 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapters for Altering LLM Vocabularies: What Languages Benefit the Most?
Oct 12, 2024



Vocabulary adaptation, which integrates new vocabulary into pre-trained language models (LMs), enables expansion to new languages and mitigates token over-fragmentation. However, existing approaches are limited by their reliance on heuristic or external embeddings. We propose VocADT, a novel method for vocabulary adaptation using adapter modules that are trained to learn the optimal linear combination of existing embeddings while keeping the model's weights fixed. VocADT offers a flexible and scalable solution without requiring external resources or language constraints. Across 11 languages-with various scripts, resource availability, and fragmentation-we demonstrate that VocADT outperforms the original Mistral model and other baselines across various multilingual tasks. We find that Latin-script languages and highly fragmented languages benefit the most from vocabulary adaptation. We further fine-tune the adapted model on the generative task of machine translation and find that vocabulary adaptation is still beneficial after fine-tuning and that VocADT is the most effective method.
X-ALMA: Plug & Play Modules and Adaptive Rejection for Quality Translation at Scale
Oct 04, 2024



Large language models (LLMs) have achieved remarkable success across various NLP tasks, yet their focus has predominantly been on English due to English-centric pre-training and limited multilingual data. While some multilingual LLMs claim to support for hundreds of languages, models often fail to provide high-quality response for mid- and low-resource languages, leading to imbalanced performance heavily skewed in favor of high-resource languages like English and Chinese. In this paper, we prioritize quality over scaling number of languages, with a focus on multilingual machine translation task, and introduce X-ALMA, a model designed with a commitment to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels. X-ALMA surpasses state-of-the-art open-source multilingual LLMs, such as Aya-101 and Aya-23, in every single translation direction on the FLORES and WMT'23 test datasets according to COMET-22. This is achieved by plug-and-play language-specific module architecture to prevent language conflicts during training and a carefully designed training regimen with novel optimization methods to maximize the translation performance. At the final stage of training regimen, our proposed Adaptive Rejection Preference Optimization (ARPO) surpasses existing preference optimization methods in translation tasks.
Improving Statistical Significance in Human Evaluation of Automatic Metrics via Soft Pairwise Accuracy
Sep 15, 2024



Selecting an automatic metric that best emulates human judgments is often non-trivial, because there is no clear definition of "best emulates." A meta-metric is required to compare the human judgments to the automatic metric judgments, and metric rankings depend on the choice of meta-metric. We propose Soft Pairwise Accuracy (SPA), a new meta-metric that builds on Pairwise Accuracy (PA) but incorporates the statistical significance of both the human judgments and the metric judgments. SPA allows for more fine-grained comparisons between systems than a simplistic binary win/loss, and addresses a number of shortcomings with PA: it is more stable with respect to both the number of systems and segments used for evaluation, it mitigates the issue of metric ties due to quantization, and it produces more statistically significant results. SPA was selected as the official system-level metric for the 2024 WMT metric shared task.
On-the-Fly Fusion of Large Language Models and Machine Translation
Nov 14, 2023



We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
SOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.
How to Choose How to Choose Your Chatbot: A Massively Multi-System MultiReference Data Set for Dialog Metric Evaluation
May 23, 2023
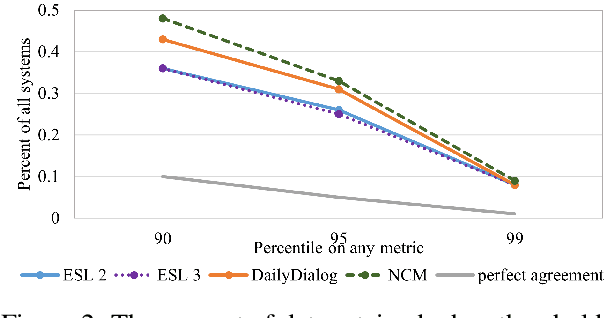
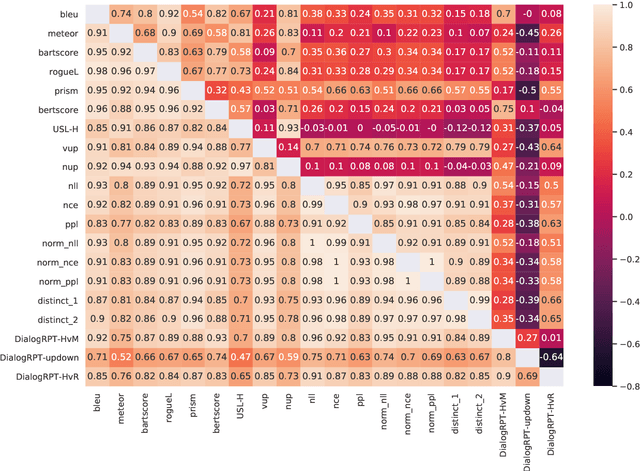
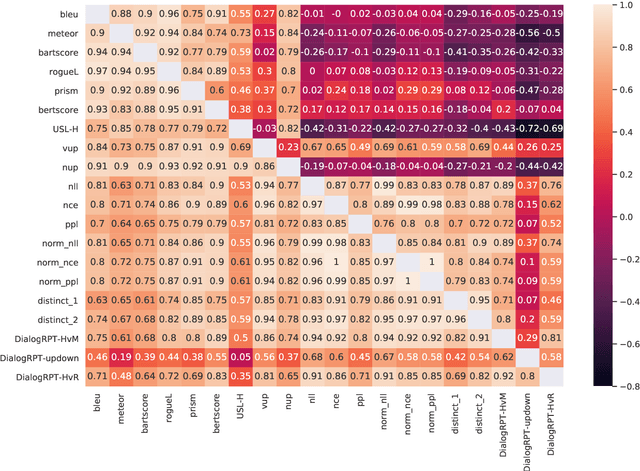
We release MMSMR, a Massively Multi-System MultiReference dataset to enable future work on metrics and evaluation for dialog. Automatic metrics for dialogue evaluation should be robust proxies for human judgments; however, the verification of robustness is currently far from satisfactory. To quantify the robustness correlation and understand what is necessary in a test set, we create and release an 8-reference dialog dataset by extending single-reference evaluation sets and introduce this new language learning conversation dataset. We then train 1750 systems and evaluate them on our novel test set and the DailyDialog dataset. We release the novel test set, and model hyper parameters, inference outputs, and metric scores for each system on a variety of datasets.
Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation
Oct 12, 2021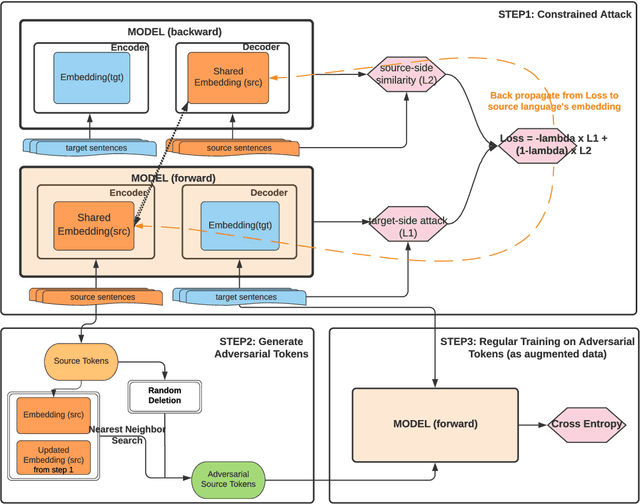

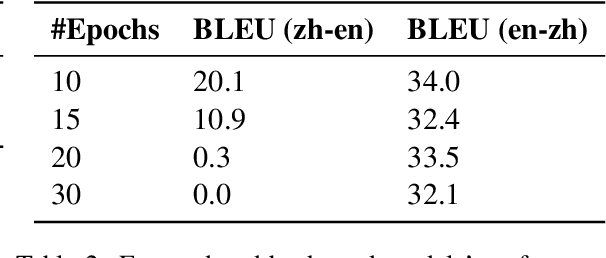
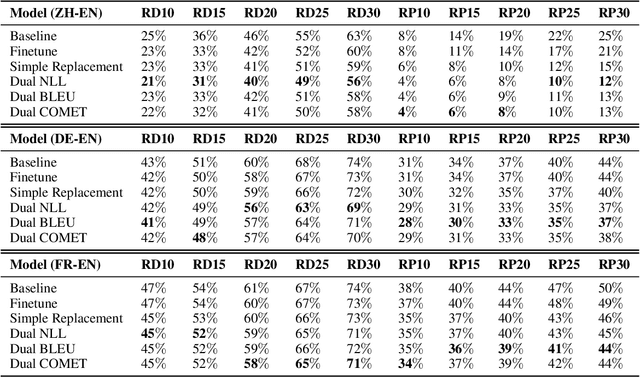
Neural Machine Translation (NMT) models are known to suffer from noisy inputs. To make models robust, we generate adversarial augmentation samples that attack the model and preserve the source-side semantic meaning at the same time. To generate such samples, we propose a doubly-trained architecture that pairs two NMT models of opposite translation directions with a joint loss function, which combines the target-side attack and the source-side semantic similarity constraint. The results from our experiments across three different language pairs and two evaluation metrics show that these adversarial samples improve the model robustness.
SMRT Chatbots: Improving Non-Task-Oriented Dialog with Simulated Multiple Reference Training
Nov 01, 2020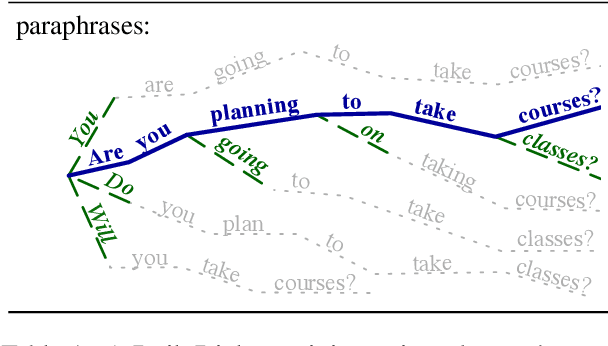

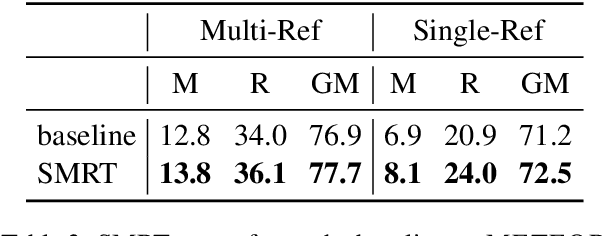
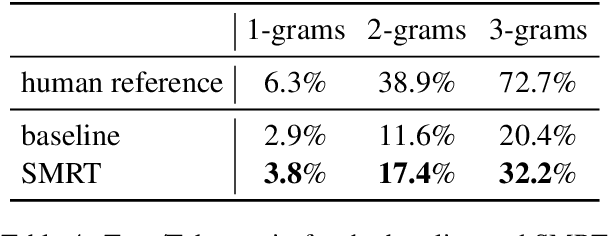
Non-task-oriented dialog models suffer from poor quality and non-diverse responses. To overcome limited conversational data, we apply Simulated Multiple Reference Training (SMRT; Khayrallah et al., 2020), and use a paraphraser to simulate multiple responses per training prompt. We find SMRT improves over a strong Transformer baseline as measured by human and automatic quality scores and lexical diversity. We also find SMRT is comparable to pretraining in human evaluation quality, and outperforms pretraining on automatic quality and lexical diversity, without requiring related-domain dialog data.
Measuring the `I don't know' Problem through the Lens of Gricean Quantity
Oct 24, 2020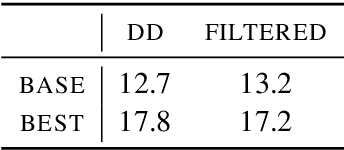
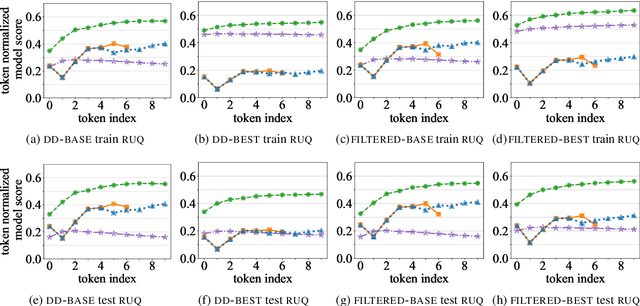
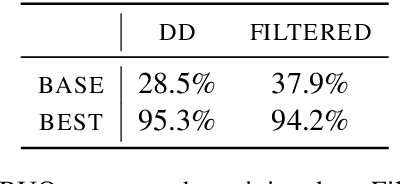
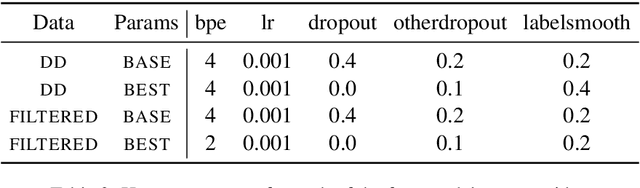
We consider the intrinsic evaluation of neural generative dialog models through the lens of Grices Maxims of Conversation (1975). Based on the maxim of Quantity (be informative), we propose Relative Utterance Quantity (RUQ) to diagnose the `I don't know' problem. The RUQ diagnostic compares the model score of a generic response to that of the reference response. We find that for reasonable baseline models, `I don't know' is preferred over the reference more than half the time, but this can be mitigated with hyperparameter tuning.
Simulated Multiple Reference Training Improves Low-Resource Machine Translation
Apr 30, 2020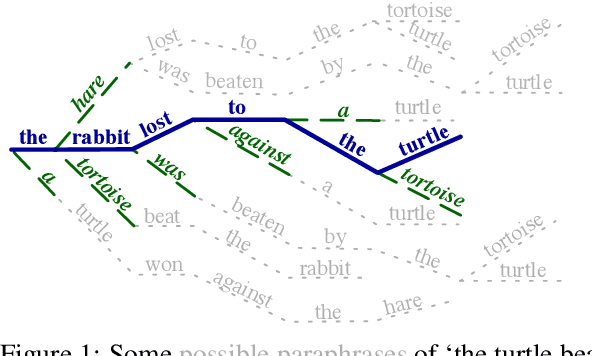
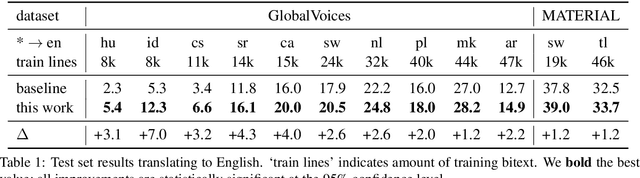
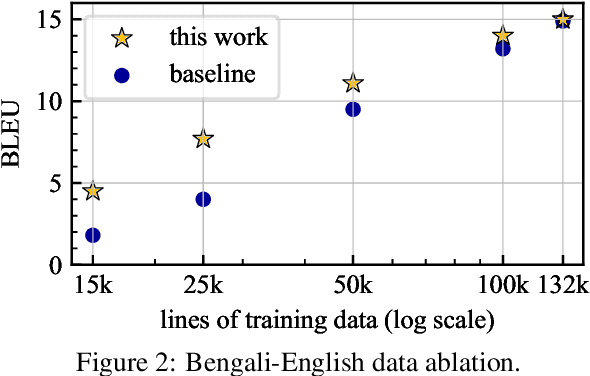
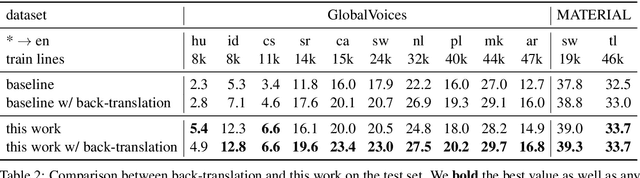
Many valid translations exist for a given sentence, and yet machine translation (MT) is trained with a single reference translation, exacerbating data sparsity in low-resource settings. We introduce a novel MT training method that approximates the full space of possible translations by: sampling a paraphrase of the reference sentence from a paraphraser and training the MT model to predict the paraphraser's distribution over possible tokens. With an English paraphraser, we demonstrate the effectiveness of our method in low-resource settings, with gains of 1.2 to 7 BLEU.