Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZyda-2: a 5 Trillion Token High-Quality Dataset
Paper and Code
Nov 09, 2024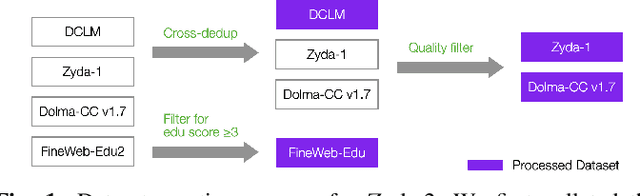
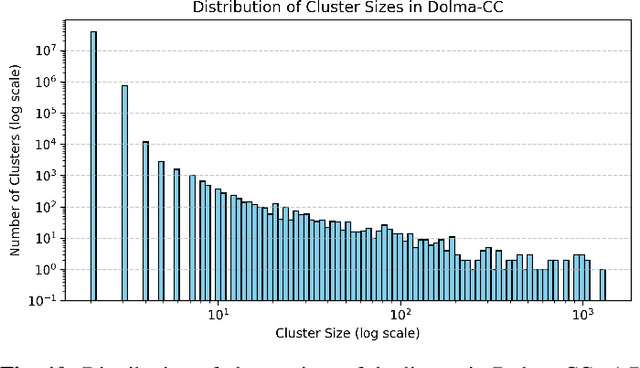
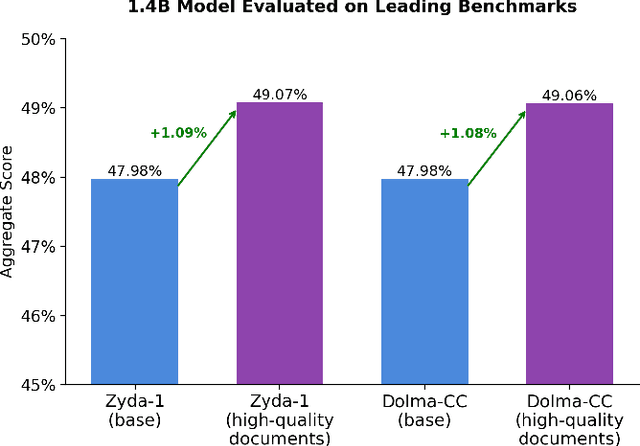
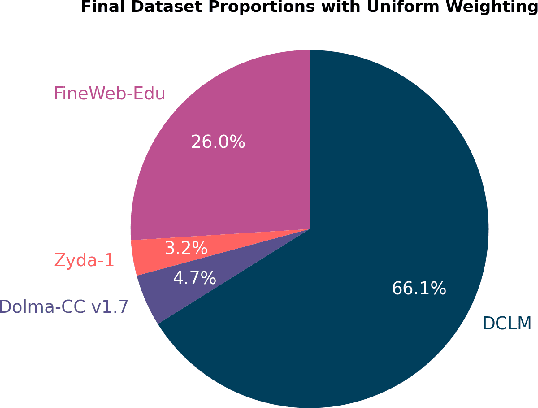
In this technical report, we present Zyda-2: a five trillion token dataset for language model pretraining. Zyda-2 was used to train our Zamba2 series of models which are state-of-the-art for their weight class. We build Zyda-2 by collating high-quality open-source tokens such as FineWeb and DCLM, then distilling them to the highest-quality subset via cross-deduplication and model-based quality filtering. Zyda-2 is released under a permissive open license, and is available at https://huggingface.co/datasets/Zyphra/Zyda-2
* initial upload 11/08/24
View paper on