 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cosine Decay: On the effectiveness of Infinite Learning Rate Schedule for Continual Pre-training
Mar 06, 2025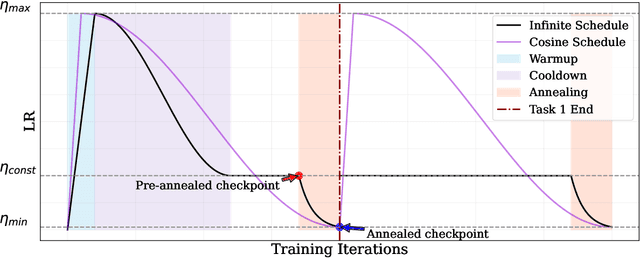

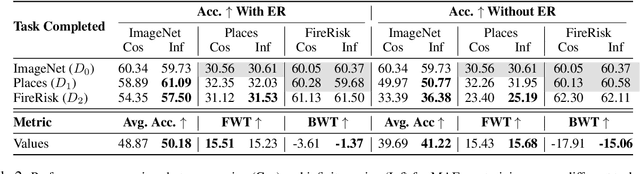
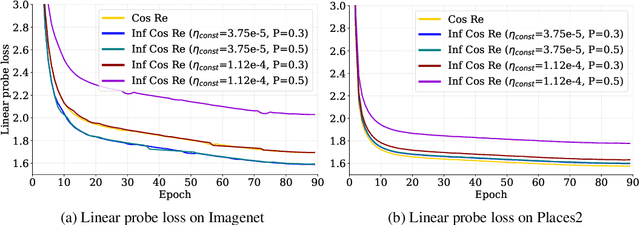
The ever-growing availability of unlabeled data presents both opportunities and challenges for training artificial intelligence systems. While self-supervised learning (SSL) has emerged as a powerful paradigm for extracting meaningful representations from vast amounts of unlabeled data, existing methods still struggle to adapt to the non-stationary, non-IID nature of real-world data streams without forgetting previously learned knowledge. Recent works have adopted a repeated cosine annealing schedule for large-scale continual pre-training; however, these schedules (1) inherently cause forgetting during the re-warming phase and (2) have not been systematically compared to existing continual SSL methods. In this work, we systematically compare the widely used cosine schedule with the recently proposed infinite learning rate schedule and empirically find the latter to be a more effective alternative. Our extensive empirical evaluation across diverse image and language datasets demonstrates that the infinite learning rate schedule consistently enhances continual pre-training performance compared to a repeated cosine decay without being restricted to a fixed iteration budget. For instance, in a small-scale MAE pre-training setup, it outperforms several strong baselines from the literature. We then scale up our experiments to larger MAE pre-training and autoregressive language model pre-training. Our results show that the infinite learning rate schedule remains effective at scale, surpassing repeated cosine decay for both MAE pre-training and zero-shot LM benchmarks.
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Jun 06, 2024



Predictable behavior from scaling advanced AI systems is an extremely desirable property. Although a well-established literature exists on how pretraining performance scales, the literature on how particular downstream capabilities scale is significantly muddier. In this work, we take a step back and ask: why has predicting specific downstream capabilities with scale remained elusive? While many factors are certainly responsible, we identify a new factor that makes modeling scaling behavior on widely used multiple-choice question-answering benchmarks challenging. Using five model families and twelve well-established multiple-choice benchmarks, we show that downstream performance is computed from negative log likelihoods via a sequence of transformations that progressively degrade the statistical relationship between performance and scale. We then reveal the mechanism causing this degradation: downstream metrics require comparing the correct choice against a small number of specific incorrect choices, meaning accurately predicting downstream capabilities requires predicting not just how probability mass concentrates on the correct choice with scale, but also how probability mass fluctuates on specific incorrect choices with scale. We empirically study how probability mass on the correct choice co-varies with probability mass on incorrect choices with increasing compute, suggesting that scaling laws for incorrect choices might be achievable. Our work also explains why pretraining scaling laws are commonly regarded as more predictable than downstream capabilities and contributes towards establishing scaling-predictable evaluations of frontier AI models.
Zyda: A 1.3T Dataset for Open Language Modeling
Jun 04, 2024The size of large language models (LLMs) has scaled dramatically in recent years and their computational and data requirements have surged correspondingly. State-of-the-art language models, even at relatively smaller sizes, typically require training on at least a trillion tokens. This rapid advancement has eclipsed the growth of open-source datasets available for large-scale LLM pretraining. In this paper, we introduce Zyda (Zyphra Dataset), a dataset under a permissive license comprising 1.3 trillion tokens, assembled by integrating several major respected open-source datasets into a single, high-quality corpus. We apply rigorous filtering and deduplication processes, both within and across datasets, to maintain and enhance the quality derived from the original datasets. Our evaluations show that Zyda not only competes favorably with other open datasets like Dolma, FineWeb, and RefinedWeb, but also substantially improves the performance of comparable models from the Pythia suite. Our rigorous data processing methods significantly enhance Zyda's effectiveness, outperforming even the best of its constituent datasets when used independently.
Zamba: A Compact 7B SSM Hybrid Model
May 26, 2024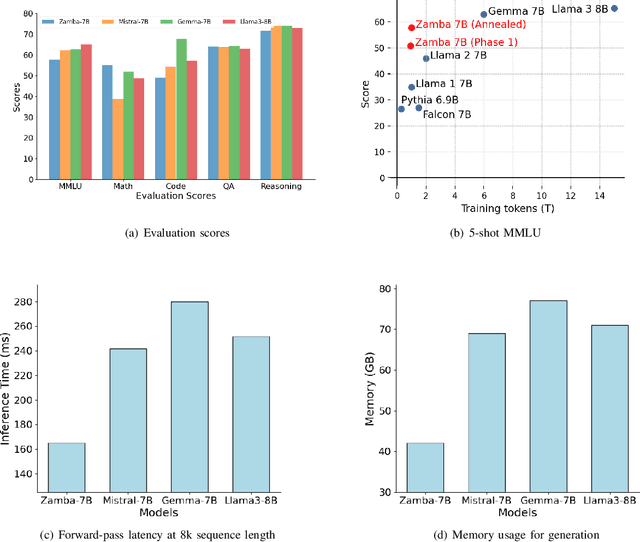
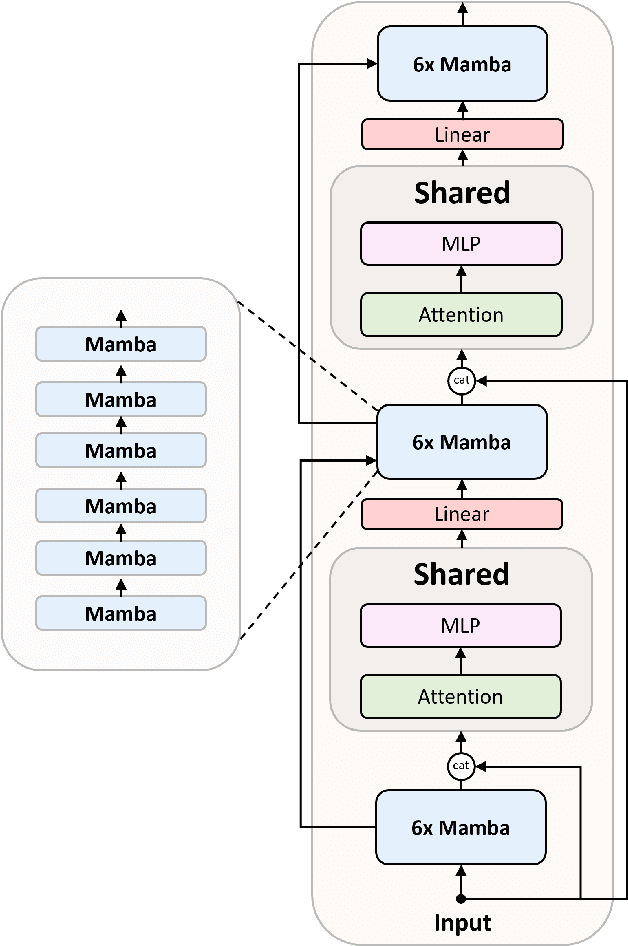

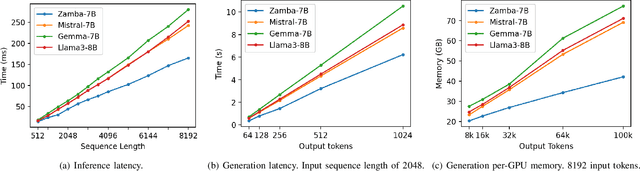
In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model which achieves competitive performance against leading open-weight models at a comparable scale. Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost. Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for generation of long sequences. Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and annealing phases.
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Mar 26, 2024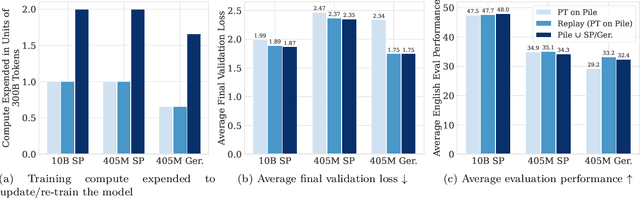
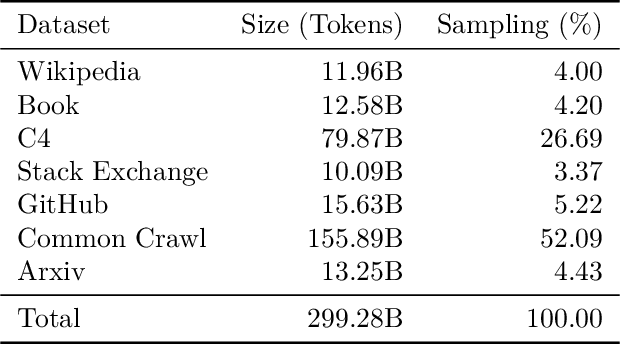
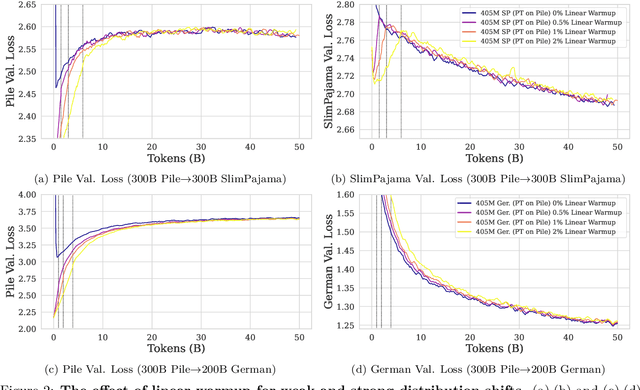
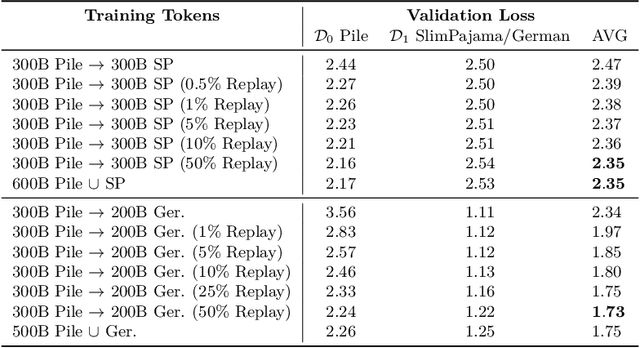
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023
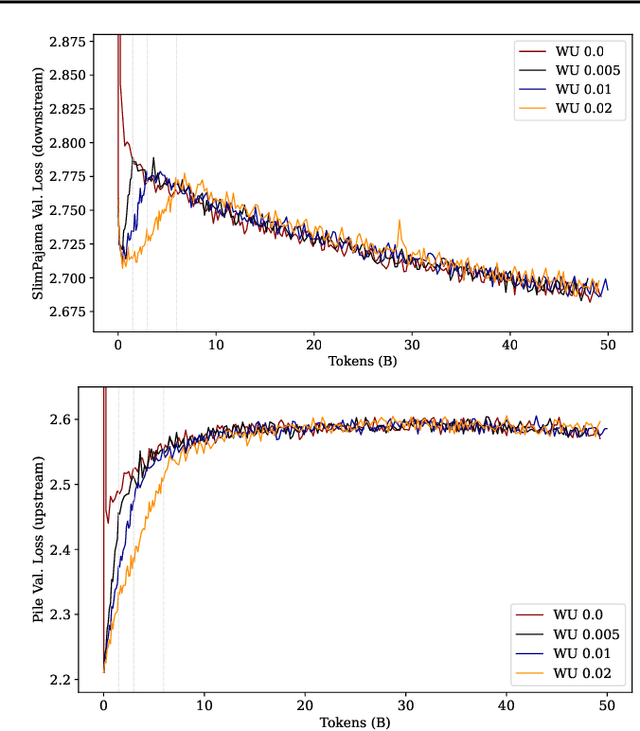
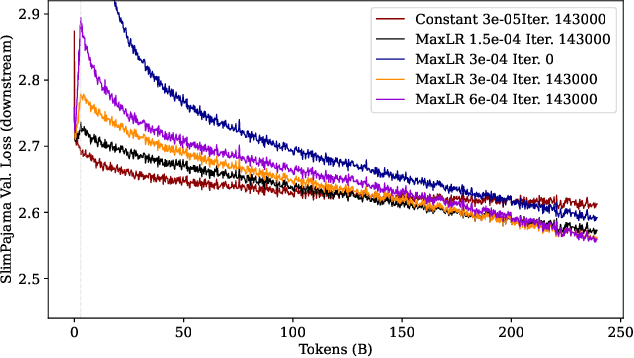
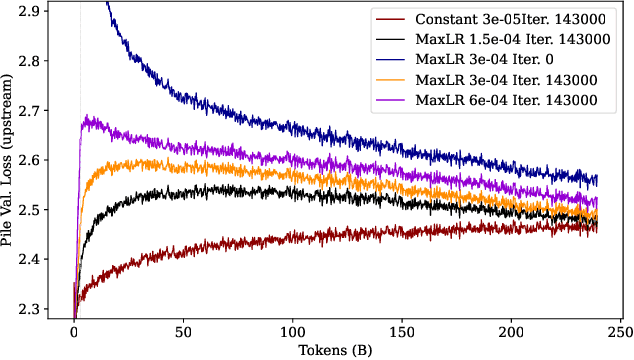
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
Towards Out-of-Distribution Adversarial Robustness
Oct 10, 2022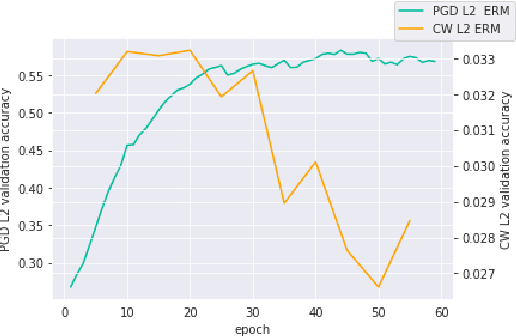
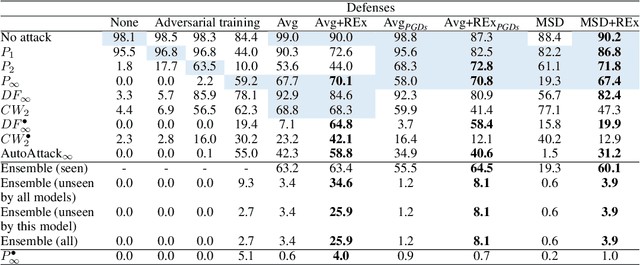
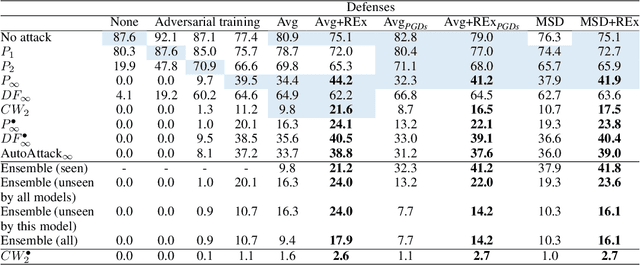
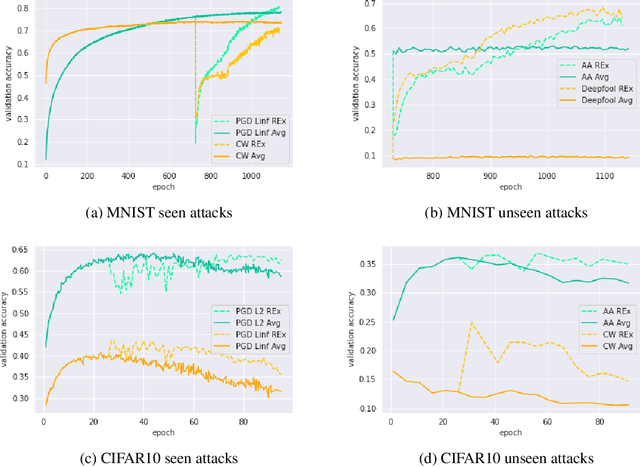
Adversarial robustness continues to be a major challenge for deep learning. A core issue is that robustness to one type of attack often fails to transfer to other attacks. While prior work establishes a theoretical trade-off in robustness against different $L_p$ norms, we show that there is potential for improvement against many commonly used attacks by adopting a domain generalisation approach. Concretely, we treat each type of attack as a domain, and apply the Risk Extrapolation method (REx), which promotes similar levels of robustness against all training attacks. Compared to existing methods, we obtain similar or superior worst-case adversarial robustness on attacks seen during training. Moreover, we achieve superior performance on families or tunings of attacks only encountered at test time. On ensembles of attacks, our approach improves the accuracy from 3.4% the best existing baseline to 25.9% on MNIST, and from 16.9% to 23.5% on CIFAR10.
Learning Robust Kernel Ensembles with Kernel Average Pooling
Sep 30, 2022
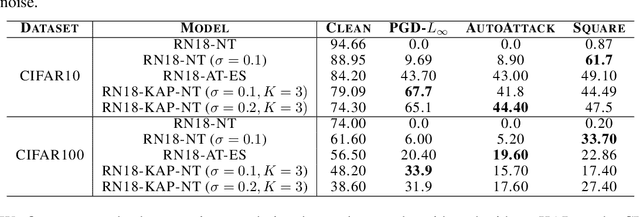
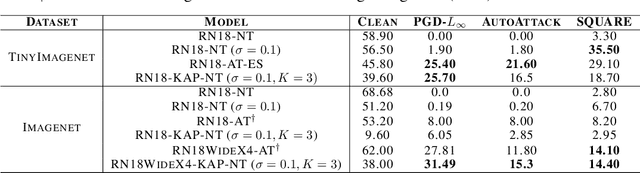
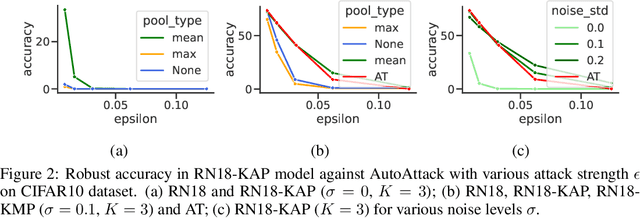
Model ensembles have long been used in machine learning to reduce the variance in individual model predictions, making them more robust to input perturbations. Pseudo-ensemble methods like dropout have also been commonly used in deep learning models to improve generalization. However, the application of these techniques to improve neural networks' robustness against input perturbations remains underexplored. We introduce Kernel Average Pool (KAP), a new neural network building block that applies the mean filter along the kernel dimension of the layer activation tensor. We show that ensembles of kernels with similar functionality naturally emerge in convolutional neural networks equipped with KAP and trained with backpropagation. Moreover, we show that when combined with activation noise, KAP models are remarkably robust against various forms of adversarial attacks. Empirical evaluations on CIFAR10, CIFAR100, TinyImagenet, and Imagenet datasets show substantial improvements in robustness against strong adversarial attacks such as AutoAttack that are on par with adversarially trained networks but are importantly obtained without training on any adversarial examples.
Lower Bounds and Conditioning of Differentiable Games
Jun 17, 2019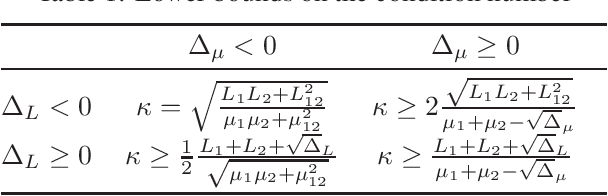



Many recent machine learning tools rely on differentiable game formulations. While several numerical methods have been proposed for these types of games, most of the work has been on convergence proofs or on upper bounds for the rate of convergence of those methods. In this work, we approach the question of fundamental iteration complexity by providing lower bounds. We generalise Nesterov's argument -- used in single-objective optimisation to derive a lower bound for a class of first-order black box optimisation algorithms -- to games. Moreover, we extend to games the p-SCLI framework used to derive spectral lower bounds for a large class of derivative-based single-objective optimisers. Finally, we propose a definition of the condition number arising from our lower bound analysis that matches the conditioning observed in upper bounds. Our condition number is more expressive than previously used definitions, as it covers a wide range of games, including bilinear games that lack strong convex-concavity.