 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Generating Difficult-to-Translate Texts
Sep 30, 2025Machine translation benchmarks sourced from the real world are quickly obsoleted, due to most examples being easy for state-of-the-art translation models. This limits the benchmark's ability to distinguish which model is better or to reveal models' weaknesses. Current methods for creating difficult test cases, such as subsampling or from-scratch synthesis, either fall short of identifying difficult examples or suffer from a lack of diversity and naturalness. Inspired by the iterative process of human experts probing for model failures, we propose MT-breaker, a method where a large language model iteratively refines a source text to increase its translation difficulty. The LLM iteratively queries a target machine translation model to guide its generation of difficult examples. Our approach generates examples that are more challenging for the target MT model while preserving the diversity of natural texts. While the examples are tailored to a particular machine translation model during the generation, the difficulty also transfers to other models and languages.
Searching for Difficult-to-Translate Test Examples at Scale
Sep 30, 2025NLP models require test data that are sufficiently challenging. The difficulty of an example is linked to the topic it originates from (''seed topic''). The relationship between the topic and the difficulty of its instances is stochastic in nature: an example about a difficult topic can happen to be easy, and vice versa. At the scale of the Internet, there are tens of thousands of potential topics, and finding the most difficult one by drawing and evaluating a large number of examples across all topics is computationally infeasible. We formalize this task and treat it as a multi-armed bandit problem. In this framework, each topic is an ''arm,'' and pulling an arm (at a cost) involves drawing a single example, evaluating it, and measuring its difficulty. The goal is to efficiently identify the most difficult topics within a fixed computational budget. We illustrate the bandit problem setup of finding difficult examples for the task of machine translation. We find that various bandit strategies vastly outperform baseline methods like brute-force searching the most challenging topics.
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025
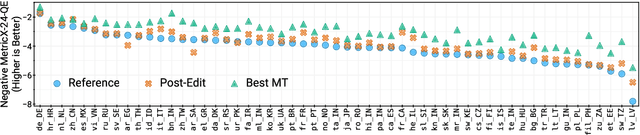


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
From Jack of All Trades to Master of One: Specializing LLM-based Autoraters to a Test Set
Nov 23, 2024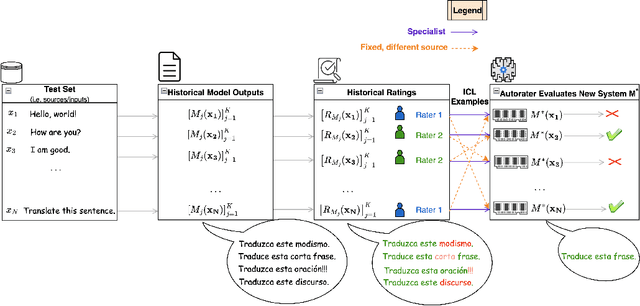

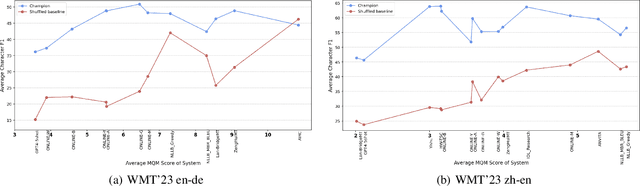

As LLMs continue to become more powerful and versatile, human evaluation has quickly become intractable at scale and reliance on automatic metrics has become the norm. Recently, it has been shown that LLMs are themselves state-of-the-art evaluators for many tasks. These Autoraters are typically designed so that they generalize to new systems and test sets. In practice, however, evaluation is performed on a small set of fixed, canonical test sets, which are carefully curated to measure certain capabilities of interest and are not changed frequently. In this work, we design a method which specializes a prompted Autorater to a given test set, by leveraging historical ratings on the test set to construct in-context learning (ICL) examples. We evaluate our Specialist method on the task of fine-grained machine translation evaluation, and show that it dramatically outperforms the state-of-the-art XCOMET metric by 54% and 119% on the WMT'23 and WMT'24 test sets, respectively. We perform extensive analyses to understand the representations learned by our Specialist metrics, and how variability in rater behavior affects their performance. We also verify the generalizability and robustness of our Specialist method for designing automatic metrics across different numbers of ICL examples, LLM backbones, systems to evaluate, and evaluation tasks.
Learning from others' mistakes: Finetuning machine translation models with span-level error annotations
Oct 21, 2024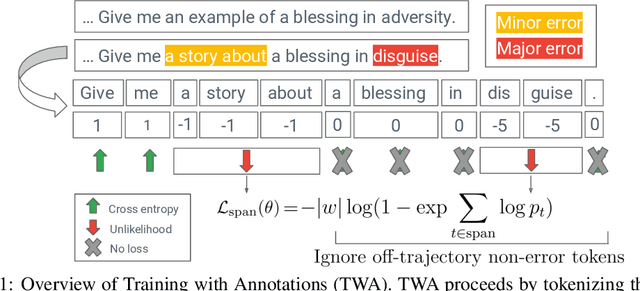


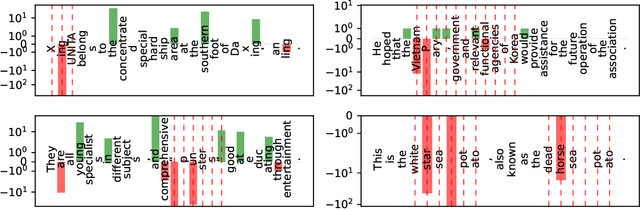
Despite growing interest in incorporating feedback to improve language models, most efforts focus only on sequence-level annotations. In this work, we explore the potential of utilizing fine-grained span-level annotations from offline datasets to improve model quality. We develop a simple finetuning algorithm, called Training with Annotations (TWA), to directly train machine translation models on such annotated data. TWA utilizes targeted span-level error information while also flexibly learning what to penalize within a span. Moreover, TWA considers the overall trajectory of a sequence when deciding which non-error spans to utilize as positive signals. Experiments on English-German and Chinese-English machine translation show that TWA outperforms baselines such as Supervised FineTuning on sequences filtered for quality and Direct Preference Optimization on pairs constructed from the same data.
MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task
Oct 04, 2024In this paper, we present the MetricX-24 submissions to the WMT24 Metrics Shared Task and provide details on the improvements we made over the previous version of MetricX. Our primary submission is a hybrid reference-based/-free metric, which can score a translation irrespective of whether it is given the source segment, the reference, or both. The metric is trained on previous WMT data in a two-stage fashion, first on the DA ratings only, then on a mixture of MQM and DA ratings. The training set in both stages is augmented with synthetic examples that we created to make the metric more robust to several common failure modes, such as fluent but unrelated translation, or undertranslation. We demonstrate the benefits of the individual modifications via an ablation study, and show a significant performance increase over MetricX-23 on the WMT23 MQM ratings, as well as our new synthetic challenge set.
Introducing the NewsPaLM MBR and QE Dataset: LLM-Generated High-Quality Parallel Data Outperforms Traditional Web-Crawled Data
Aug 14, 2024Recent research in neural machine translation (NMT) has shown that training on high-quality machine-generated data can outperform training on human-generated data. This work accompanies the first-ever release of a LLM-generated, MBR-decoded and QE-reranked dataset with both sentence-level and multi-sentence examples. We perform extensive experiments to demonstrate the quality of our dataset in terms of its downstream impact on NMT model performance. We find that training from scratch on our (machine-generated) dataset outperforms training on the (web-crawled) WMT'23 training dataset (which is 300 times larger), and also outperforms training on the top-quality subset of the WMT'23 training dataset. We also find that performing self-distillation by finetuning the LLM which generated this dataset outperforms the LLM's strong few-shot baseline. These findings corroborate the quality of our dataset, and demonstrate the value of high-quality machine-generated data in improving performance of NMT models.
Efficient Minimum Bayes Risk Decoding using Low-Rank Matrix Completion Algorithms
Jun 05, 2024Minimum Bayes Risk (MBR) decoding is a powerful decoding strategy widely used for text generation tasks, but its quadratic computational complexity limits its practical application. This paper presents a novel approach for approximating MBR decoding using matrix completion techniques, focusing on the task of machine translation. We formulate MBR decoding as a matrix completion problem, where the utility metric scores between candidate hypotheses and pseudo-reference translations form a low-rank matrix. First, we empirically show that the scores matrices indeed have a low-rank structure. Then, we exploit this by only computing a random subset of the scores and efficiently recover the missing entries in the matrix by applying the Alternating Least Squares (ALS) algorithm, thereby enabling a fast approximation of the MBR decoding process. Our experimental results on machine translation tasks demonstrate that the proposed method requires 1/16 utility metric computations compared to vanilla MBR decoding while achieving equal translation quality measured by COMET22 on the WMT22 dataset (en<>de and en<>ru). We also benchmark our method against other approximation methods and we show gains in quality when comparing to them.
Pinpoint, Not Criticize: Refining Large Language Models via Fine-Grained Actionable Feedback
Nov 15, 2023



Recent improvements in text generation have leveraged human feedback to improve the quality of the generated output. However, human feedback is not always available, especially during inference. In this work, we propose an inference time optimization method FITO to use fine-grained actionable feedback in the form of error type, error location and severity level that are predicted by a learned error pinpoint model for iterative refinement. FITO starts with an initial output, then iteratively incorporates the feedback via a refinement model that generates an improved output conditioned on the feedback. Given the uncertainty of consistent refined samples at iterative steps, we formulate iterative refinement into a local search problem and develop a simulated annealing based algorithm that balances exploration of the search space and optimization for output quality. We conduct experiments on three text generation tasks, including machine translation, long-form question answering (QA) and topical summarization. We observe 0.8 and 0.7 MetricX gain on Chinese-English and English-German translation, 4.5 and 1.8 ROUGE-L gain at long form QA and topic summarization respectively, with a single iteration of refinement. With our simulated annealing algorithm, we see further quality improvements, including up to 1.7 MetricX improvements over the baseline approach.