 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Deconstructing Self-Bias in LLM-generated Translation Benchmarks
Sep 30, 2025As large language models (LLMs) begin to saturate existing benchmarks, automated benchmark creation using LLMs (LLM as a benchmark) has emerged as a scalable alternative to slow and costly human curation. While these generated test sets have to potential to cheaply rank models, we demonstrate a critical flaw. LLM generated benchmarks systematically favor the model that created the benchmark, they exhibit self bias on low resource languages to English translation tasks. We show three key findings on automatic benchmarking of LLMs for translation: First, this bias originates from two sources: the generated test data (LLM as a testset) and the evaluation method (LLM as an evaluator), with their combination amplifying the effect. Second, self bias in LLM as a benchmark is heavily influenced by the model's generation capabilities in the source language. For instance, we observe more pronounced bias in into English translation, where the model's generation system is developed, than in out of English translation tasks. Third, we observe that low diversity in source text is one attribution to self bias. Our results suggest that improving the diversity of these generated source texts can mitigate some of the observed self bias.
Searching for Difficult-to-Translate Test Examples at Scale
Sep 30, 2025NLP models require test data that are sufficiently challenging. The difficulty of an example is linked to the topic it originates from (''seed topic''). The relationship between the topic and the difficulty of its instances is stochastic in nature: an example about a difficult topic can happen to be easy, and vice versa. At the scale of the Internet, there are tens of thousands of potential topics, and finding the most difficult one by drawing and evaluating a large number of examples across all topics is computationally infeasible. We formalize this task and treat it as a multi-armed bandit problem. In this framework, each topic is an ''arm,'' and pulling an arm (at a cost) involves drawing a single example, evaluating it, and measuring its difficulty. The goal is to efficiently identify the most difficult topics within a fixed computational budget. We illustrate the bandit problem setup of finding difficult examples for the task of machine translation. We find that various bandit strategies vastly outperform baseline methods like brute-force searching the most challenging topics.
SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
Jun 05, 2025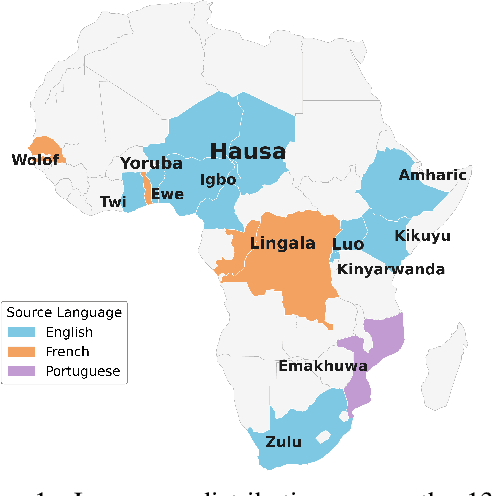
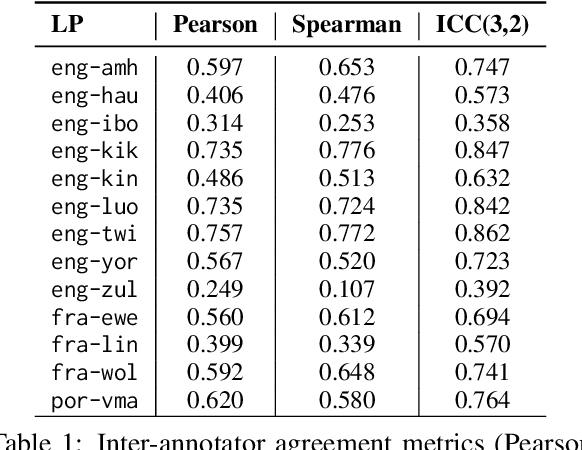
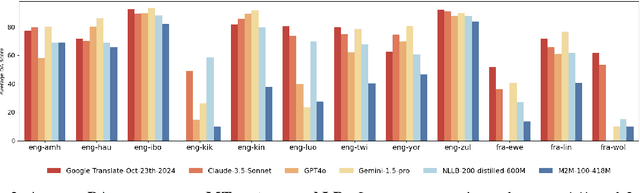
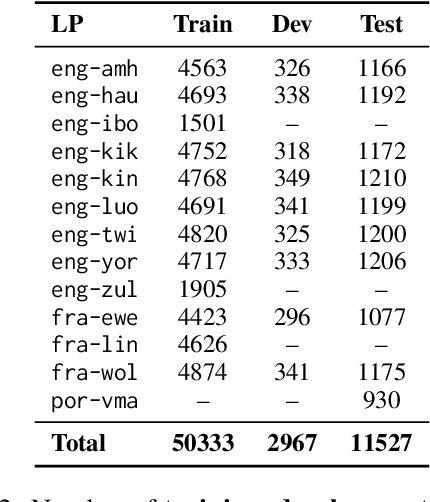
Evaluating machine translation (MT) quality for under-resourced African languages remains a significant challenge, as existing metrics often suffer from limited language coverage and poor performance in low-resource settings. While recent efforts, such as AfriCOMET, have addressed some of the issues, they are still constrained by small evaluation sets, a lack of publicly available training data tailored to African languages, and inconsistent performance in extremely low-resource scenarios. In this work, we introduce SSA-MTE, a large-scale human-annotated MT evaluation (MTE) dataset covering 13 African language pairs from the News domain, with over 63,000 sentence-level annotations from a diverse set of MT systems. Based on this data, we develop SSA-COMET and SSA-COMET-QE, improved reference-based and reference-free evaluation metrics. We also benchmark prompting-based approaches using state-of-the-art LLMs like GPT-4o and Claude. Our experimental results show that SSA-COMET models significantly outperform AfriCOMET and are competitive with the strongest LLM (Gemini 2.5 Pro) evaluated in our study, particularly on low-resource languages such as Twi, Luo, and Yoruba. All resources are released under open licenses to support future research.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Enhancing Human Evaluation in Machine Translation with Comparative Judgment
Feb 25, 2025

Human evaluation is crucial for assessing rapidly evolving language models but is influenced by annotator proficiency and task design. This study explores the integration of comparative judgment into human annotation for machine translation (MT) and evaluates three annotation setups-point-wise Multidimensional Quality Metrics (MQM), side-by-side (SxS) MQM, and its simplified version SxS relative ranking (RR). In MQM, annotators mark error spans with categories and severity levels. SxS MQM extends MQM to pairwise error annotation for two translations of the same input, while SxS RR focuses on selecting the better output without labeling errors. Key findings are: (1) the SxS settings achieve higher inter-annotator agreement than MQM; (2) SxS MQM enhances inter-translation error marking consistency compared to MQM by, on average, 38.5% for explicitly compared MT systems and 19.5% for others; (3) all annotation settings return stable system rankings, with SxS RR offering a more efficient alternative to (SxS) MQM; (4) the SxS settings highlight subtle errors overlooked in MQM without altering absolute system evaluations. To spur further research, we will release the triply annotated datasets comprising 377 ZhEn and 104 EnDe annotation examples.
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
Overestimation in LLM Evaluation: A Controlled Large-Scale Study on Data Contamination's Impact on Machine Translation
Jan 30, 2025



Data contamination -- the accidental consumption of evaluation examples within the pre-training data -- can undermine the validity of evaluation benchmarks. In this paper, we present a rigorous analysis of the effects of contamination on language models at 1B and 8B scales on the machine translation task. Starting from a carefully decontaminated train-test split, we systematically introduce contamination at various stages, scales, and data formats to isolate its effect and measure its impact on performance metrics. Our experiments reveal that contamination with both source and target substantially inflates BLEU scores, and this inflation is 2.5 times larger (up to 30 BLEU points) for 8B compared to 1B models. In contrast, source-only and target-only contamination generally produce smaller, less consistent over-estimations. Finally, we study how the temporal distribution and frequency of contaminated samples influence performance over-estimation across languages with varying degrees of data resources.
Mitigating Metric Bias in Minimum Bayes Risk Decoding
Nov 05, 2024
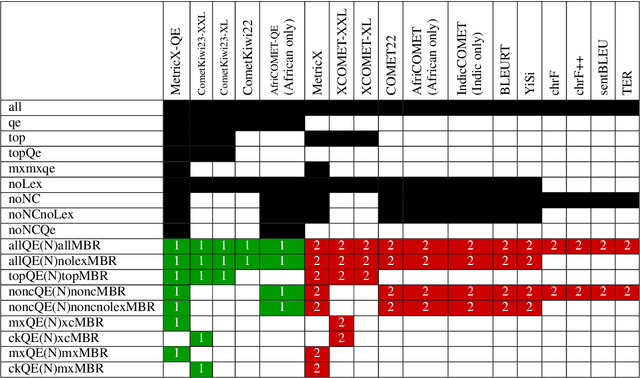
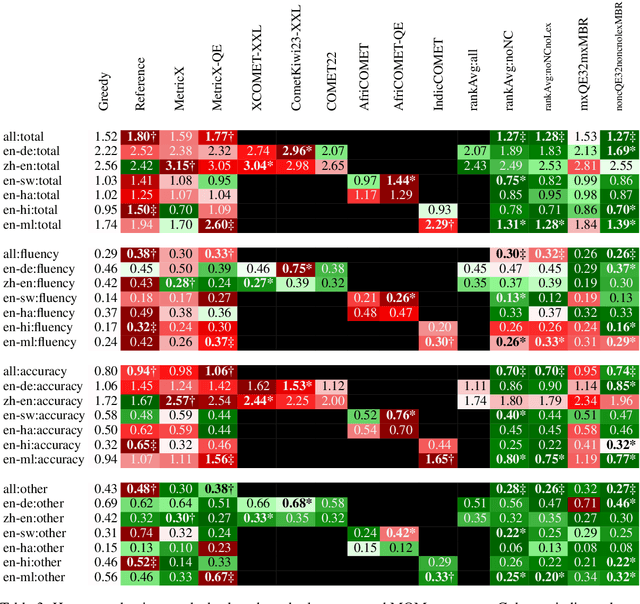
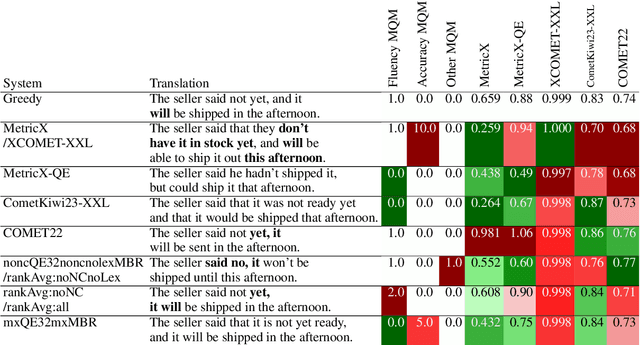
While Minimum Bayes Risk (MBR) decoding using metrics such as COMET or MetricX has outperformed traditional decoding methods such as greedy or beam search, it introduces a challenge we refer to as metric bias. As MBR decoding aims to produce translations that score highly according to a specific utility metric, this very process makes it impossible to use the same metric for both decoding and evaluation, as improvements might simply be due to reward hacking rather than reflecting real quality improvements. In this work we find that compared to human ratings, neural metrics not only overestimate the quality of MBR decoding when the same metric is used as the utility metric, but they also overestimate the quality of MBR/QE decoding with other neural utility metrics as well. We also show that the metric bias issue can be mitigated by using an ensemble of utility metrics during MBR decoding: human evaluations show that MBR decoding using an ensemble of utility metrics outperforms a single utility metric.
Beyond Human-Only: Evaluating Human-Machine Collaboration for Collecting High-Quality Translation Data
Oct 14, 2024
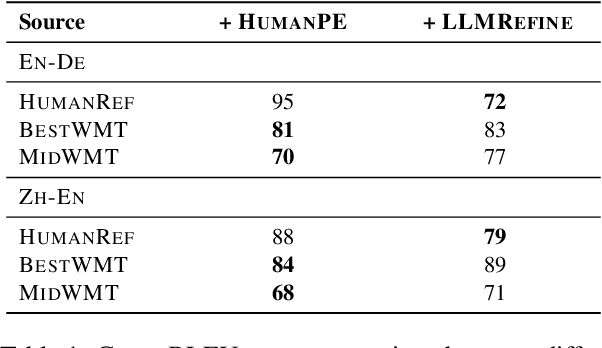
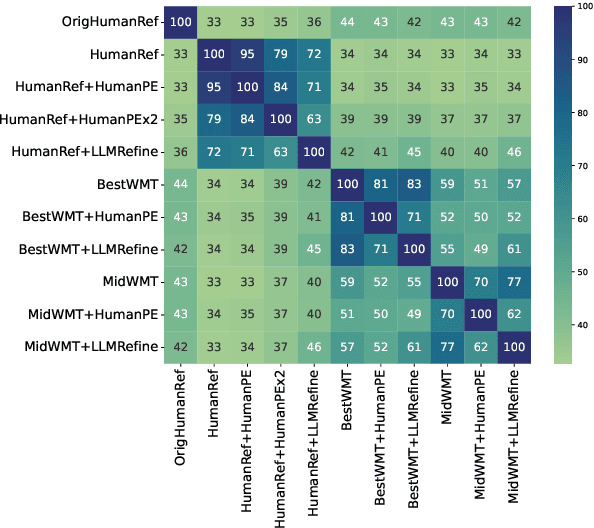
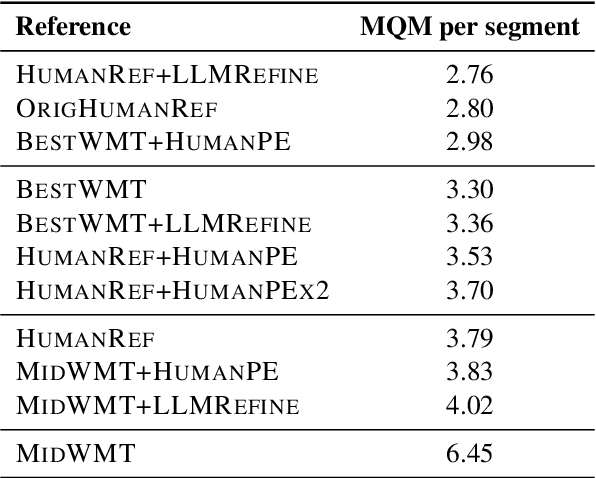
Collecting high-quality translations is crucial for the development and evaluation of machine translation systems. However, traditional human-only approaches are costly and slow. This study presents a comprehensive investigation of 11 approaches for acquiring translation data, including human-only, machineonly, and hybrid approaches. Our findings demonstrate that human-machine collaboration can match or even exceed the quality of human-only translations, while being more cost-efficient. Error analysis reveals the complementary strengths between human and machine contributions, highlighting the effectiveness of collaborative methods. Cost analysis further demonstrates the economic benefits of human-machine collaboration methods, with some approaches achieving top-tier quality at around 60% of the cost of traditional methods. We release a publicly available dataset containing nearly 18,000 segments of varying translation quality with corresponding human ratings to facilitate future research.