 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Solver Bottleneck: Training Task Generators at the Learnable Frontier
Jun 10, 2026The limiting resource for training agents via reinforcement learning (RL) is increasingly frontier task supply: valid, solvable tasks just difficult enough to train the current model. As reasoning and agentic models improve, fixed task distributions saturate, while naive synthetic generation yields tasks that are trivial, impossible, or ill-posed. Training a task generator with RL to optimize validity and learnability can address this bottleneck, but direct optimization requires repeated solver rollouts per candidate. For software-engineering (SWE) tasks, a single rollout can take tens of minutes; solver-in-the-loop generator training is intractable. We introduce PROPEL, a solver-amortized framework for training task generators at the targeted solve rate. PROPEL trains a lightweight activation probe on a one-time labeled corpus of generated tasks and solver outcomes. The probe predicts target-solver pass rate from a frozen generator reference model and serves as a proxy for solve rate during generator optimization, reducing generator evaluation to a single forward pass. Across math, code, and software-engineering at multiple model scales, PROPEL shifts generation toward the targeted solve rate: for coding, tasks generated at the learnable frontier increase from $10.1\% \rightarrow 20.0\%$ for a Qwen2.5-3B-Instruct solver and from $5.3\% \rightarrow 12.6\%$ for a Qwen2.5-7B-Instruct solver. For SWE, PROPEL increases the share of generations at the targeted solve rate from $9.8\% \rightarrow 19.6\%$ for Qwen3.5-27B on repositories not seen during training of probe and generator.
unix-ctf: Procedural Environments for Unix-Competence Reinforcement Learning
May 27, 2026Unix competence is the ability to use shell and operating-system primitives as first-class tools, not merely to write programs through a terminal. Current terminal benchmarks tend to blur this distinction: a solver fluent in Python but weak in Unix can pass a substantial fraction of Terminal-Bench 2.0, while the reverse skill profile is rarely exercised. We make the distinction operational and build a training surface for the Unix component. unix-ctf is a procedural generator of capture-the-flag tasks for shell agents. Each task hides a short token (a flag of the form flag(a3b1c9...)) inside a fresh Linux container using a single Unix feature, and the agent must recover it. Tasks are produced by an LLM-assisted synthesis pipeline that generates candidate hiding techniques, rewrites them into parameterized hide-and-find script pairs, and filters them with a bidirectional contract: the hide script must leave no plaintext trace of the flag on disk, and the find script must recover the flag in a fresh directory. Because the LLM only writes the planting and recovery steps (the container, layout, and grading harness are fixed), the pipeline lands 656 of 750 raw attempts as portable, reusable variants (87.5\%). Our reproduction of Endless Terminals' full-container-generation approach lands only 17.4\% under the same checks. The 656 variants canonicalize to 155 distinct techniques. Fine-tuning Qwen3-8B with LoRA using GRPO on this surface lifts solve rate from 11.6\% to 43.6\% on a 15-skill multi-family holdout (n=225), redistributes which InterCode-CTF tasks the model solves, and produces a +33 pp gain in Forensics while reaching 32/100 on InterCode-CTF. These results suggest that Unix competence is separable, trainable, and best evaluated directly rather than folded into programming-through-a-shell.
Align and Filter: Improving Performance in Asynchronous On-Policy RL
Mar 02, 2026Distributed training and increasing the gradient update frequency are practical strategies to accelerate learning and improve performance, but both exacerbate a central challenge: \textit{policy lag}, which is the mismatch between the behavior policy generating data and the learning policy being updated. Policy lag can hinder the scaling of on-policy learning algorithms to larger problems. In this paper, we identify the sources of policy lag caused by distributed learning and high update frequency. We use the findings to propose \textit{total Variation-based Advantage aligned Constrained policy Optimization (\methodacronym)} as a practical approach to mitigate policy lag. We empirically validate our method and show that it offers better robustness to policy lag in classic RL tasks and a modern RL for LLM math reasoning task.
ARM-FM: Automated Reward Machines via Foundation Models for Compositional Reinforcement Learning
Oct 16, 2025Reinforcement learning (RL) algorithms are highly sensitive to reward function specification, which remains a central challenge limiting their broad applicability. We present ARM-FM: Automated Reward Machines via Foundation Models, a framework for automated, compositional reward design in RL that leverages the high-level reasoning capabilities of foundation models (FMs). Reward machines (RMs) -- an automata-based formalism for reward specification -- are used as the mechanism for RL objective specification, and are automatically constructed via the use of FMs. The structured formalism of RMs yields effective task decompositions, while the use of FMs enables objective specifications in natural language. Concretely, we (i) use FMs to automatically generate RMs from natural language specifications; (ii) associate language embeddings with each RM automata-state to enable generalization across tasks; and (iii) provide empirical evidence of ARM-FM's effectiveness in a diverse suite of challenging environments, including evidence of zero-shot generalization.
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning
Jun 18, 2025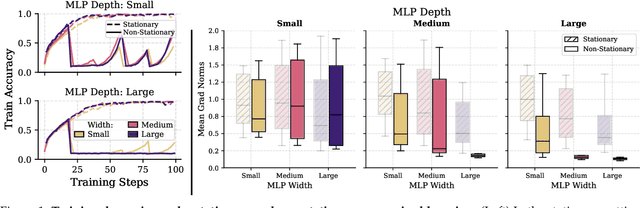
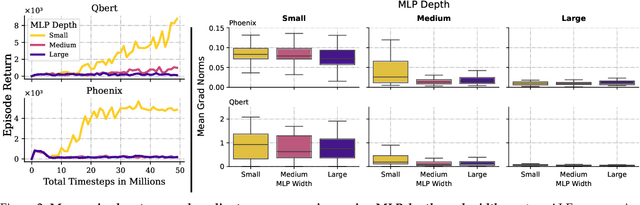
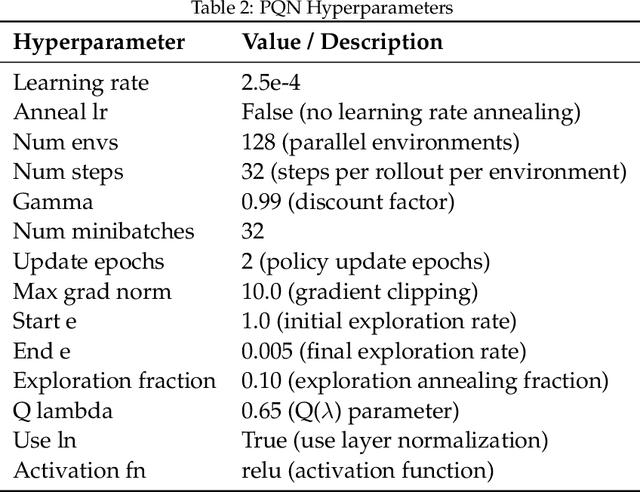
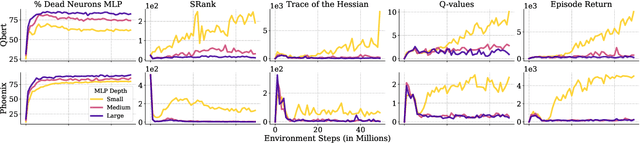
Scaling deep reinforcement learning networks is challenging and often results in degraded performance, yet the root causes of this failure mode remain poorly understood. Several recent works have proposed mechanisms to address this, but they are often complex and fail to highlight the causes underlying this difficulty. In this work, we conduct a series of empirical analyses which suggest that the combination of non-stationarity with gradient pathologies, due to suboptimal architectural choices, underlie the challenges of scale. We propose a series of direct interventions that stabilize gradient flow, enabling robust performance across a range of network depths and widths. Our interventions are simple to implement and compatible with well-established algorithms, and result in an effective mechanism that enables strong performance even at large scales. We validate our findings on a variety of agents and suites of environments.
RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning
May 29, 2024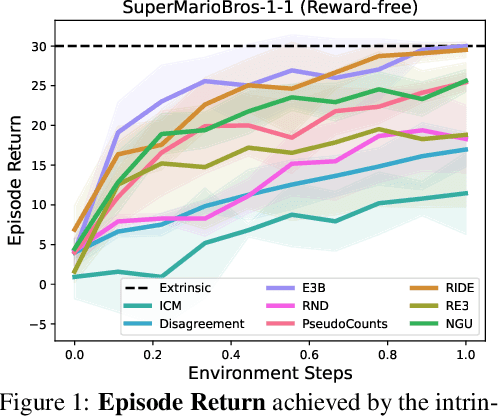

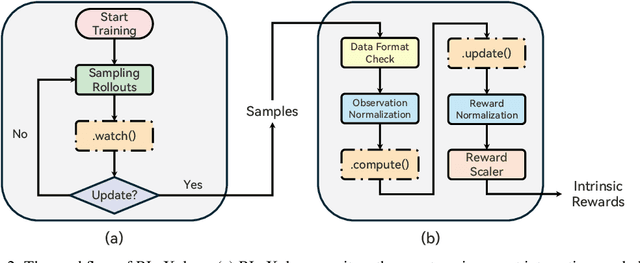
Extrinsic rewards can effectively guide reinforcement learning (RL) agents in specific tasks. However, extrinsic rewards frequently fall short in complex environments due to the significant human effort needed for their design and annotation. This limitation underscores the necessity for intrinsic rewards, which offer auxiliary and dense signals and can enable agents to learn in an unsupervised manner. Although various intrinsic reward formulations have been proposed, their implementation and optimization details are insufficiently explored and lack standardization, thereby hindering research progress. To address this gap, we introduce RLeXplore, a unified, highly modularized, and plug-and-play framework offering reliable implementations of eight state-of-the-art intrinsic reward algorithms. Furthermore, we conduct an in-depth study that identifies critical implementation details and establishes well-justified standard practices in intrinsically-motivated RL. The source code for RLeXplore is available at https://github.com/RLE-Foundation/RLeXplore.
Surprise-Adaptive Intrinsic Motivation for Unsupervised Reinforcement Learning
May 27, 2024



Both entropy-minimizing and entropy-maximizing (curiosity) objectives for unsupervised reinforcement learning (RL) have been shown to be effective in different environments, depending on the environment's level of natural entropy. However, neither method alone results in an agent that will consistently learn intelligent behavior across environments. In an effort to find a single entropy-based method that will encourage emergent behaviors in any environment, we propose an agent that can adapt its objective online, depending on the entropy conditions by framing the choice as a multi-armed bandit problem. We devise a novel intrinsic feedback signal for the bandit, which captures the agent's ability to control the entropy in its environment. We demonstrate that such agents can learn to control entropy and exhibit emergent behaviors in both high- and low-entropy regimes and can learn skillful behaviors in benchmark tasks. Videos of the trained agents and summarized findings can be found on our project page https://sites.google.com/view/surprise-adaptive-agents
Improving Intrinsic Exploration by Creating Stationary Objectives
Nov 03, 2023Exploration bonuses in reinforcement learning guide long-horizon exploration by defining custom intrinsic objectives. Count-based methods use the frequency of state visits to derive an exploration bonus. In this paper, we identify that any intrinsic reward function derived from count-based methods is non-stationary and hence induces a difficult objective to optimize for the agent. The key contribution of our work lies in transforming the original non-stationary rewards into stationary rewards through an augmented state representation. For this purpose, we introduce the Stationary Objectives For Exploration (SOFE) framework. SOFE requires identifying sufficient statistics for different exploration bonuses and finding an efficient encoding of these statistics to use as input to a deep network. SOFE is based on proposing state augmentations that expand the state space but hold the promise of simplifying the optimization of the agent's objective. Our experiments show that SOFE improves the agents' performance in challenging exploration problems, including sparse-reward tasks, pixel-based observations, 3D navigation, and procedurally generated environments.
Centralized control for multi-agent RL in a complex Real-Time-Strategy game
Apr 25, 2023



Multi-agent Reinforcement learning (MARL) studies the behaviour of multiple learning agents that coexist in a shared environment. MARL is more challenging than single-agent RL because it involves more complex learning dynamics: the observations and rewards of each agent are functions of all other agents. In the context of MARL, Real-Time Strategy (RTS) games represent very challenging environments where multiple players interact simultaneously and control many units of different natures all at once. In fact, RTS games are so challenging for the current RL methods, that just being able to tackle them with RL is interesting. This project provides the end-to-end experience of applying RL in the Lux AI v2 Kaggle competition, where competitors design agents to control variable-sized fleets of units and tackle a multi-variable optimization, resource gathering, and allocation problem in a 1v1 scenario against other competitors. We use a centralized approach for training the RL agents, and report multiple design decisions along the process. We provide the source code of the project: https://github.com/roger-creus/centralized-control-lux.
Which Design Decisions in AI-enabled Mobile Applications Contribute to Greener AI?
Sep 28, 2021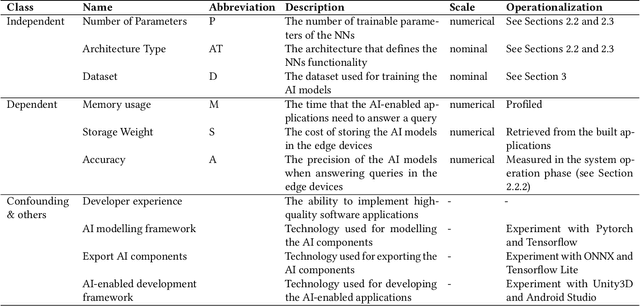
Background: The construction, evolution and usage of complex artificial intelligence (AI) models demand expensive computational resources. While currently available high-performance computing environments support well this complexity, the deployment of AI models in mobile devices, which is an increasing trend, is challenging. Mobile applications consist of environments with low computational resources and hence imply limitations in the design decisions during the AI-enabled software engineering lifecycle that balance the trade-off between the accuracy and the complexity of the mobile applications. Objective: Our objective is to systematically assess the trade-off between accuracy and complexity when deploying complex AI models (e.g. neural networks) to mobile devices, which have an implicit resource limitation. We aim to cover (i) the impact of the design decisions on the achievement of high-accuracy and low resource-consumption implementations; and (ii) the validation of profiling tools for systematically promoting greener AI. Method: This confirmatory registered report consists of a plan to conduct an empirical study to quantify the implications of the design decisions on AI-enabled applications performance and to report experiences of the end-to-end AI-enabled software engineering lifecycle. Concretely, we will implement both image-based and language-based neural networks in mobile applications to solve multiple image classification and text classification problems on different benchmark datasets. Overall, we plan to model the accuracy and complexity of AI-enabled applications in operation with respect to their design decisions and will provide tools for allowing practitioners to gain consciousness of the quantitative relationship between the design decisions and the green characteristics of study.