 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning Enables Scalable Multitask Deep Reinforcement Learning
Jun 04, 2026Scaling reinforcement learning (RL) to diverse multitask settings remains a central challenge. While recent advances in model-based RL achieve strong performance, they rely on planning and complex training pipelines, making it unclear which components are essential for scalability. We revisit this question and argue that the primary driver of scalable multitask RL is not model-based control, but \emph{representation learning}. In particular, we show that combining predictive, model-based representations with high-capacity value function approximation is sufficient to achieve strong performance, even without planning. We evaluate a simple model-free algorithm, MR.Q, coupled with auxiliary predictive objectives into a scalable actor-critic architecture. This approach outperforms a recent world-model-based method and a range of deep RL baselines across a diverse suite of multitask continuous control tasks, while significantly reducing computational overhead and improving wall-clock efficiency. We observe consistent improvements with increased model capacity and show through ablations that predictive representation learning is critical for performance.
Layerwise LQR for Geometry-Aware Optimization of Deep Networks
May 05, 2026Geometry-aware optimizers such as Newton and natural gradient can improve conditioning in deep learning, but scalable variants such as K-FAC, Shampoo, and related preconditioners usually impose structural approximations early, often discarding cross-layer interactions induced by the network computation. We introduce Layerwise LQR (LLQR), a framework for learning structured inverse preconditioners under a global layerwise optimal-control objective. The starting point is an exact equivalence: the steepest-descent step under a broad class of divergence-induced quadratic models--including Newton, Gauss-Newton, Fisher/natural-gradient, and intermediate-layer metrics--can be written as a finite-horizon Linear Quadratic Regulator (LQR) problem. This formulation serves as a reference that exposes the layerwise dynamics and cost matrices encoding the original dense geometry. We then derive a scalable relaxation that learns diagonal, (E-)Kronecker-factored, or other structured inverse preconditioners by minimizing the LQR objective and reusing them across iterations. The resulting optimizer wraps standard methods while retaining a principled connection to second-order geometry, without forming or inverting the global curvature matrix. Experiments on ResNets and Transformers show that LLQR improves optimization dynamics and often translates these gains into improved final test performance, while adding only modest wall-clock overhead. It establishes LLQR as a practical framework for geometry-aware second-order methods and a reference for evaluating scalable approximations.
Towards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models
Mar 21, 2026Vision-Language-Action (VLA) models show strong generalization for robotic control, but finetuning them with reinforcement learning (RL) is constrained by the high cost and safety risks of real-world interaction. Training VLA models in interactive world models avoids these issues but introduces several challenges, including pixel-level world modeling, multi-view consistency, and compounding errors under sparse rewards. Building on recent advances across large multimodal models and model-based RL, we propose VLA-MBPO, a practical framework to tackle these problems in VLA finetuning. Our approach has three key design choices: (i) adapting unified multimodal models (UMMs) for data-efficient world modeling; (ii) an interleaved view decoding mechanism to enforce multi-view consistency; and (iii) chunk-level branched rollout to mitigate error compounding. Theoretical analysis and experiments across simulation and real-world tasks demonstrate that VLA-MBPO significantly improves policy performance and sample efficiency, underscoring its robustness and scalability for real-world robotic deployment.
What Makes Value Learning Efficient in Residual Reinforcement Learning?
Feb 11, 2026Residual reinforcement learning (RL) enables stable online refinement of expressive pretrained policies by freezing the base and learning only bounded corrections. However, value learning in residual RL poses unique challenges that remain poorly understood. In this work, we identify two key bottlenecks: cold start pathology, where the critic lacks knowledge of the value landscape around the base policy, and structural scale mismatch, where the residual contribution is dwarfed by the base action. Through systematic investigation, we uncover the mechanisms underlying these bottlenecks, revealing that simple yet principled solutions suffice: base-policy transitions serve as an essential value anchor for implicit warmup, and critic normalization effectively restores representation sensitivity for discerning value differences. Based on these insights, we propose DAWN (Data-Anchored Warmup and Normalization), a minimal approach targeting efficient value learning in residual RL. By addressing these bottlenecks, DAWN demonstrates substantial efficiency gains across diverse benchmarks, policy architectures, and observation modalities.
Reward Redistribution for CVaR MDPs using a Bellman Operator on L-infinity
Feb 03, 2026Tail-end risk measures such as static conditional value-at-risk (CVaR) are used in safety-critical applications to prevent rare, yet catastrophic events. Unlike risk-neutral objectives, the static CVaR of the return depends on entire trajectories without admitting a recursive Bellman decomposition in the underlying Markov decision process. A classical resolution relies on state augmentation with a continuous variable. However, unless restricted to a specialized class of admissible value functions, this formulation induces sparse rewards and degenerate fixed points. In this work, we propose a novel formulation of the static CVaR objective based on augmentation. Our alternative approach leads to a Bellman operator with: (1) dense per-step rewards; (2) contracting properties on the full space of bounded value functions. Building on this theoretical foundation, we develop risk-averse value iteration and model-free Q-learning algorithms that rely on discretized augmented states. We further provide convergence guarantees and approximation error bounds due to discretization. Empirical results demonstrate that our algorithms successfully learn CVaR-sensitive policies and achieve effective performance-safety trade-offs.
The Three Regimes of Offline-to-Online Reinforcement Learning
Oct 01, 2025



Offline-to-online reinforcement learning (RL) has emerged as a practical paradigm that leverages offline datasets for pretraining and online interactions for fine-tuning. However, its empirical behavior is highly inconsistent: design choices of online-fine tuning that work well in one setting can fail completely in another. We propose a stability--plasticity principle that can explain this inconsistency: we should preserve the knowledge of pretrained policy or offline dataset during online fine-tuning, whichever is better, while maintaining sufficient plasticity. This perspective identifies three regimes of online fine-tuning, each requiring distinct stability properties. We validate this framework through a large-scale empirical study, finding that the results strongly align with its predictions in 45 of 63 cases. This work provides a principled framework for guiding design choices in offline-to-online RL based on the relative performance of the offline dataset and the pretrained policy.
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning
Jun 18, 2025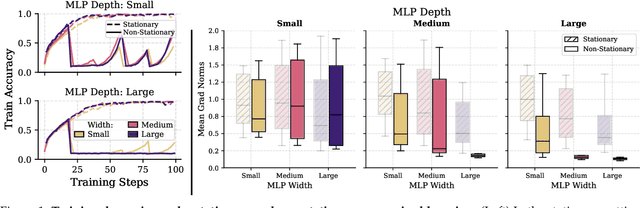
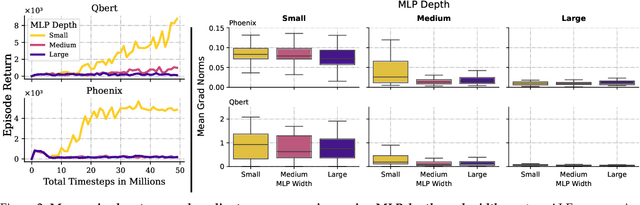
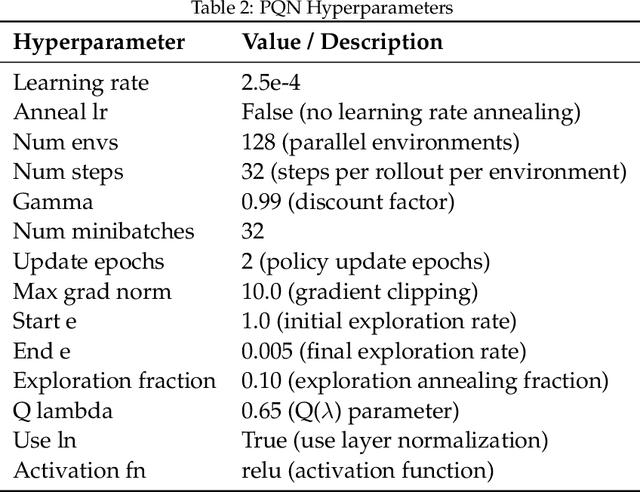
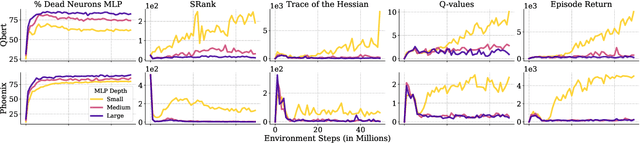
Scaling deep reinforcement learning networks is challenging and often results in degraded performance, yet the root causes of this failure mode remain poorly understood. Several recent works have proposed mechanisms to address this, but they are often complex and fail to highlight the causes underlying this difficulty. In this work, we conduct a series of empirical analyses which suggest that the combination of non-stationarity with gradient pathologies, due to suboptimal architectural choices, underlie the challenges of scale. We propose a series of direct interventions that stabilize gradient flow, enabling robust performance across a range of network depths and widths. Our interventions are simple to implement and compatible with well-established algorithms, and result in an effective mechanism that enables strong performance even at large scales. We validate our findings on a variety of agents and suites of environments.
State Entropy Regularization for Robust Reinforcement Learning
Jun 08, 2025



State entropy regularization has empirically shown better exploration and sample complexity in reinforcement learning (RL). However, its theoretical guarantees have not been studied. In this paper, we show that state entropy regularization improves robustness to structured and spatially correlated perturbations. These types of variation are common in transfer learning but often overlooked by standard robust RL methods, which typically focus on small, uncorrelated changes. We provide a comprehensive characterization of these robustness properties, including formal guarantees under reward and transition uncertainty, as well as settings where the method performs poorly. Much of our analysis contrasts state entropy with the widely used policy entropy regularization, highlighting their different benefits. Finally, from a practical standpoint, we illustrate that compared with policy entropy, the robustness advantages of state entropy are more sensitive to the number of rollouts used for policy evaluation.
Mol-MoE: Training Preference-Guided Routers for Molecule Generation
Feb 08, 2025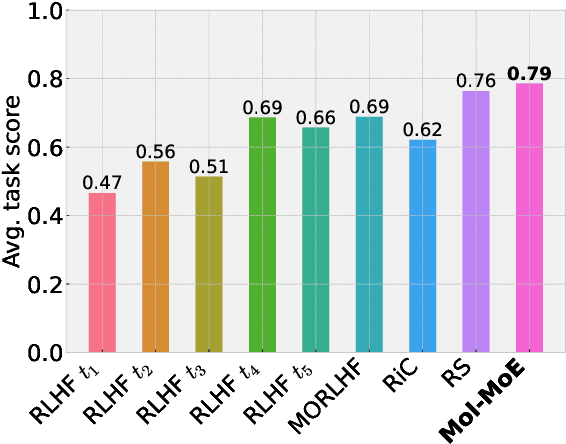
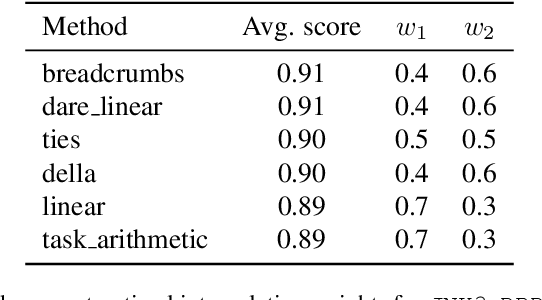
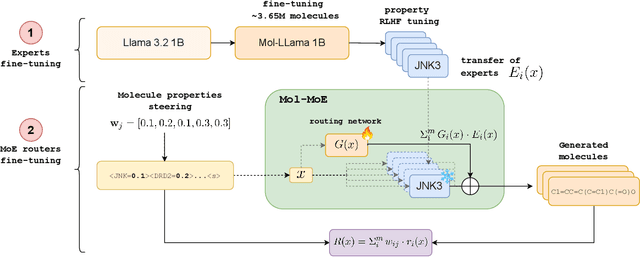

Recent advances in language models have enabled framing molecule generation as sequence modeling. However, existing approaches often rely on single-objective reinforcement learning, limiting their applicability to real-world drug design, where multiple competing properties must be optimized. Traditional multi-objective reinforcement learning (MORL) methods require costly retraining for each new objective combination, making rapid exploration of trade-offs impractical. To overcome these limitations, we introduce Mol-MoE, a mixture-of-experts (MoE) architecture that enables efficient test-time steering of molecule generation without retraining. Central to our approach is a preference-based router training objective that incentivizes the router to combine experts in a way that aligns with user-specified trade-offs. This provides improved flexibility in exploring the chemical property space at test time, facilitating rapid trade-off exploration. Benchmarking against state-of-the-art methods, we show that Mol-MoE achieves superior sample quality and steerability.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
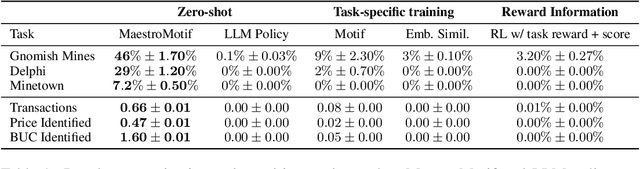

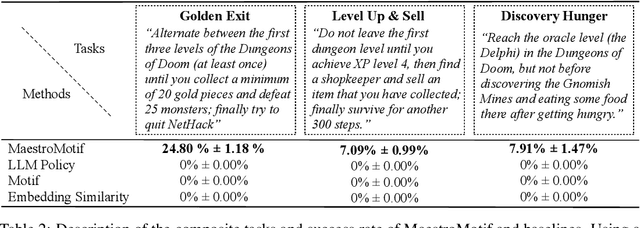
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.