 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
ShieldGemma 2: Robust and Tractable Image Content Moderation
Apr 01, 2025We introduce ShieldGemma 2, a 4B parameter image content moderation model built on Gemma 3. This model provides robust safety risk predictions across the following key harm categories: Sexually Explicit, Violence \& Gore, and Dangerous Content for synthetic images (e.g. output of any image generation model) and natural images (e.g. any image input to a Vision-Language Model). We evaluated on both internal and external benchmarks to demonstrate state-of-the-art performance compared to LlavaGuard \citep{helff2024llavaguard}, GPT-4o mini \citep{hurst2024gpt}, and the base Gemma 3 model \citep{gemma_2025} based on our policies. Additionally, we present a novel adversarial data generation pipeline which enables a controlled, diverse, and robust image generation. ShieldGemma 2 provides an open image moderation tool to advance multimodal safety and responsible AI development.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024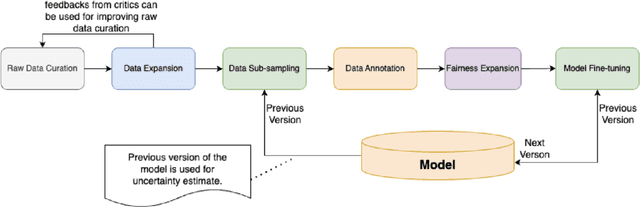
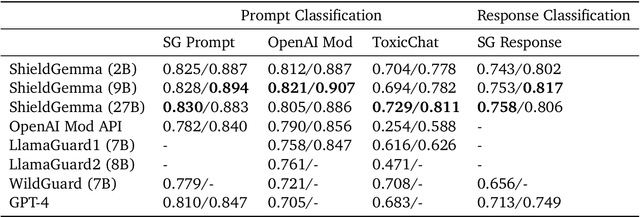

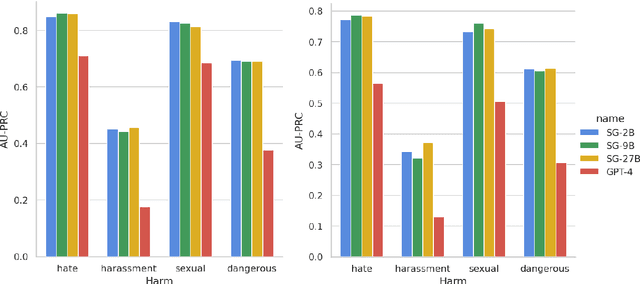
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.
Interactive Prompt Debugging with Sequence Salience
Apr 11, 2024We present Sequence Salience, a visual tool for interactive prompt debugging with input salience methods. Sequence Salience builds on widely used salience methods for text classification and single-token prediction, and extends this to a system tailored for debugging complex LLM prompts. Our system is well-suited for long texts, and expands on previous work by 1) providing controllable aggregation of token-level salience to the word, sentence, or paragraph level, making salience over long inputs tractable; and 2) supporting rapid iteration where practitioners can act on salience results, refine prompts, and run salience on the new output. We include case studies showing how Sequence Salience can help practitioners work with several complex prompting strategies, including few-shot, chain-of-thought, and constitutional principles. Sequence Salience is built on the Learning Interpretability Tool, an open-source platform for ML model visualizations, and code, notebooks, and tutorials are available at http://goo.gle/sequence-salience.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.