 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Global Similarity: Towards Fine-Grained, Multi-Condition Multimodal Retrieval
Mar 01, 2026Recent advances in multimodal large language models (MLLMs) have substantially expanded the capabilities of multimodal retrieval, enabling systems to align and retrieve information across visual and textual modalities. Yet, existing benchmarks largely focus on coarse-grained or single-condition alignment, overlooking real-world scenarios where user queries specify multiple interdependent constraints across modalities. To bridge this gap, we introduce MCMR (Multi-Conditional Multimodal Retrieval): a large-scale benchmark designed to evaluate fine-grained, multi-condition cross-modal retrieval under natural-language queries. MCMR spans five product domains: upper and bottom clothing, jewelry, shoes, and furniture. It also preserves rich long-form metadata essential for compositional matching. Each query integrates complementary visual and textual attributes, requiring models to jointly satisfy all specified conditions for relevance. We benchmark a diverse suite of MLLM-based multimodal retrievers and vision-language rerankers to assess their condition-aware reasoning abilities. Experimental results reveal: (i) distinct modality asymmetries across models; (ii) visual cues dominate early-rank precision, while textual metadata stabilizes long-tail ordering; and (iii) MLLM-based pointwise rerankers markedly improve fine-grained matching by explicitly verifying query-candidate consistency. Overall, MCMR establishes a challenging and diagnostic benchmark for advancing multimodal retrieval toward compositional, constraint-aware, and interpretable understanding. Our code and dataset is available at https://github.com/EIT-NLP/MCMR
Restoration Adaptation for Semantic Segmentation on Low Quality Images
Feb 15, 2026In real-world scenarios, the performance of semantic segmentation often deteriorates when processing low-quality (LQ) images, which may lack clear semantic structures and high-frequency details. Although image restoration techniques offer a promising direction for enhancing degraded visual content, conventional real-world image restoration (Real-IR) models primarily focus on pixel-level fidelity and often fail to recover task-relevant semantic cues, limiting their effectiveness when directly applied to downstream vision tasks. Conversely, existing segmentation models trained on high-quality data lack robustness under real-world degradations. In this paper, we propose Restoration Adaptation for Semantic Segmentation (RASS), which effectively integrates semantic image restoration into the segmentation process, enabling high-quality semantic segmentation on the LQ images directly. Specifically, we first propose a Semantic-Constrained Restoration (SCR) model, which injects segmentation priors into the restoration model by aligning its cross-attention maps with segmentation masks, encouraging semantically faithful image reconstruction. Then, RASS transfers semantic restoration knowledge into segmentation through LoRA-based module merging and task-specific fine-tuning, thereby enhancing the model's robustness to LQ images. To validate the effectiveness of our framework, we construct a real-world LQ image segmentation dataset with high-quality annotations, and conduct extensive experiments on both synthetic and real-world LQ benchmarks. The results show that SCR and RASS significantly outperform state-of-the-art methods in segmentation and restoration tasks. Code, models, and datasets will be available at https://github.com/Ka1Guan/RASS.git.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
Interpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits
Jan 23, 2026We introduce a black-box interpretability framework that learns a verifiable constitution: a natural language summary of how changes to a prompt affect a model's specific behavior, such as its alignment, correctness, or adherence to constraints. Our method leverages atomic concept edits (ACEs), which are targeted operations that add, remove, or replace an interpretable concept in the input prompt. By systematically applying ACEs and observing the resulting effects on model behavior across various tasks, our framework learns a causal mapping from edits to predictable outcomes. This learned constitution provides deep, generalizable insights into the model. Empirically, we validate our approach across diverse tasks, including mathematical reasoning and text-to-image alignment, for controlling and understanding model behavior. We found that for text-to-image generation, GPT-Image tends to focus on grammatical adherence, while Imagen 4 prioritizes atmospheric coherence. In mathematical reasoning, distractor variables confuse GPT-5 but leave Gemini 2.5 models and o4-mini largely unaffected. Moreover, our results show that the learned constitutions are highly effective for controlling model behavior, achieving an average of 1.86 times boost in success rate over methods that do not use constitutions.
S^2F-Net:A Robust Spatial-Spectral Fusion Framework for Cross-Model AIGC Detection
Jan 18, 2026The rapid development of generative models has imposed an urgent demand for detection schemes with strong generalization capabilities. However, existing detection methods generally suffer from overfitting to specific source models, leading to significant performance degradation when confronted with unseen generative architectures. To address these challenges, this paper proposes a cross-model detection framework called S 2 F-Net, whose core lies in exploring and leveraging the inherent spectral discrepancies between real and synthetic textures. Considering that upsampling operations leave unique and distinguishable frequency fingerprints in both texture-poor and texture-rich regions, we focus our research on the detection of frequency-domain artifacts, aiming to fundamentally improve the generalization performance of the model. Specifically, we introduce a learnable frequency attention module that adaptively weights and enhances discriminative frequency bands by synergizing spatial texture analysis and spectral dependencies.On the AIGCDetectBenchmark, which includes 17 categories of generative models, S 2 F-Net achieves a detection accuracy of 90.49%, significantly outperforming various existing baseline methods in cross-domain detection scenarios.
ReWorld: Multi-Dimensional Reward Modeling for Embodied World Models
Jan 18, 2026Recently, video-based world models that learn to simulate the dynamics have gained increasing attention in robot learning. However, current approaches primarily emphasize visual generative quality while overlooking physical fidelity, dynamic consistency, and task logic, especially for contact-rich manipulation tasks, which limits their applicability to downstream tasks. To this end, we introduce ReWorld, a framework aimed to employ reinforcement learning to align the video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality. Specifically, we first construct a large-scale (~235K) video preference dataset and employ it to train a hierarchical reward model designed to capture multi-dimensional reward consistent with human preferences. We further propose a practical alignment algorithm that post-trains flow-based world models using this reward through a computationally efficient PPO-style algorithm. Comprehensive experiments and theoretical analysis demonstrate that ReWorld significantly improves the physical fidelity, logical coherence, embodiment and visual quality of generated rollouts, outperforming previous methods.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Dec 15, 2025Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025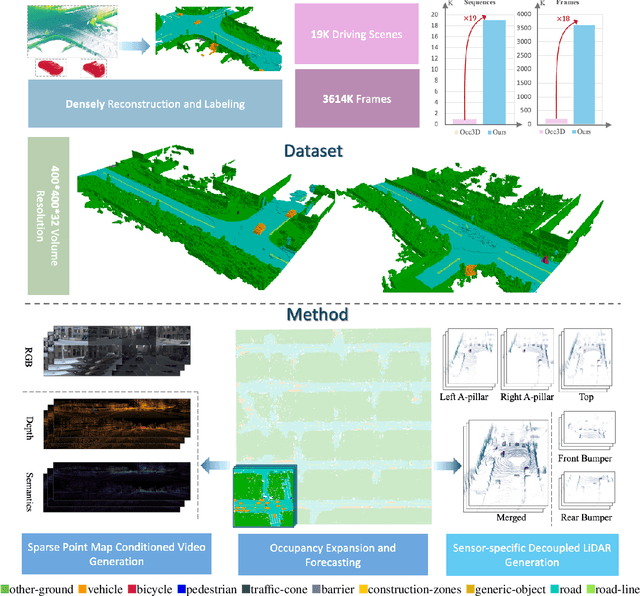
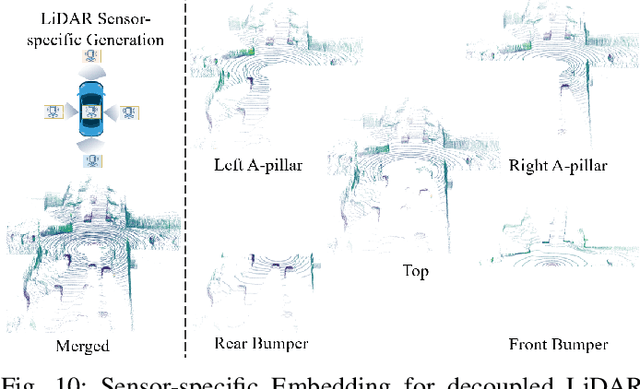

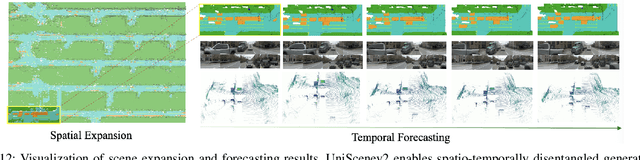
Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
Tools are under-documented: Simple Document Expansion Boosts Tool Retrieval
Oct 26, 2025Large Language Models (LLMs) have recently demonstrated strong capabilities in tool use, yet progress in tool retrieval remains hindered by incomplete and heterogeneous tool documentation. To address this challenge, we introduce Tool-DE, a new benchmark and framework that systematically enriches tool documentation with structured fields to enable more effective tool retrieval, together with two dedicated models, Tool-Embed and Tool-Rank. We design a scalable document expansion pipeline that leverages both open- and closed-source LLMs to generate, validate, and refine enriched tool profiles at low cost, producing large-scale corpora with 50k instances for embedding-based retrievers and 200k for rerankers. On top of this data, we develop two models specifically tailored for tool retrieval: Tool-Embed, a dense retriever, and Tool-Rank, an LLM-based reranker. Extensive experiments on ToolRet and Tool-DE demonstrate that document expansion substantially improves retrieval performance, with Tool-Embed and Tool-Rank achieving new state-of-the-art results on both benchmarks. We further analyze the contribution of individual fields to retrieval effectiveness, as well as the broader impact of document expansion on both training and evaluation. Overall, our findings highlight both the promise and limitations of LLM-driven document expansion, positioning Tool-DE, along with the proposed Tool-Embed and Tool-Rank, as a foundation for future research in tool retrieval.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.