 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovenant-72B: Pre-Training a 72B LLM with Trustless Peers Over-the-Internet
Mar 10, 2026Recently, there has been increased interest in globally distributed training, which has the promise to both reduce training costs and democratize participation in building large-scale foundation models. However, existing models trained in a globally distributed manner are relatively small in scale and have only been trained with whitelisted participants. Therefore, they do not yet realize the full promise of democratized participation. In this report, we describe Covenant-72B, an LLM produced by the largest collaborative globally distributed pre-training run (in terms of both compute and model scale), which simultaneously allowed open, permissionless participation supported by a live blockchain protocol. We utilized a state-of-the-art communication-efficient optimizer, SparseLoCo, supporting dynamic participation with peers joining and leaving freely. Our model, pre-trained on approximately 1.1T tokens, performs competitively with fully centralized models pre-trained on similar or higher compute budgets, demonstrating that fully democratized, non-whitelisted participation is not only feasible, but can be achieved at unprecedented scale for a globally distributed pre-training run.
Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space
Oct 06, 2025Multi-headed Attention's (MHA) quadratic compute and linearly growing KV-cache make long-context transformers expensive to train and serve. Prior works such as Grouped Query Attention (GQA) and Multi-Latent Attention (MLA) shrink the cache, speeding decode, but leave compute, which determines prefill and training speed, largely unchanged. We introduce Compressed Convolutional Attention (CCA), a novel attention method which down-projects queries, keys, and values and performs the entire attention operation inside the shared latent space. This simple design dramatically cuts parameters, KV-cache, and FLOPs all at once by the desired compression factor. Because CCA is orthogonal to head-sharing, we combine the two to form Compressed Convolutional Grouped Query Attention (CCGQA), which further tightens the compute-bandwidth Pareto frontier so that users can tune compression toward either FLOP or memory limits without sacrificing quality. Experiments show that CCGQA consistently outperforms both GQA and MLA at equal KV-cache compression on dense and MoE models. Additionally, we show that CCGQA outperforms all other attention methods on MoE models with half the KV-cache of GQA and MLA, achieving an 8x KV-cache compression with no drop in performance compared to standard MHA. CCA and CCGQA also dramatically reduce the FLOP cost of attention which leads to substantially faster training and prefill than existing methods. On H100 GPUs, our fused CCA/CCGQA kernel reduces prefill latency by about 1.7x at a sequence length of 16k relative to MHA, and accelerates backward by about 1.3x.
PyLO: Towards Accessible Learned Optimizers in PyTorch
Jun 12, 2025Learned optimizers have been an active research topic over the past decade, with increasing progress toward practical, general-purpose optimizers that can serve as drop-in replacements for widely used methods like Adam. However, recent advances -- such as VeLO, which was meta-trained for 4000 TPU-months -- remain largely inaccessible to the broader community, in part due to their reliance on JAX and the absence of user-friendly packages for applying the optimizers after meta-training. To address this gap, we introduce PyLO, a PyTorch-based library that brings learned optimizers to the broader machine learning community through familiar, widely adopted workflows. Unlike prior work focused on synthetic or convex tasks, our emphasis is on applying learned optimization to real-world large-scale pre-training tasks. Our release includes a CUDA-accelerated version of the small_fc_lopt learned optimizer architecture from (Metz et al., 2022a), delivering substantial speedups -- from 39.36 to 205.59 samples/sec throughput for training ViT B/16 with batch size 32. PyLO also allows us to easily combine learned optimizers with existing optimization tools such as learning rate schedules and weight decay. When doing so, we find that learned optimizers can substantially benefit. Our code is available at https://github.com/Belilovsky-Lab/pylo
Robin: a Suite of Multi-Scale Vision-Language Models and the CHIRP Evaluation Benchmark
Jan 16, 2025



The proliferation of Vision-Language Models (VLMs) in the past several years calls for rigorous and comprehensive evaluation methods and benchmarks. This work analyzes existing VLM evaluation techniques, including automated metrics, AI-based assessments, and human evaluations across diverse tasks. We first introduce Robin - a novel suite of VLMs that we built by combining Large Language Models (LLMs) and Vision Encoders (VEs) at multiple scales, and use Robin to identify shortcomings of current evaluation approaches across scales. Next, to overcome the identified limitations, we introduce CHIRP - a new long form response benchmark we developed for more robust and complete VLM evaluation. We provide open access to the Robin training code, model suite, and CHIRP benchmark to promote reproducibility and advance VLM research.
Scaling Large Language Model Training on Frontier with Low-Bandwidth Partitioning
Jan 08, 2025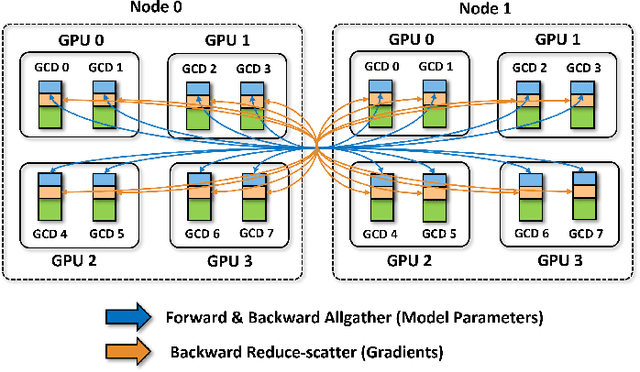
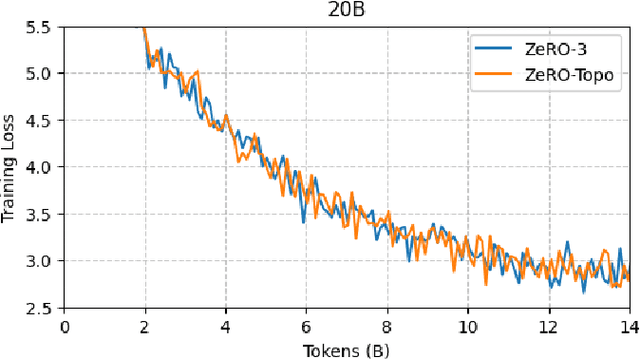
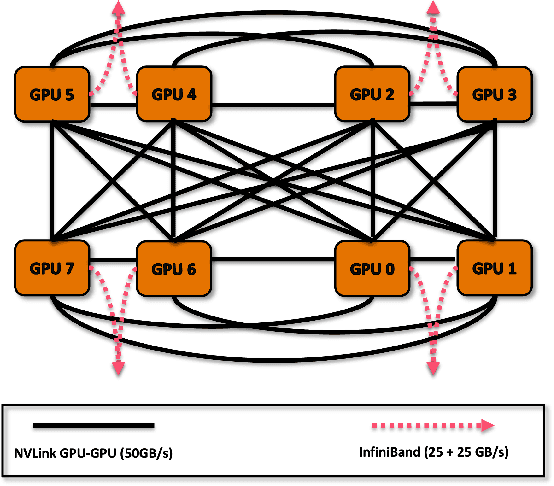
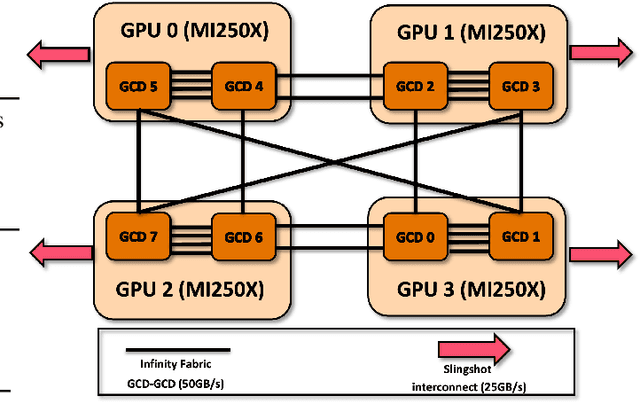
Scaling up Large Language Model(LLM) training involves fitting a tremendous amount of training parameters across a limited number of workers. However, methods like ZeRO-3 that drastically reduce GPU memory pressure often incur heavy communication to ensure global synchronization and consistency. Established efforts such as ZeRO++ use secondary partitions to avoid inter-node communications, given that intra-node GPU-GPU transfer generally has more bandwidth and lower latency than inter-node connections. However, as more capable infrastructure like Frontier, equipped with AMD GPUs, emerged with impressive computing capability, there is a need for investigations on the hardware topology and to develop targeted strategies to improve training efficiency. In this work, we propose a collection of communication and optimization strategies for ZeRO++ to reduce communication costs and improve memory utilization. In this paper, we propose a 3-level hierarchical partitioning specifically for the current Top-1 supercomputing cluster, Frontier, which aims at leveraging various bandwidths across layers of communications (GCD-GCD, GPU-GPU, and inter-node) to reduce communication overhead. For a 20B GPT model, we observe a 1.71x increase in TFLOPS per GPU when compared with ZeRO++ up to 384 GCDs and a scaling efficiency of 0.94 for up to 384 GCDs. To the best of our knowledge, our work is also the first effort to efficiently optimize LLM workloads on Frontier AMD GPUs.
The Zamba2 Suite: Technical Report
Nov 22, 2024


In this technical report, we present the Zamba2 series -- a suite of 1.2B, 2.7B, and 7.4B parameter hybrid Mamba2-transformer models that achieve state of the art performance against the leading open-weights models of their class, while achieving substantial gains in inference latency, throughput, and memory efficiency. The Zamba2 series builds upon our initial work with Zamba1-7B, optimizing its architecture, training and annealing datasets, and training for up to three trillion tokens. We provide open-source weights for all models of the Zamba2 series as well as instruction-tuned variants that are strongly competitive against comparable instruct-tuned models of their class. We additionally open-source the pretraining dataset, which we call Zyda-2, used to train the Zamba2 series of models. The models and datasets used in this work are openly available at https://huggingface.co/Zyphra
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Zyda-2: a 5 Trillion Token High-Quality Dataset
Nov 09, 2024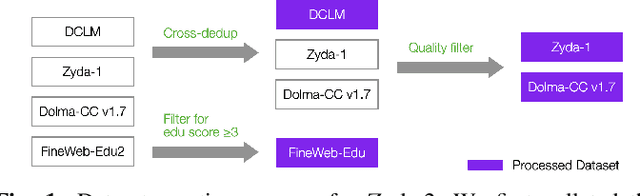
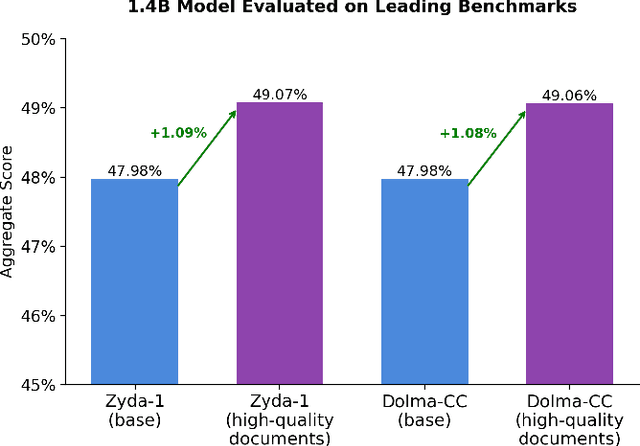
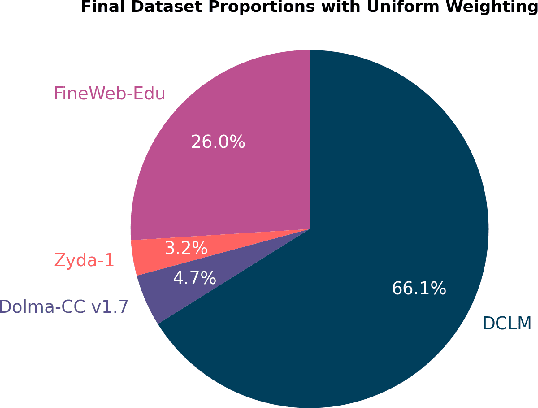
In this technical report, we present Zyda-2: a five trillion token dataset for language model pretraining. Zyda-2 was used to train our Zamba2 series of models which are state-of-the-art for their weight class. We build Zyda-2 by collating high-quality open-source tokens such as FineWeb and DCLM, then distilling them to the highest-quality subset via cross-deduplication and model-based quality filtering. Zyda-2 is released under a permissive open license, and is available at https://huggingface.co/datasets/Zyphra/Zyda-2
Accelerating Large Language Model Training with Hybrid GPU-based Compression
Sep 04, 2024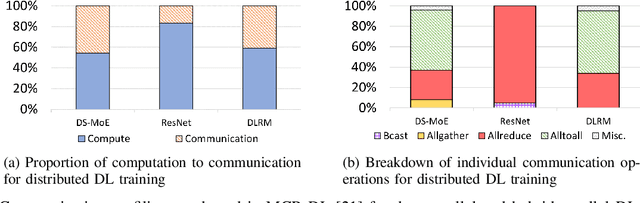
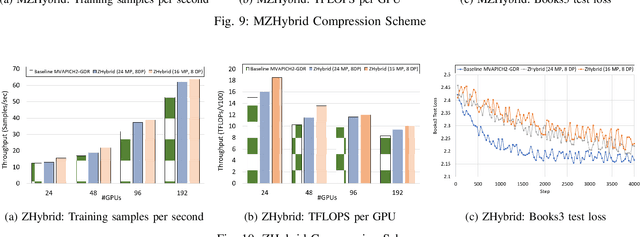
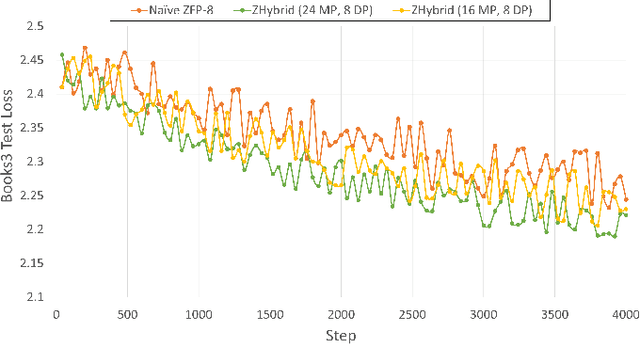
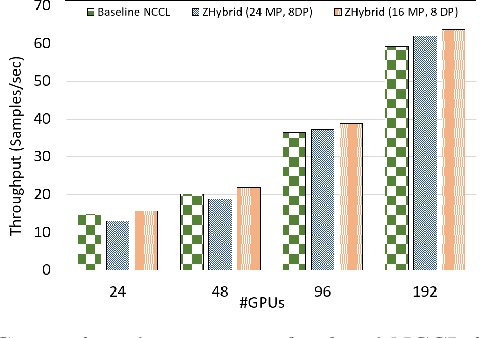
Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) are the three strategies widely adopted to enable fast and efficient Large Language Model (LLM) training. However, these approaches rely on data-intensive communication routines to collect, aggregate, and re-distribute gradients, activations, and other important model information, which pose significant overhead. Co-designed with GPU-based compression libraries, MPI libraries have been proven to reduce message size significantly, and leverage interconnect bandwidth, thus increasing training efficiency while maintaining acceptable accuracy. In this work, we investigate the efficacy of compression-assisted MPI collectives under the context of distributed LLM training using 3D parallelism and ZeRO optimizations. We scaled up to 192 V100 GPUs on the Lassen supercomputer. First, we enabled a na\"ive compression scheme across all collectives and observed a 22.5\% increase in TFLOPS per GPU and a 23.6\% increase in samples per second for GPT-NeoX-20B training. Nonetheless, such a strategy ignores the sparsity discrepancy among messages communicated in each parallelism degree, thus introducing more errors and causing degradation in training loss. Therefore, we incorporated hybrid compression settings toward each parallel dimension and adjusted the compression intensity accordingly. Given their low-rank structure (arXiv:2301.02654), we apply aggressive compression on gradients when performing DP All-reduce. We adopt milder compression to preserve precision while communicating activations, optimizer states, and model parameters in TP and PP. Using the adjusted hybrid compression scheme, we demonstrate a 17.3\% increase in TFLOPS per GPU and a 12.7\% increase in samples per second while reaching baseline loss convergence.
Demystifying the Communication Characteristics for Distributed Transformer Models
Aug 19, 2024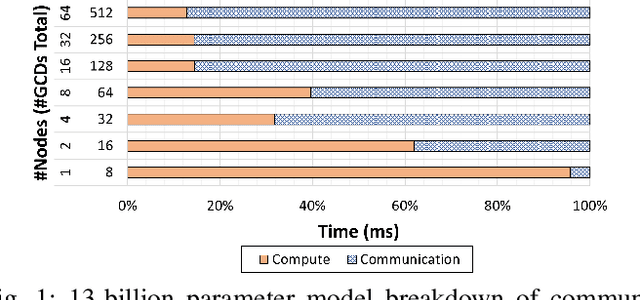
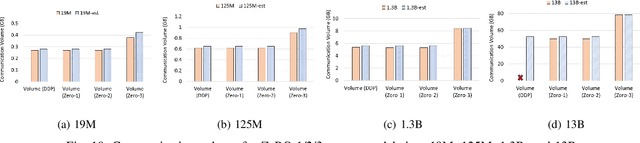
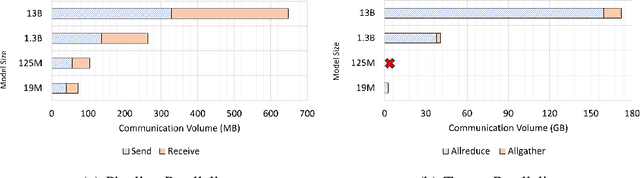
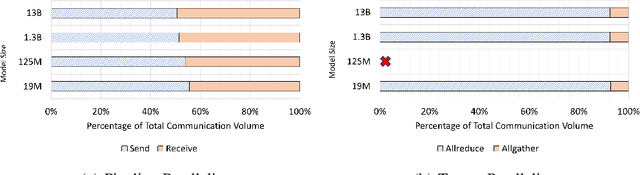
Deep learning (DL) models based on the transformer architecture have revolutionized many DL applications such as large language models (LLMs), vision transformers, audio generation, and time series prediction. Much of this progress has been fueled by distributed training, yet distributed communication remains a substantial bottleneck to training progress. This paper examines the communication behavior of transformer models - that is, how different parallelism schemes used in multi-node/multi-GPU DL Training communicate data in the context of transformers. We use GPT-based language models as a case study of the transformer architecture due to their ubiquity. We validate the empirical results obtained from our communication logs using analytical models. At a high level, our analysis reveals a need to optimize small message point-to-point communication further, correlations between sequence length, per-GPU throughput, model size, and optimizations used, and where to potentially guide further optimizations in framework and HPC middleware design and optimization.