 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Zamba2 Suite: Technical Report
Nov 22, 2024In this technical report, we present the Zamba2 series -- a suite of 1.2B, 2.7B, and 7.4B parameter hybrid Mamba2-transformer models that achieve state of the art performance against the leading open-weights models of their class, while achieving substantial gains in inference latency, throughput, and memory efficiency. The Zamba2 series builds upon our initial work with Zamba1-7B, optimizing its architecture, training and annealing datasets, and training for up to three trillion tokens. We provide open-source weights for all models of the Zamba2 series as well as instruction-tuned variants that are strongly competitive against comparable instruct-tuned models of their class. We additionally open-source the pretraining dataset, which we call Zyda-2, used to train the Zamba2 series of models. The models and datasets used in this work are openly available at https://huggingface.co/Zyphra
Tree Attention: Topology-aware Decoding for Long-Context Attention on GPU clusters
Aug 09, 2024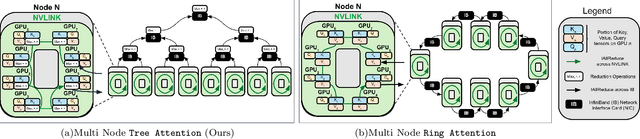
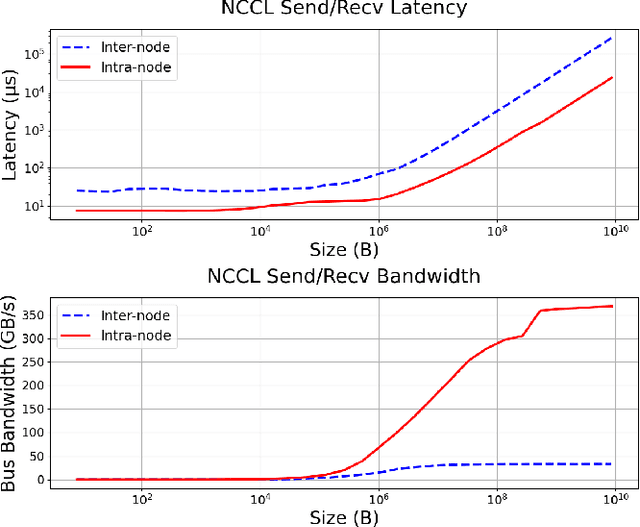
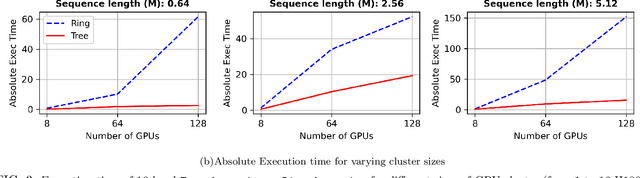
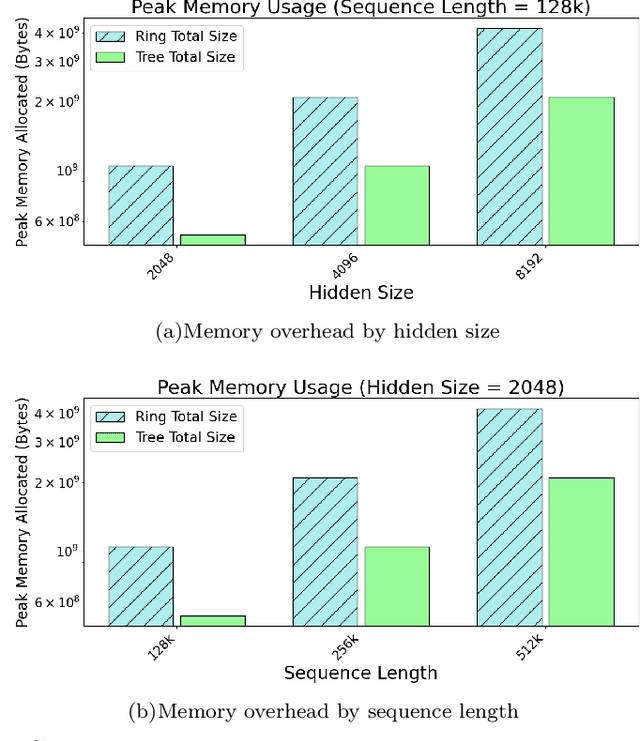
Self-attention is the core mathematical operation of modern transformer architectures and is also a significant computational bottleneck due to its quadratic complexity in the sequence length. In this work, we derive the scalar energy function whose gradient computes the self-attention block, thus elucidating the theoretical underpinnings of self-attention, providing a Bayesian interpretation of the operation and linking it closely with energy-based models such as Hopfield Networks. Our formulation reveals that the reduction across the sequence axis can be efficiently computed in parallel through a tree reduction. Our algorithm, for parallelizing attention computation across multiple GPUs enables cross-device decoding to be performed asymptotically faster (up to 8x faster in our experiments) than alternative approaches such as Ring Attention, while also requiring significantly less communication volume and incurring 2x less peak memory. Our code is publicly available here: \url{https://github.com/Zyphra/tree_attention}.
Zyda: A 1.3T Dataset for Open Language Modeling
Jun 04, 2024The size of large language models (LLMs) has scaled dramatically in recent years and their computational and data requirements have surged correspondingly. State-of-the-art language models, even at relatively smaller sizes, typically require training on at least a trillion tokens. This rapid advancement has eclipsed the growth of open-source datasets available for large-scale LLM pretraining. In this paper, we introduce Zyda (Zyphra Dataset), a dataset under a permissive license comprising 1.3 trillion tokens, assembled by integrating several major respected open-source datasets into a single, high-quality corpus. We apply rigorous filtering and deduplication processes, both within and across datasets, to maintain and enhance the quality derived from the original datasets. Our evaluations show that Zyda not only competes favorably with other open datasets like Dolma, FineWeb, and RefinedWeb, but also substantially improves the performance of comparable models from the Pythia suite. Our rigorous data processing methods significantly enhance Zyda's effectiveness, outperforming even the best of its constituent datasets when used independently.
Zamba: A Compact 7B SSM Hybrid Model
May 26, 2024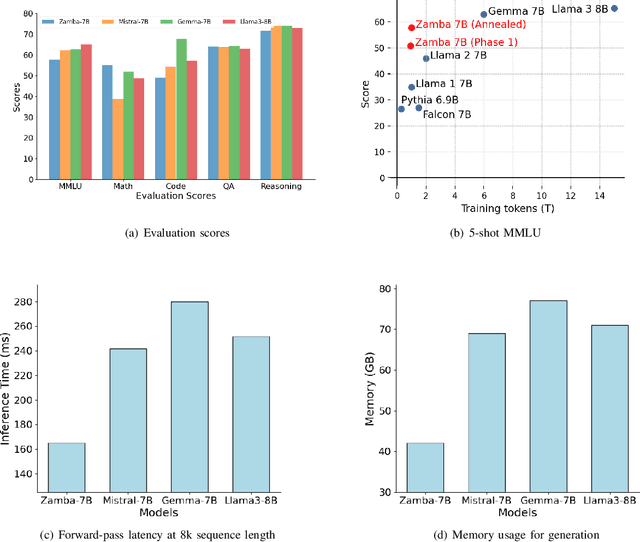
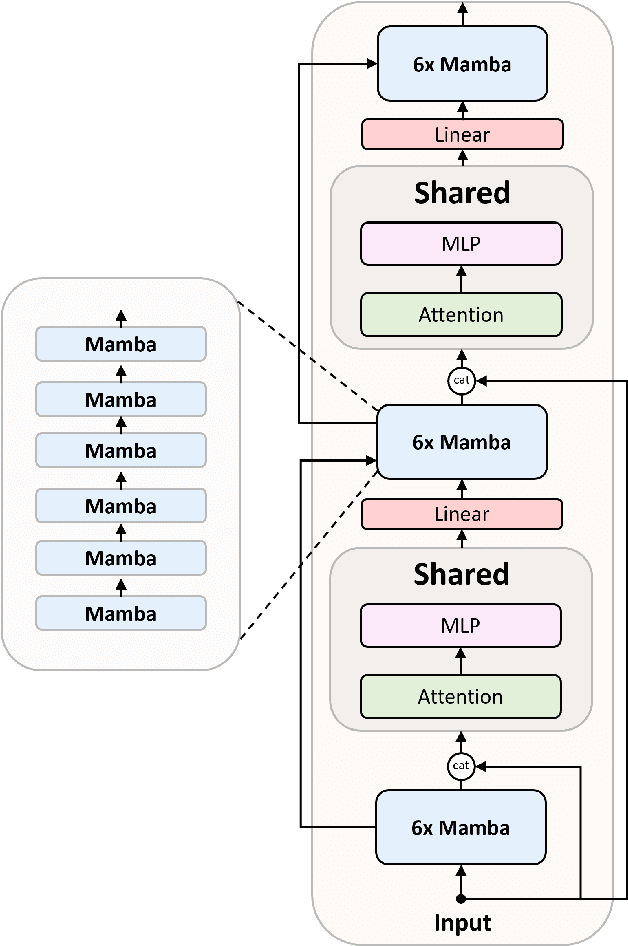

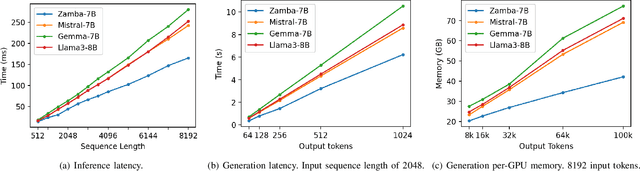
In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model which achieves competitive performance against leading open-weight models at a comparable scale. Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost. Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for generation of long sequences. Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and annealing phases.
Course Correcting Koopman Representations
Oct 23, 2023



Koopman representations aim to learn features of nonlinear dynamical systems (NLDS) which lead to linear dynamics in the latent space. Theoretically, such features can be used to simplify many problems in modeling and control of NLDS. In this work we study autoencoder formulations of this problem, and different ways they can be used to model dynamics, specifically for future state prediction over long horizons. We discover several limitations of predicting future states in the latent space and propose an inference-time mechanism, which we refer to as Periodic Reencoding, for faithfully capturing long term dynamics. We justify this method both analytically and empirically via experiments in low and high dimensional NLDS.
On Conditional and Compositional Language Model Differentiable Prompting
Jul 04, 2023Prompts have been shown to be an effective method to adapt a frozen Pretrained Language Model (PLM) to perform well on downstream tasks. Prompts can be represented by a human-engineered word sequence or by a learned continuous embedding. In this work, we investigate conditional and compositional differentiable prompting. We propose a new model, Prompt Production System (PRopS), which learns to transform task instructions or input metadata, into continuous prompts that elicit task-specific outputs from the PLM. Our model uses a modular network structure based on our neural formulation of Production Systems, which allows the model to learn discrete rules -- neural functions that learn to specialize in transforming particular prompt input patterns, making it suitable for compositional transfer learning and few-shot learning. We present extensive empirical and theoretical analysis and show that PRopS consistently surpasses other PLM adaptation techniques, and often improves upon fully fine-tuned models, on compositional generalization tasks, controllable summarization and multilingual translation, while needing fewer trainable parameters.
Block-State Transformer
Jun 15, 2023State space models (SSMs) have shown impressive results on tasks that require modeling long-range dependencies and efficiently scale to long sequences owing to their subquadratic runtime complexity. Originally designed for continuous signals, SSMs have shown superior performance on a plethora of tasks, in vision and audio; however, SSMs still lag Transformer performance in Language Modeling tasks. In this work, we propose a hybrid layer named Block-State Transformer (BST), that internally combines an SSM sublayer for long-range contextualization, and a Block Transformer sublayer for short-term representation of sequences. We study three different, and completely parallelizable, variants that integrate SSMs and block-wise attention. We show that our model outperforms similar Transformer-based architectures on language modeling perplexity and generalizes to longer sequences. In addition, the Block-State Transformer demonstrates more than tenfold increase in speed at the layer level compared to the Block-Recurrent Transformer when model parallelization is employed.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
Interactive-Chain-Prompting: Ambiguity Resolution for Crosslingual Conditional Generation with Interaction
Jan 24, 2023



Crosslingual conditional generation (e.g., machine translation) has long enjoyed the benefits of scaling. Nonetheless, there are still issues that scale alone may not overcome. A source query in one language, for instance, may yield several translation options in another language without any extra context. Only one translation could be acceptable however, depending on the translator's preferences and goals. Choosing the incorrect option might significantly affect translation usefulness and quality. We propose a novel method interactive-chain prompting -- a series of question, answering and generation intermediate steps between a Translator model and a User model -- that reduces translations into a list of subproblems addressing ambiguities and then resolving such subproblems before producing the final text to be translated. To check ambiguity resolution capabilities and evaluate translation quality, we create a dataset exhibiting different linguistic phenomena which leads to ambiguities at inference for four languages. To encourage further exploration in this direction, we release all datasets. We note that interactive-chain prompting, using eight interactions as exemplars, consistently surpasses prompt-based methods with direct access to background information to resolve ambiguities.
Using Graph Algorithms to Pretrain Graph Completion Transformers
Oct 14, 2022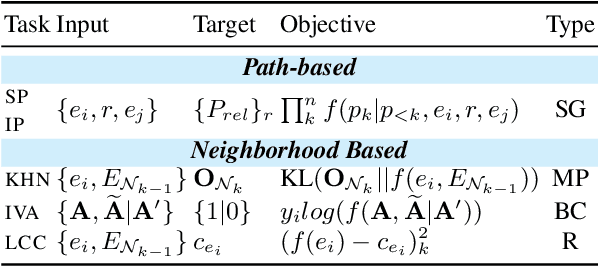
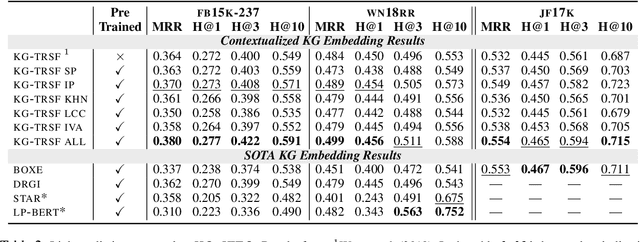


Recent work on Graph Neural Networks has demonstrated that self-supervised pretraining can further enhance performance on downstream graph, link, and node classification tasks. However, the efficacy of pretraining tasks has not been fully investigated for downstream large knowledge graph completion tasks. Using a contextualized knowledge graph embedding approach, we investigate five different pretraining signals, constructed using several graph algorithms and no external data, as well as their combination. We leverage the versatility of our Transformer-based model to explore graph structure generation pretraining tasks, typically inapplicable to most graph embedding methods. We further propose a new path-finding algorithm guided by information gain and find that it is the best-performing pretraining task across three downstream knowledge graph completion datasets. In a multitask setting that combines all pretraining tasks, our method surpasses some of the latest and strong performing knowledge graph embedding methods on all metrics for FB15K-237, on MRR and Hit@1 for WN18RR and on MRR and hit@10 for JF17K (a knowledge hypergraph dataset).