 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding Episodic Visitation Discrepancy for Exploration in Reinforcement Learning
Paper and Code
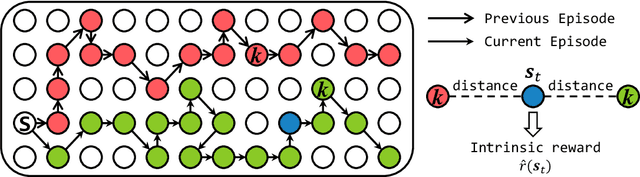
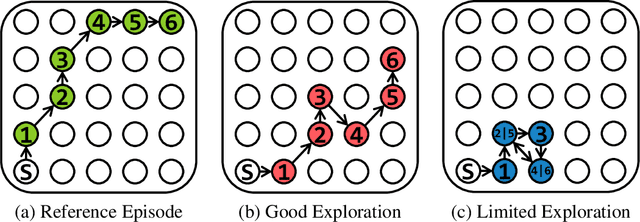
Exploration is critical for deep reinforcement learning in complex environments with high-dimensional observations and sparse rewards. To address this problem, recent approaches proposed to leverage intrinsic rewards to improve exploration, such as novelty-based exploration and prediction-based exploration. However, many intrinsic reward modules require sophisticated structures and representation learning, resulting in prohibitive computational complexity and unstable performance. In this paper, we propose Rewarding Episodic Visitation Discrepancy (REVD), a computation-efficient and quantified exploration method. More specifically, REVD provides intrinsic rewards by evaluating the R\'enyi divergence-based visitation discrepancy between episodes. To make efficient divergence estimation, a k-nearest neighbor estimator is utilized with a randomly-initialized state encoder. Finally, the REVD is tested on Atari games and PyBullet Robotics Environments. Extensive experiments demonstrate that REVD can significantly improves the sample efficiency of reinforcement learning algorithms and outperforms the benchmarking methods.