 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShieldGemma 2: Robust and Tractable Image Content Moderation
Apr 01, 2025We introduce ShieldGemma 2, a 4B parameter image content moderation model built on Gemma 3. This model provides robust safety risk predictions across the following key harm categories: Sexually Explicit, Violence \& Gore, and Dangerous Content for synthetic images (e.g. output of any image generation model) and natural images (e.g. any image input to a Vision-Language Model). We evaluated on both internal and external benchmarks to demonstrate state-of-the-art performance compared to LlavaGuard \citep{helff2024llavaguard}, GPT-4o mini \citep{hurst2024gpt}, and the base Gemma 3 model \citep{gemma_2025} based on our policies. Additionally, we present a novel adversarial data generation pipeline which enables a controlled, diverse, and robust image generation. ShieldGemma 2 provides an open image moderation tool to advance multimodal safety and responsible AI development.
Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Nov 26, 2024Tokenization techniques such as Byte-Pair Encoding (BPE) and Byte-Level BPE (BBPE) have significantly improved the computational efficiency and vocabulary representation stability of large language models (LLMs) by segmenting text into tokens. However, this segmentation often obscures the internal character structures and sequences within tokens, preventing models from fully learning these intricate details during training. Consequently, LLMs struggle to comprehend the character compositions and positional relationships within tokens, especially when fine-tuned on downstream tasks with limited data. In this paper, we introduce Token Internal Position Awareness (TIPA), a novel approach that enhances LLMs' understanding of internal token structures by training them on reverse character prediction tasks using the tokenizer's own vocabulary. This method enables models to effectively learn and generalize character positions and internal structures. Experimental results demonstrate that LLMs trained with TIPA outperform baseline models in predicting character positions at the token level. Furthermore, when applied to the downstream task of Chinese Spelling Correction (CSC), TIPA not only accelerates model convergence but also significantly improves task performance.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024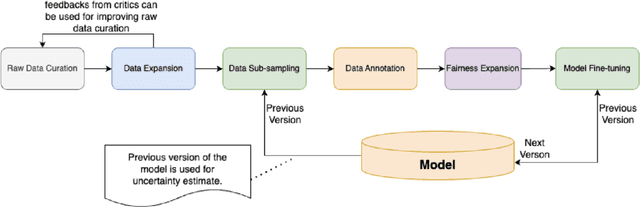
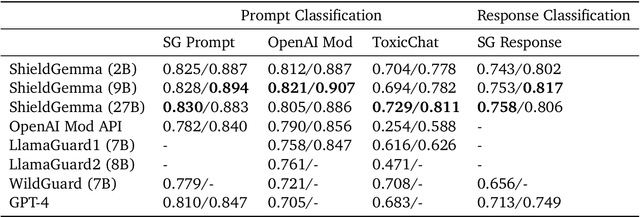

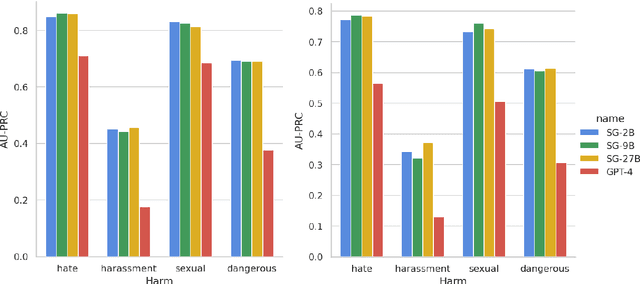
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.
Assessing Model Generalization in Vicinity
Jun 13, 2024



This paper evaluates the generalization ability of classification models on out-of-distribution test sets without depending on ground truth labels. Common approaches often calculate an unsupervised metric related to a specific model property, like confidence or invariance, which correlates with out-of-distribution accuracy. However, these metrics are typically computed for each test sample individually, leading to potential issues caused by spurious model responses, such as overly high or low confidence. To tackle this challenge, we propose incorporating responses from neighboring test samples into the correctness assessment of each individual sample. In essence, if a model consistently demonstrates high correctness scores for nearby samples, it increases the likelihood of correctly predicting the target sample, and vice versa. The resulting scores are then averaged across all test samples to provide a holistic indication of model accuracy. Developed under the vicinal risk formulation, this approach, named vicinal risk proxy (VRP), computes accuracy without relying on labels. We show that applying the VRP method to existing generalization indicators, such as average confidence and effective invariance, consistently improves over these baselines both methodologically and experimentally. This yields a stronger correlation with model accuracy, especially on challenging out-of-distribution test sets.
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
May 30, 2024



Large language models (LLMs) have shown great progress in responding to user questions, allowing for a multitude of diverse applications. Yet, the quality of LLM outputs heavily depends on the prompt design, where a good prompt might enable the LLM to answer a very challenging question correctly. Therefore, recent works have developed many strategies for improving the prompt, including both manual crafting and in-domain optimization. However, their efficacy in unrestricted scenarios remains questionable, as the former depends on human design for specific questions and the latter usually generalizes poorly to unseen scenarios. To address these problems, we give LLMs the freedom to design the best prompts according to themselves. Specifically, we include a hierarchy of LLMs, first constructing a prompt with precise instructions and accurate wording in a hierarchical manner, and then using this prompt to generate the final answer to the user query. We term this pipeline Hierarchical Multi-Agent Workflow, or HMAW. In contrast with prior works, HMAW imposes no human restriction and requires no training, and is completely task-agnostic while capable of adjusting to the nuances of the underlying task. Through both quantitative and qualitative experiments across multiple benchmarks, we verify that despite its simplicity, the proposed approach can create detailed and suitable prompts, further boosting the performance of current LLMs.
Optimizing Calibration by Gaining Aware of Prediction Correctness
Apr 19, 2024



Model calibration aims to align confidence with prediction correctness. The Cross-Entropy CE) loss is widely used for calibrator training, which enforces the model to increase confidence on the ground truth class. However, we find the CE loss has intrinsic limitations. For example, for a narrow misclassification, a calibrator trained by the CE loss often produces high confidence on the wrongly predicted class (e.g., a test sample is wrongly classified and its softmax score on the ground truth class is around 0.4), which is undesirable. In this paper, we propose a new post-hoc calibration objective derived from the aim of calibration. Intuitively, the proposed objective function asks that the calibrator decrease model confidence on wrongly predicted samples and increase confidence on correctly predicted samples. Because a sample itself has insufficient ability to indicate correctness, we use its transformed versions (e.g., rotated, greyscaled and color-jittered) during calibrator training. Trained on an in-distribution validation set and tested with isolated, individual test samples, our method achieves competitive calibration performance on both in-distribution and out-of-distribution test sets compared with the state of the art. Further, our analysis points out the difference between our method and commonly used objectives such as CE loss and mean square error loss, where the latters sometimes deviates from the calibration aim.
Harm Amplification in Text-to-Image Models
Feb 01, 2024



Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by first introducing a formal definition for this phenomenon, termed harm amplification. We further contribute to the field by developing methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Action Units That Constitute Trainable Micro-expressions (and A Large-scale Synthetic Dataset)
Dec 10, 2021



Due to the expensive data collection process, micro-expression datasets are generally much smaller in scale than those in other computer vision fields, rendering large-scale training less stable and feasible. In this paper, we aim to develop a protocol to automatically synthesize micro-expression training data that 1) are on a large scale and 2) allow us to train recognition models with strong accuracy on real-world test sets. Specifically, we discover three types of Action Units (AUs) that can well constitute trainable micro-expressions. These AUs come from real-world micro-expressions, early frames of macro-expressions, and the relationship between AUs and expression labels defined by human knowledge. With these AUs, our protocol then employs large numbers of face images with various identities and an existing face generation method for micro-expression synthesis. Micro-expression recognition models are trained on the generated micro-expression datasets and evaluated on real-world test sets, where very competitive and stable performance is obtained. The experimental results not only validate the effectiveness of these AUs and our dataset synthesis protocol but also reveal some critical properties of micro-expressions: they generalize across faces, are close to early-stage macro-expressions, and can be manually defined.
Synthetic Data Are as Good as the Real for Association Knowledge Learning in Multi-object Tracking
Jul 02, 2021
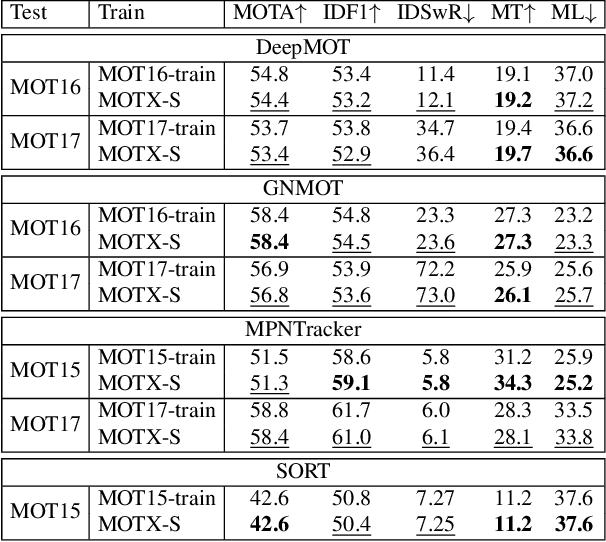


Association, aiming to link bounding boxes of the same identity in a video sequence, is a central component in multi-object tracking (MOT). To train association modules, e.g., parametric networks, real video data are usually used. However, annotating person tracks in consecutive video frames is expensive, and such real data, due to its inflexibility, offer us limited opportunities to evaluate the system performance w.r.t changing tracking scenarios. In this paper, we study whether 3D synthetic data can replace real-world videos for association training. Specifically, we introduce a large-scale synthetic data engine named MOTX, where the motion characteristics of cameras and objects are manually configured to be similar to those in real-world datasets. We show that compared with real data, association knowledge obtained from synthetic data can achieve very similar performance on real-world test sets without domain adaption techniques. Our intriguing observation is credited to two factors. First and foremost, 3D engines can well simulate motion factors such as camera movement, camera view and object movement, so that the simulated videos can provide association modules with effective motion features. Second, experimental results show that the appearance domain gap hardly harms the learning of association knowledge. In addition, the strong customization ability of MOTX allows us to quantitatively assess the impact of motion factors on MOT, which brings new insights to the community.