 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
Apr 13, 2026Pretrained video generation models provide strong priors for robot control, but existing unified world action models still struggle to decode reliable actions without substantial robot-specific training. We attribute this limitation to a structural mismatch: while video models capture how scenes evolve, action generation requires explicit reasoning about where to interact and the underlying manipulation intent. We introduce AIM, an intent-aware unified world action model that bridges this gap via an explicit spatial interface. Instead of decoding actions directly from future visual representations, AIM predicts an aligned spatial value map that encodes task-relevant interaction structure, enabling a control-oriented abstraction of future dynamics. Built on a pretrained video generation model, AIM jointly models future observations and value maps within a shared mixture-of-transformers architecture. It employs intent-causal attention to route future information to the action branch exclusively through the value representation. We further propose a self-distillation reinforcement learning stage that freezes the video and value branches and optimizes only the action head using dense rewards derived from projected value-map responses together with sparse task-level signals. To support training and evaluation, we construct a simulation dataset of 30K manipulation trajectories with synchronized multi-view observations, actions, and value-map annotations. Experiments on RoboTwin 2.0 benchmark show that AIM achieves a 94.0% average success rate, significantly outperforming prior unified world action baselines. Notably, the improvement is more pronounced in long-horizon and contact-sensitive manipulation tasks, demonstrating the effectiveness of explicit spatial-intent modeling as a bridge between visual world modeling and robot control.
AtomVLA: Scalable Post-Training for Robotic Manipulation via Predictive Latent World Models
Mar 09, 2026Vision-Language-Action (VLA) models demonstrate remarkable potential for generalizable robotic manipulation. The execution of complex multi-step behaviors in VLA models can be improved by robust instruction grounding, a critical component for effective control. However, current paradigms predominantly rely on coarse, high-level task instructions during supervised fine-tuning. This instruction grounding gap leaves models without explicit intermediate guidance, leading to severe compounding errors in long-horizon tasks. Therefore, bridging this instruction gap and providing scalable post-training for VLA models is urgent. To tackle this problem, we propose \method, the first subtask-aware VLA framework integrated with a scalable offline post-training pipeline. Our framework leverages a large language model to decompose high-level demonstrations into fine-grained atomic subtasks. This approach utilizes a pretrained predictive world model to score candidate action chunks against subtask goals in the latent space, mitigating error accumulation while significantly improving long-horizon robustness. Furthermore, this approach enables highly efficient Group Relative Policy Optimization without the prohibitive expenses associated with online rollouts on physical robots. Extensive simulations validate that our AtomVLA maintains strong robustness under perturbations. When evaluated against fundamental baseline models, it achieves an average success rate of 97.0\% on the LIBERO benchmark and 48.0\% on the LIBERO-PRO benchmark. Finally, experiments conducted in the real world using the Galaxea R1 Lite platform confirm its broad applicability across diverse tasks, especially long-horizon tasks. All datasets, checkpoints, and code will be released to the public domain following the acceptance of this work for future research.
Vision Transformers that Never Stop Learning
Mar 08, 2026Loss of plasticity refers to the progressive inability of a model to adapt to new tasks and poses a fundamental challenge for continual learning. While this phenomenon has been extensively studied in homogeneous neural architectures, such as multilayer perceptrons, its mechanisms in structurally heterogeneous, attention-based models such as Vision Transformers (ViTs) remain underexplored. In this work, we present a systematic investigation of loss of plasticity in ViTs, including a fine-grained diagnosis using local metrics that capture parameter diversity and utilization. Our analysis reveals that stacked attention modules exhibit increasing instability that exacerbates plasticity loss, while feed-forward network modules suffer even more pronounced degradation. Furthermore, we evaluate several approaches for mitigating plasticity loss. The results indicate that methods based on parameter re-initialization fail to recover plasticity in ViTs, whereas approaches that explicitly regulate the update process are more effective. Motivated by this insight, we propose ARROW, a geometry-aware optimizer that preserves plasticity by adaptively reshaping gradient directions using an online curvature estimate for the attention module. Extensive experiments show that ARROW effectively improves plasticity and maintains better performance on newly encountered tasks.
Continual Policy Distillation from Distributed Reinforcement Learning Teachers
Jan 30, 2026Continual Reinforcement Learning (CRL) aims to develop lifelong learning agents to continuously acquire knowledge across diverse tasks while mitigating catastrophic forgetting. This requires efficiently managing the stability-plasticity dilemma and leveraging prior experience to rapidly generalize to novel tasks. While various enhancement strategies for both aspects have been proposed, achieving scalable performance by directly applying RL to sequential task streams remains challenging. In this paper, we propose a novel teacher-student framework that decouples CRL into two independent processes: training single-task teacher models through distributed RL and continually distilling them into a central generalist model. This design is motivated by the observation that RL excels at solving single tasks, while policy distillation -- a relatively stable supervised learning process -- is well aligned with large foundation models and multi-task learning. Moreover, a mixture-of-experts (MoE) architecture and a replay-based approach are employed to enhance the plasticity and stability of the continual policy distillation process. Extensive experiments on the Meta-World benchmark demonstrate that our framework enables efficient continual RL, recovering over 85% of teacher performance while constraining task-wise forgetting to within 10%.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Dec 15, 2025Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Dec 08, 2025For full-size humanoid robots, even with recent advances in reinforcement learning-based control, achieving reliable locomotion on complex terrains, such as long staircases, remains challenging. In such settings, limited perception, ambiguous terrain cues, and insufficient adaptation of gait timing can cause even a single misplaced or mistimed step to result in rapid loss of balance. We introduce a perceptive locomotion framework that merges terrain sensing, gait regulation, and whole-body control into a single reinforcement learning policy. A downward-facing depth camera mounted under the base observes the support region around the feet, and a compact U-Net reconstructs a dense egocentric height map from each frame in real time, operating at the same frequency as the control loop. The perceptual height map, together with proprioceptive observations, is processed by a unified policy that produces joint commands and a global stepping-phase signal, allowing gait timing and whole-body posture to be adapted jointly to the commanded motion and local terrain geometry. We further adopt a single-stage successive teacher-student training scheme for efficient policy learning and knowledge transfer. Experiments conducted on a 31-DoF, 1.65 m humanoid robot demonstrate robust locomotion in both simulation and real-world settings, including forward and backward stair ascent and descent, as well as crossing a 46 cm gap. Project Page:https://ga-phl.github.io/
Plasticine: Accelerating Research in Plasticity-Motivated Deep Reinforcement Learning
Apr 24, 2025Developing lifelong learning agents is crucial for artificial general intelligence. However, deep reinforcement learning (RL) systems often suffer from plasticity loss, where neural networks gradually lose their ability to adapt during training. Despite its significance, this field lacks unified benchmarks and evaluation protocols. We introduce Plasticine, the first open-source framework for benchmarking plasticity optimization in deep RL. Plasticine provides single-file implementations of over 13 mitigation methods, 10 evaluation metrics, and learning scenarios with increasing non-stationarity levels from standard to open-ended environments. This framework enables researchers to systematically quantify plasticity loss, evaluate mitigation strategies, and analyze plasticity dynamics across different contexts. Our documentation, examples, and source code are available at https://github.com/RLE-Foundation/Plasticine.
ULTHO: Ultra-Lightweight yet Efficient Hyperparameter Optimization in Deep Reinforcement Learning
Mar 08, 2025Hyperparameter optimization (HPO) is a billion-dollar problem in machine learning, which significantly impacts the training efficiency and model performance. However, achieving efficient and robust HPO in deep reinforcement learning (RL) is consistently challenging due to its high non-stationarity and computational cost. To tackle this problem, existing approaches attempt to adapt common HPO techniques (e.g., population-based training or Bayesian optimization) to the RL scenario. However, they remain sample-inefficient and computationally expensive, which cannot facilitate a wide range of applications. In this paper, we propose ULTHO, an ultra-lightweight yet powerful framework for fast HPO in deep RL within single runs. Specifically, we formulate the HPO process as a multi-armed bandit with clustered arms (MABC) and link it directly to long-term return optimization. ULTHO also provides a quantified and statistical perspective to filter the HPs efficiently. We test ULTHO on benchmarks including ALE, Procgen, MiniGrid, and PyBullet. Extensive experiments demonstrate that the ULTHO can achieve superior performance with simple architecture, contributing to the development of advanced and automated RL systems.
Real-Time Dynamic Robot-Assisted Hand-Object Interaction via Motion Primitives
May 29, 2024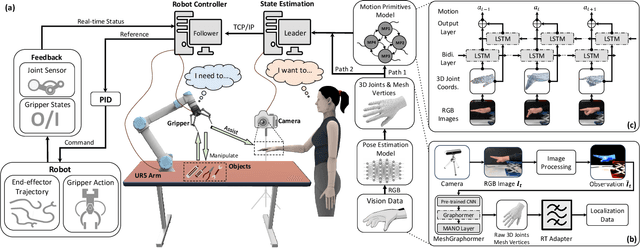
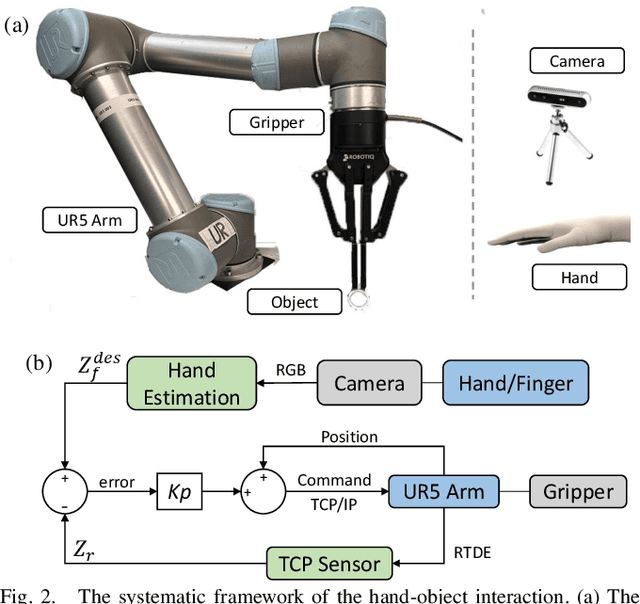
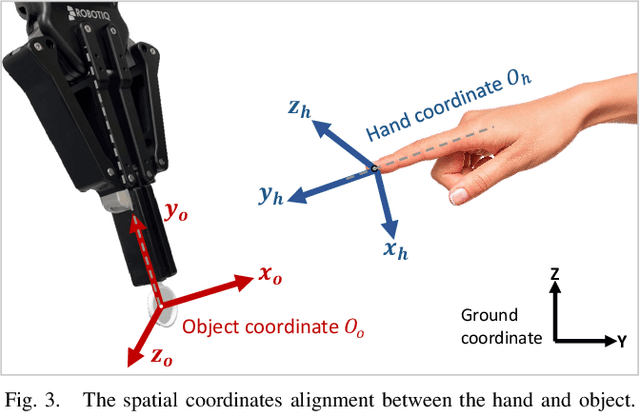
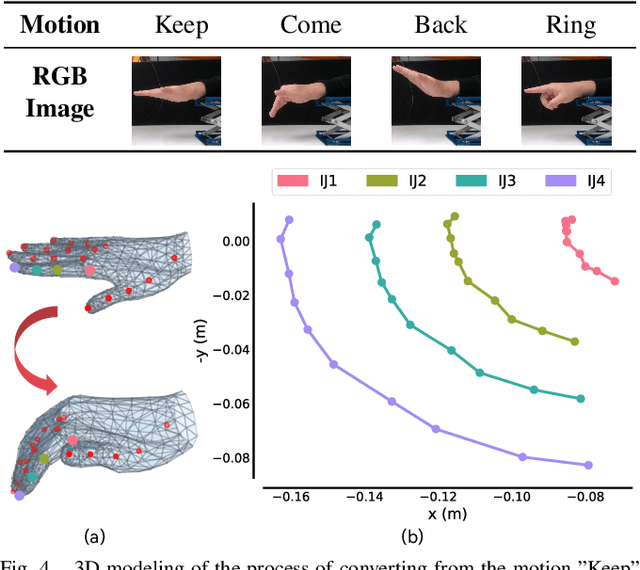
Advances in artificial intelligence (AI) have been propelling the evolution of human-robot interaction (HRI) technologies. However, significant challenges remain in achieving seamless interactions, particularly in tasks requiring physical contact with humans. These challenges arise from the need for accurate real-time perception of human actions, adaptive control algorithms for robots, and the effective coordination between human and robotic movements. In this paper, we propose an approach to enhancing physical HRI with a focus on dynamic robot-assisted hand-object interaction (HOI). Our methodology integrates hand pose estimation, adaptive robot control, and motion primitives to facilitate human-robot collaboration. Specifically, we employ a transformer-based algorithm to perform real-time 3D modeling of human hands from single RGB images, based on which a motion primitives model (MPM) is designed to translate human hand motions into robotic actions. The robot's action implementation is dynamically fine-tuned using the continuously updated 3D hand models. Experimental validations, including a ring-wearing task, demonstrate the system's effectiveness in adapting to real-time movements and assisting in precise task executions.
RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning
May 29, 2024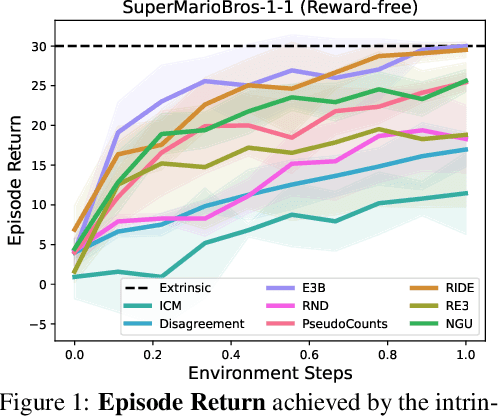

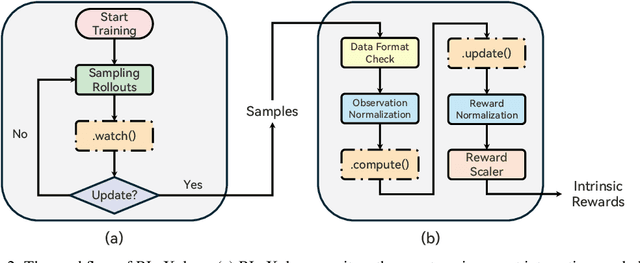
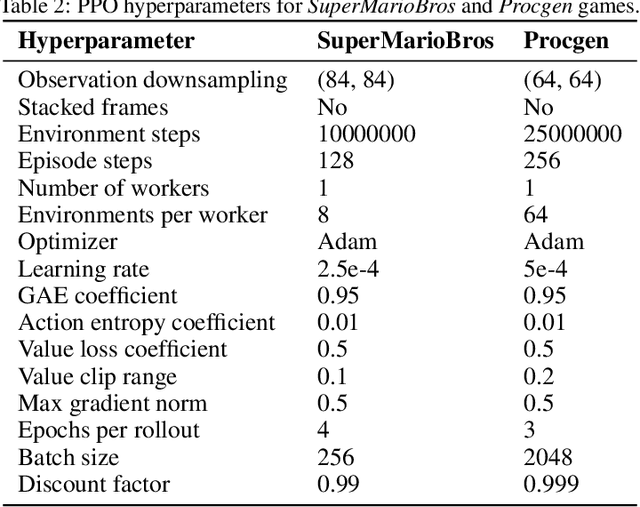
Extrinsic rewards can effectively guide reinforcement learning (RL) agents in specific tasks. However, extrinsic rewards frequently fall short in complex environments due to the significant human effort needed for their design and annotation. This limitation underscores the necessity for intrinsic rewards, which offer auxiliary and dense signals and can enable agents to learn in an unsupervised manner. Although various intrinsic reward formulations have been proposed, their implementation and optimization details are insufficiently explored and lack standardization, thereby hindering research progress. To address this gap, we introduce RLeXplore, a unified, highly modularized, and plug-and-play framework offering reliable implementations of eight state-of-the-art intrinsic reward algorithms. Furthermore, we conduct an in-depth study that identifies critical implementation details and establishes well-justified standard practices in intrinsically-motivated RL. The source code for RLeXplore is available at https://github.com/RLE-Foundation/RLeXplore.