 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Zamba2 Suite: Technical Report
Nov 22, 2024In this technical report, we present the Zamba2 series -- a suite of 1.2B, 2.7B, and 7.4B parameter hybrid Mamba2-transformer models that achieve state of the art performance against the leading open-weights models of their class, while achieving substantial gains in inference latency, throughput, and memory efficiency. The Zamba2 series builds upon our initial work with Zamba1-7B, optimizing its architecture, training and annealing datasets, and training for up to three trillion tokens. We provide open-source weights for all models of the Zamba2 series as well as instruction-tuned variants that are strongly competitive against comparable instruct-tuned models of their class. We additionally open-source the pretraining dataset, which we call Zyda-2, used to train the Zamba2 series of models. The models and datasets used in this work are openly available at https://huggingface.co/Zyphra
Zyda: A 1.3T Dataset for Open Language Modeling
Jun 04, 2024The size of large language models (LLMs) has scaled dramatically in recent years and their computational and data requirements have surged correspondingly. State-of-the-art language models, even at relatively smaller sizes, typically require training on at least a trillion tokens. This rapid advancement has eclipsed the growth of open-source datasets available for large-scale LLM pretraining. In this paper, we introduce Zyda (Zyphra Dataset), a dataset under a permissive license comprising 1.3 trillion tokens, assembled by integrating several major respected open-source datasets into a single, high-quality corpus. We apply rigorous filtering and deduplication processes, both within and across datasets, to maintain and enhance the quality derived from the original datasets. Our evaluations show that Zyda not only competes favorably with other open datasets like Dolma, FineWeb, and RefinedWeb, but also substantially improves the performance of comparable models from the Pythia suite. Our rigorous data processing methods significantly enhance Zyda's effectiveness, outperforming even the best of its constituent datasets when used independently.
Zamba: A Compact 7B SSM Hybrid Model
May 26, 2024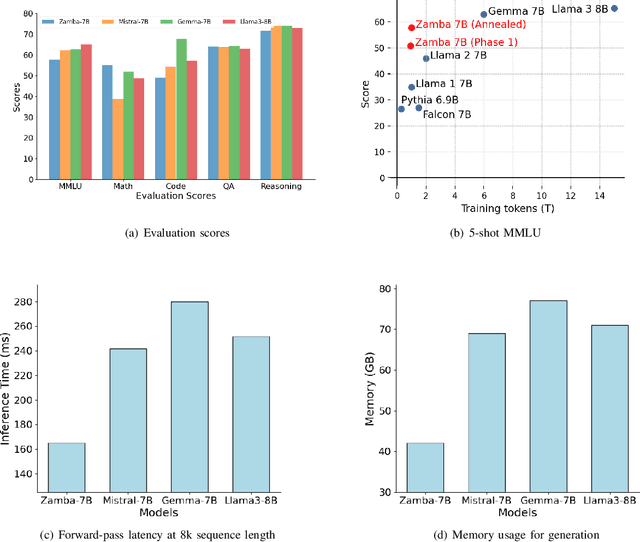
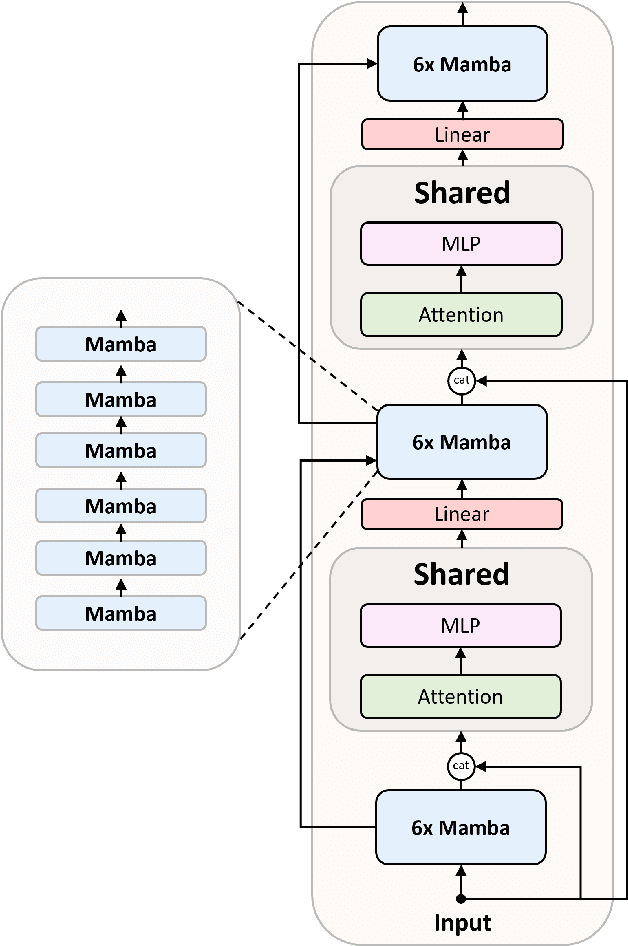

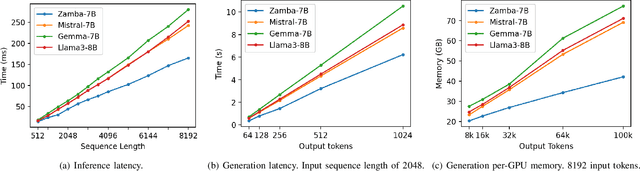
In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model which achieves competitive performance against leading open-weight models at a comparable scale. Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost. Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for generation of long sequences. Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and annealing phases.