 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZamba2-VL Technical Report
May 29, 2026We present Zamba2-VL, a suite of vision-language models built on Zamba2, a hybrid language-model architecture combining Mamba2 state-space layers with a small number of shared transformer blocks. Across a broad range of image understanding, reasoning, OCR, grounding, and counting benchmarks, Zamba2-VL is competitive with leading Transformer-based open-weight VLMs of comparable scale, including the Molmo2, Qwen3-VL, and InternVL3.5 families, and substantially outperforms prior SSM-based and hybrid VLMs such as VL-Mamba, Cobra, and mmMamba. Inheriting the near-linear prefill compute and small, near-constant recurrent state of its Zamba2 backbone, Zamba2-VL delivers roughly an order of magnitude lower time-to-first-token (TTFT) than these Transformer baselines at matched parameter scale, with the efficiency gap most pronounced at the smaller 1.2B and 2.7B scales most relevant to on-device and edge deployment. We release three models -- 1.2B, 2.7B, and 7B -- together with inference code at https://huggingface.co/collections/Zyphra/zamba2-vl.
Online Vector Quantized Attention
Feb 03, 2026Standard sequence mixing layers used in language models struggle to balance efficiency and performance. Self-attention performs well on long context tasks but has expensive quadratic compute and linear memory costs, while linear attention and SSMs use only linear compute and constant memory but struggle with long context processing. In this paper, we develop a sequence mixing layer that aims to find a better compromise between memory-compute costs and long-context processing, which we call online vector-quantized (OVQ) attention. OVQ-attention requires linear compute costs and constant memory, but, unlike linear attention and SSMs, it uses a sparse memory update that allows it to greatly increase the size of its memory state and, consequently, memory capacity. We develop a theoretical basis for OVQ-attention based on Gaussian mixture regression, and we test it on a variety of synthetic long context tasks and on long context language modeling. OVQ-attention shows significant improvements over linear attention baselines and the original VQ-attention, on which OVQ-attention was inspired. It demonstrates competitive, and sometimes identical, performance to strong self-attention baselines up 64k sequence length, despite using a small fraction of the memory of full self-attention.
Equivalence of Personalized PageRank and Successor Representations
Dec 31, 2025The hippocampus appears to implement two core but highly distinct functions in the brain: long term memory retrieval and planning and spatial navigation. Naively, these functions appear very different algorithmically. In this short note, we demonstrate that two powerful algorithms that have each independently been proposed to underlie the hippocampal operation for each function -- personalized page-rank for memory retrieval, and successor representations for planning and navigation, are in fact isomorphic and utilize the same underlying representation -- the stationary distribution of a random walk on a graph. We hypothesize that the core computational function of the hippocampus is to compute this representation on arbitrary input graphs.
Generalising E-prop to Deep Networks
Dec 30, 2025Recurrent networks are typically trained with backpropagation through time (BPTT). However, BPTT requires storing the history of all states in the network and then replaying them sequentially backwards in time. This computation appears extremely implausible for the brain to implement. Real Time Recurrent Learning (RTRL) proposes an mathematically equivalent alternative where gradient information is propagated forwards in time locally alongside the regular forward pass, however it has significantly greater computational complexity than BPTT which renders it impractical for large networks. E-prop proposes an approximation of RTRL which reduces its complexity to the level of BPTT while maintaining a purely online forward update which can be implemented by an eligibility trace at each synapse. However, works on RTRL and E-prop ubiquitously investigate learning in a single layer with recurrent dynamics. However, learning in the brain spans multiple layers and consists of both hierarchal dynamics in depth as well as time. In this mathematical note, we extend the E-prop framework to handle arbitrarily deep networks, deriving a novel recursion relationship across depth which extends the eligibility traces of E-prop to deeper layers. Our results thus demonstrate an online learning algorithm can perform accurate credit assignment across both time and depth simultaneously, allowing the training of deep recurrent networks without backpropagation through time.
Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space
Oct 06, 2025Multi-headed Attention's (MHA) quadratic compute and linearly growing KV-cache make long-context transformers expensive to train and serve. Prior works such as Grouped Query Attention (GQA) and Multi-Latent Attention (MLA) shrink the cache, speeding decode, but leave compute, which determines prefill and training speed, largely unchanged. We introduce Compressed Convolutional Attention (CCA), a novel attention method which down-projects queries, keys, and values and performs the entire attention operation inside the shared latent space. This simple design dramatically cuts parameters, KV-cache, and FLOPs all at once by the desired compression factor. Because CCA is orthogonal to head-sharing, we combine the two to form Compressed Convolutional Grouped Query Attention (CCGQA), which further tightens the compute-bandwidth Pareto frontier so that users can tune compression toward either FLOP or memory limits without sacrificing quality. Experiments show that CCGQA consistently outperforms both GQA and MLA at equal KV-cache compression on dense and MoE models. Additionally, we show that CCGQA outperforms all other attention methods on MoE models with half the KV-cache of GQA and MLA, achieving an 8x KV-cache compression with no drop in performance compared to standard MHA. CCA and CCGQA also dramatically reduce the FLOP cost of attention which leads to substantially faster training and prefill than existing methods. On H100 GPUs, our fused CCA/CCGQA kernel reduces prefill latency by about 1.7x at a sequence length of 16k relative to MHA, and accelerates backward by about 1.3x.
Mixture-of-PageRanks: Replacing Long-Context with Real-Time, Sparse GraphRAG
Dec 08, 2024



Recent advances have extended the context window of frontier LLMs dramatically, from a few thousand tokens up to millions, enabling entire books and codebases to fit into context. However, the compute costs of inferencing long-context LLMs are massive and often prohibitive in practice. RAG offers an efficient and effective alternative: retrieve and process only the subset of the context most important for the current task. Although promising, recent work applying RAG to long-context tasks has two core limitations: 1) there has been little focus on making the RAG pipeline compute efficient, and 2) such works only test on simple QA tasks, and their performance on more challenging tasks is unclear. To address this, we develop an algorithm based on PageRank, a graph-based retrieval algorithm, which we call mixture-of-PageRanks (MixPR). MixPR uses a mixture of PageRank-based graph-retrieval algorithms implemented using sparse matrices for efficent, cheap retrieval that can deal with a variety of complex tasks. Our MixPR retriever achieves state-of-the-art results across a wide range of long-context benchmark tasks, outperforming both existing RAG methods, specialized retrieval architectures, and long-context LLMs despite being far more compute efficient. Due to using sparse embeddings, our retriever is extremely compute efficient, capable of embedding and retrieving millions of tokens within a few seconds and runs entirely on CPU.
The Zamba2 Suite: Technical Report
Nov 22, 2024


In this technical report, we present the Zamba2 series -- a suite of 1.2B, 2.7B, and 7.4B parameter hybrid Mamba2-transformer models that achieve state of the art performance against the leading open-weights models of their class, while achieving substantial gains in inference latency, throughput, and memory efficiency. The Zamba2 series builds upon our initial work with Zamba1-7B, optimizing its architecture, training and annealing datasets, and training for up to three trillion tokens. We provide open-source weights for all models of the Zamba2 series as well as instruction-tuned variants that are strongly competitive against comparable instruct-tuned models of their class. We additionally open-source the pretraining dataset, which we call Zyda-2, used to train the Zamba2 series of models. The models and datasets used in this work are openly available at https://huggingface.co/Zyphra
Zyda-2: a 5 Trillion Token High-Quality Dataset
Nov 09, 2024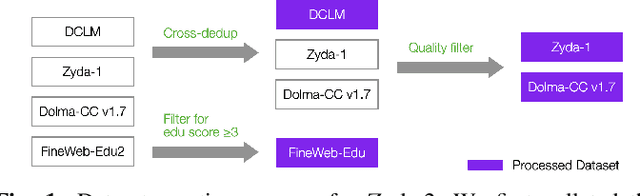
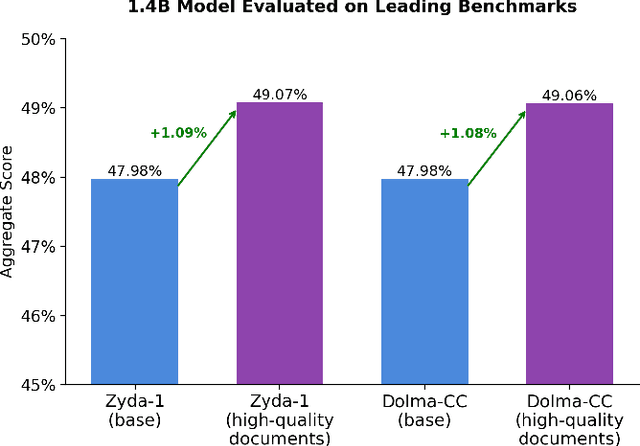
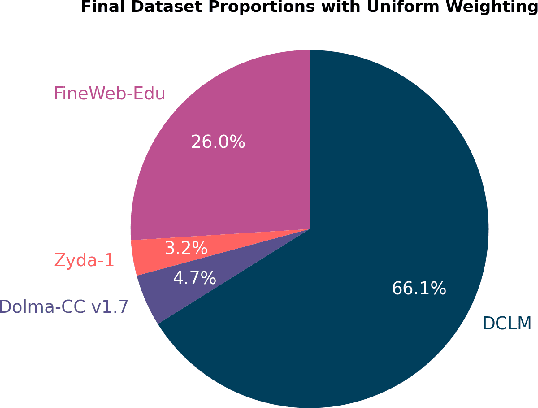
In this technical report, we present Zyda-2: a five trillion token dataset for language model pretraining. Zyda-2 was used to train our Zamba2 series of models which are state-of-the-art for their weight class. We build Zyda-2 by collating high-quality open-source tokens such as FineWeb and DCLM, then distilling them to the highest-quality subset via cross-deduplication and model-based quality filtering. Zyda-2 is released under a permissive open license, and is available at https://huggingface.co/datasets/Zyphra/Zyda-2
Exploring Action-Centric Representations Through the Lens of Rate-Distortion Theory
Sep 13, 2024Organisms have to keep track of the information in the environment that is relevant for adaptive behaviour. Transmitting information in an economical and efficient way becomes crucial for limited-resourced agents living in high-dimensional environments. The efficient coding hypothesis claims that organisms seek to maximize the information about the sensory input in an efficient manner. Under Bayesian inference, this means that the role of the brain is to efficiently allocate resources in order to make predictions about the hidden states that cause sensory data. However, neither of those frameworks accounts for how that information is exploited downstream, leaving aside the action-oriented role of the perceptual system. Rate-distortion theory, which defines optimal lossy compression under constraints, has gained attention as a formal framework to explore goal-oriented efficient coding. In this work, we explore action-centric representations in the context of rate-distortion theory. We also provide a mathematical definition of abstractions and we argue that, as a summary of the relevant details, they can be used to fix the content of action-centric representations. We model action-centric representations using VAEs and we find that such representations i) are efficient lossy compressions of the data; ii) capture the task-dependent invariances necessary to achieve successful behaviour; and iii) are not in service of reconstructing the data. Thus, we conclude that full reconstruction of the data is rarely needed to achieve optimal behaviour, consistent with a teleological approach to perception.
Tree Attention: Topology-aware Decoding for Long-Context Attention on GPU clusters
Aug 09, 2024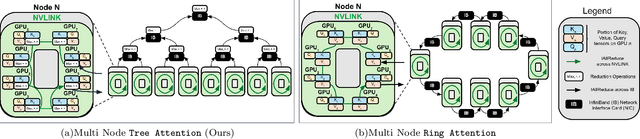
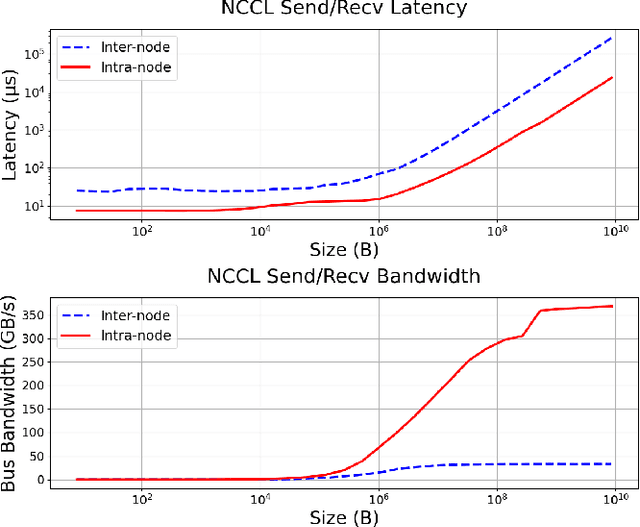
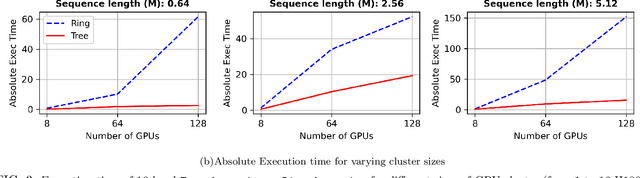
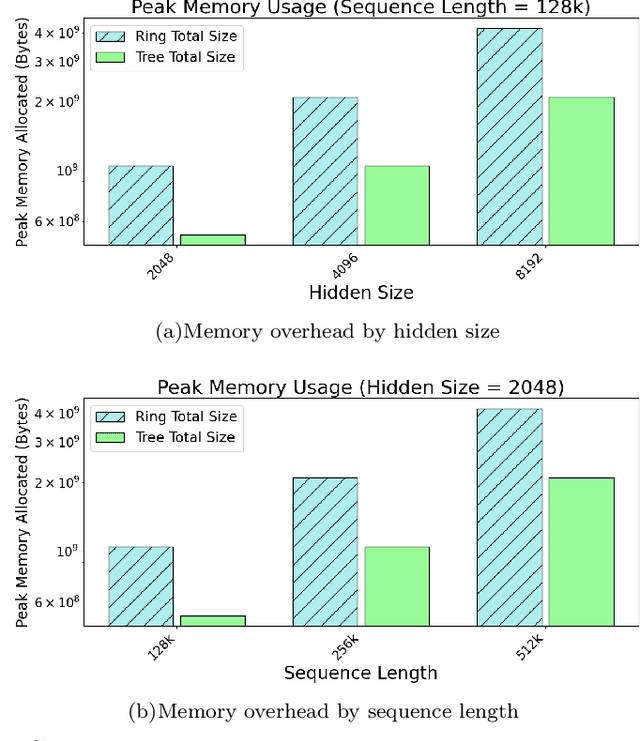
Self-attention is the core mathematical operation of modern transformer architectures and is also a significant computational bottleneck due to its quadratic complexity in the sequence length. In this work, we derive the scalar energy function whose gradient computes the self-attention block, thus elucidating the theoretical underpinnings of self-attention, providing a Bayesian interpretation of the operation and linking it closely with energy-based models such as Hopfield Networks. Our formulation reveals that the reduction across the sequence axis can be efficiently computed in parallel through a tree reduction. Our algorithm, for parallelizing attention computation across multiple GPUs enables cross-device decoding to be performed asymptotically faster (up to 8x faster in our experiments) than alternative approaches such as Ring Attention, while also requiring significantly less communication volume and incurring 2x less peak memory. Our code is publicly available here: \url{https://github.com/Zyphra/tree_attention}.