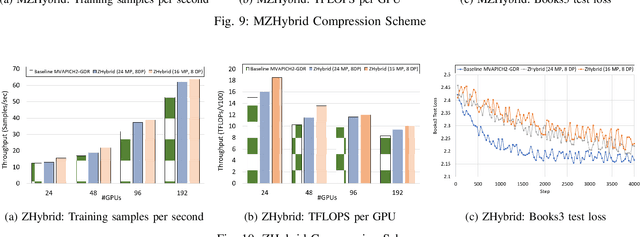
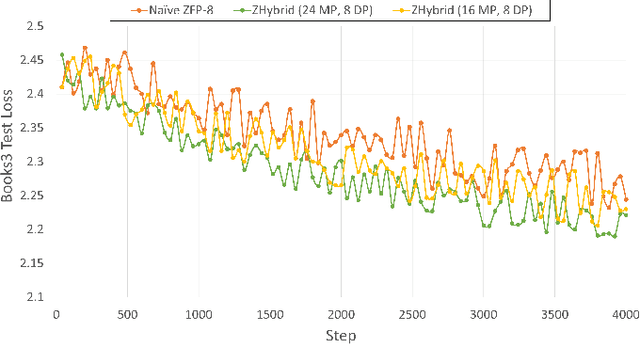
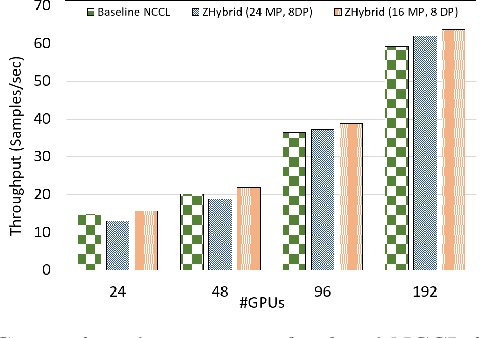
Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) are the three strategies widely adopted to enable fast and efficient Large Language Model (LLM) training. However, these approaches rely on data-intensive communication routines to collect, aggregate, and re-distribute gradients, activations, and other important model information, which pose significant overhead. Co-designed with GPU-based compression libraries, MPI libraries have been proven to reduce message size significantly, and leverage interconnect bandwidth, thus increasing training efficiency while maintaining acceptable accuracy. In this work, we investigate the efficacy of compression-assisted MPI collectives under the context of distributed LLM training using 3D parallelism and ZeRO optimizations. We scaled up to 192 V100 GPUs on the Lassen supercomputer. First, we enabled a na\"ive compression scheme across all collectives and observed a 22.5\% increase in TFLOPS per GPU and a 23.6\% increase in samples per second for GPT-NeoX-20B training. Nonetheless, such a strategy ignores the sparsity discrepancy among messages communicated in each parallelism degree, thus introducing more errors and causing degradation in training loss. Therefore, we incorporated hybrid compression settings toward each parallel dimension and adjusted the compression intensity accordingly. Given their low-rank structure (arXiv:2301.02654), we apply aggressive compression on gradients when performing DP All-reduce. We adopt milder compression to preserve precision while communicating activations, optimizer states, and model parameters in TP and PP. Using the adjusted hybrid compression scheme, we demonstrate a 17.3\% increase in TFLOPS per GPU and a 12.7\% increase in samples per second while reaching baseline loss convergence.
Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
Aug 30, 2024
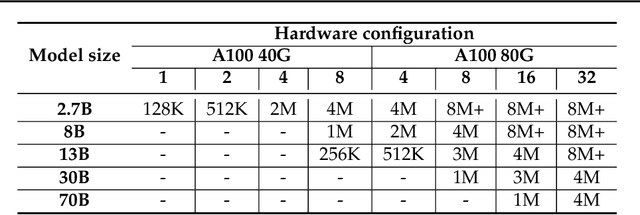
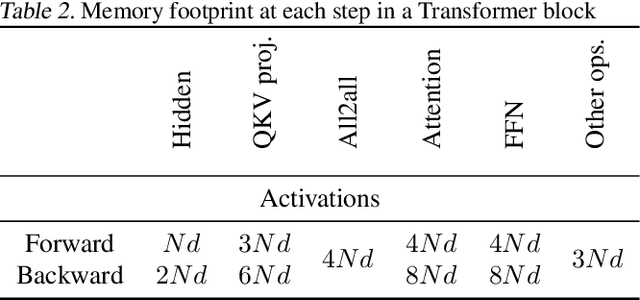

Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and greater complexity. Alternative approaches that introduce long context capabilities via downstream finetuning or adaptations impose significant design limitations. In this paper, we propose Fully Pipelined Distributed Transformer (FPDT) for efficiently training long-context LLMs with extreme hardware efficiency. For GPT and Llama models, we achieve a 16x increase in sequence length that can be trained on the same hardware compared to current state-of-the-art solutions. With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU. Our proposed FPDT is agnostic to existing training techniques and is proven to work efficiently across different LLM models.
Efficient MPI-based Communication for GPU-Accelerated Dask Applications
Jan 21, 2021
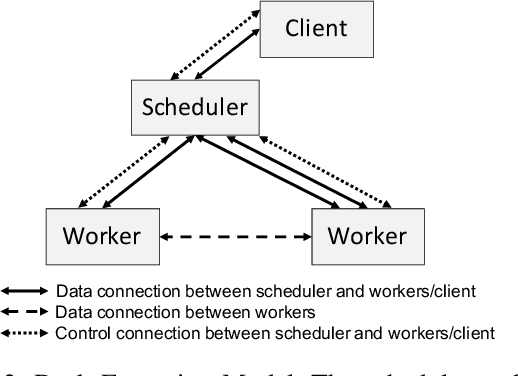
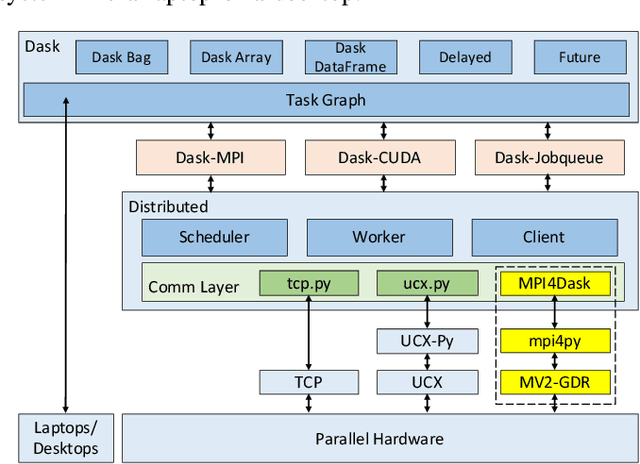

Dask is a popular parallel and distributed computing framework, which rivals Apache Spark to enable task-based scalable processing of big data. The Dask Distributed library forms the basis of this computing engine and provides support for adding new communication devices. It currently has two communication devices: one for TCP and the other for high-speed networks using UCX-Py -- a Cython wrapper to UCX. This paper presents the design and implementation of a new communication backend for Dask -- called MPI4Dask -- that is targeted for modern HPC clusters built with GPUs. MPI4Dask exploits mpi4py over MVAPICH2-GDR, which is a GPU-aware implementation of the Message Passing Interface (MPI) standard. MPI4Dask provides point-to-point asynchronous I/O communication coroutines, which are non-blocking concurrent operations defined using the async/await keywords from the Python's asyncio framework. Our latency and throughput comparisons suggest that MPI4Dask outperforms UCX by 6x for 1 Byte message and 4x for large messages (2 MBytes and beyond) respectively. We also conduct comparative performance evaluation of MPI4Dask with UCX using two benchmark applications: 1) sum of cuPy array with its transpose, and 2) cuDF merge. MPI4Dask speeds up the overall execution time of the two applications by an average of 3.47x and 3.11x respectively on an in-house cluster built with NVIDIA Tesla V100 GPUs for 1-6 Dask workers. We also perform scalability analysis of MPI4Dask against UCX for these applications on TACC's Frontera (GPU) system with upto 32 Dask workers on 32 NVIDIA Quadro RTX 5000 GPUs and 256 CPU cores. MPI4Dask speeds up the execution time for cuPy and cuDF applications by an average of 1.71x and 2.91x respectively for 1-32 Dask workers on the Frontera (GPU) system.