 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient MPI-based Communication for GPU-Accelerated Dask Applications
Paper and Code
Jan 21, 2021
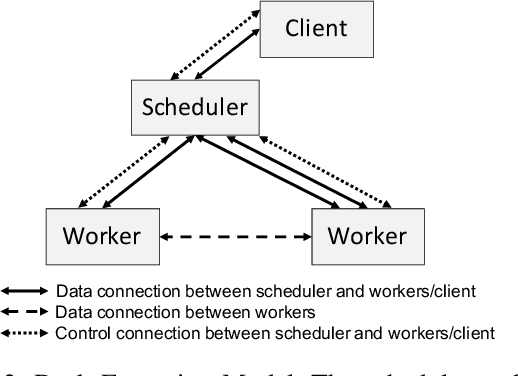
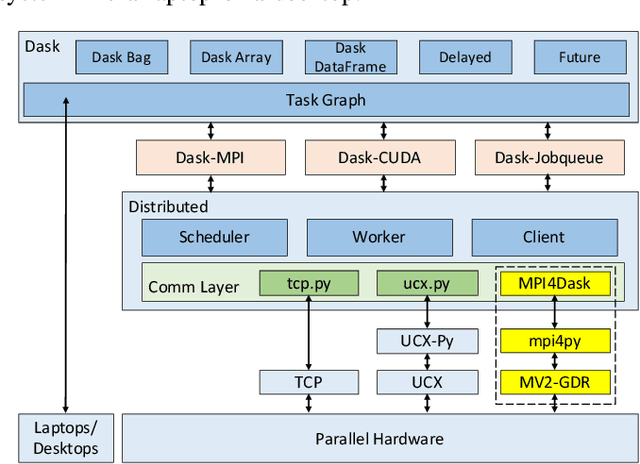

Dask is a popular parallel and distributed computing framework, which rivals Apache Spark to enable task-based scalable processing of big data. The Dask Distributed library forms the basis of this computing engine and provides support for adding new communication devices. It currently has two communication devices: one for TCP and the other for high-speed networks using UCX-Py -- a Cython wrapper to UCX. This paper presents the design and implementation of a new communication backend for Dask -- called MPI4Dask -- that is targeted for modern HPC clusters built with GPUs. MPI4Dask exploits mpi4py over MVAPICH2-GDR, which is a GPU-aware implementation of the Message Passing Interface (MPI) standard. MPI4Dask provides point-to-point asynchronous I/O communication coroutines, which are non-blocking concurrent operations defined using the async/await keywords from the Python's asyncio framework. Our latency and throughput comparisons suggest that MPI4Dask outperforms UCX by 6x for 1 Byte message and 4x for large messages (2 MBytes and beyond) respectively. We also conduct comparative performance evaluation of MPI4Dask with UCX using two benchmark applications: 1) sum of cuPy array with its transpose, and 2) cuDF merge. MPI4Dask speeds up the overall execution time of the two applications by an average of 3.47x and 3.11x respectively on an in-house cluster built with NVIDIA Tesla V100 GPUs for 1-6 Dask workers. We also perform scalability analysis of MPI4Dask against UCX for these applications on TACC's Frontera (GPU) system with upto 32 Dask workers on 32 NVIDIA Quadro RTX 5000 GPUs and 256 CPU cores. MPI4Dask speeds up the execution time for cuPy and cuDF applications by an average of 1.71x and 2.91x respectively for 1-32 Dask workers on the Frontera (GPU) system.