 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Cultural Bias in LLMs via Multi-Agent Cultural Debate
Jan 17, 2026Large language models (LLMs) exhibit systematic Western-centric bias, yet whether prompting in non-Western languages (e.g., Chinese) can mitigate this remains understudied. Answering this question requires rigorous evaluation and effective mitigation, but existing approaches fall short on both fronts: evaluation methods force outputs into predefined cultural categories without a neutral option, while mitigation relies on expensive multi-cultural corpora or agent frameworks that use functional roles (e.g., Planner--Critique) lacking explicit cultural representation. To address these gaps, we introduce CEBiasBench, a Chinese--English bilingual benchmark, and Multi-Agent Vote (MAV), which enables explicit ``no bias'' judgments. Using this framework, we find that Chinese prompting merely shifts bias toward East Asian perspectives rather than eliminating it. To mitigate such persistent bias, we propose Multi-Agent Cultural Debate (MACD), a training-free framework that assigns agents distinct cultural personas and orchestrates deliberation via a "Seeking Common Ground while Reserving Differences" strategy. Experiments demonstrate that MACD achieves 57.6% average No Bias Rate evaluated by LLM-as-judge and 86.0% evaluated by MAV (vs. 47.6% and 69.0% baseline using GPT-4o as backbone) on CEBiasBench and generalizes to the Arabic CAMeL benchmark, confirming that explicit cultural representation in agent frameworks is essential for cross-cultural fairness.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Word Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025
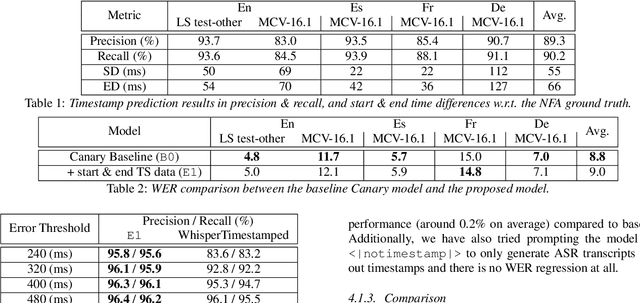
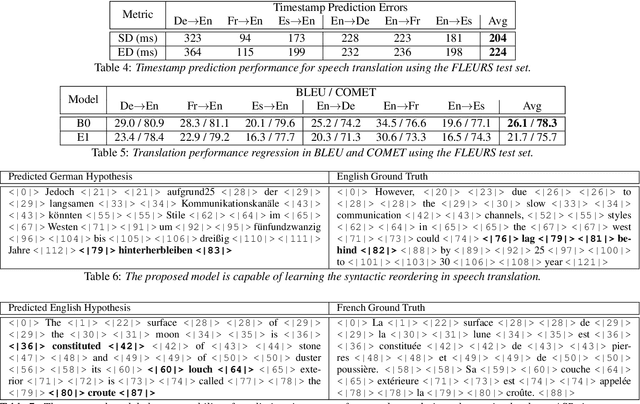
We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
Plan2Align: Predictive Planning Based Test-Time Preference Alignment in Paragraph-Level Machine Translation
Feb 28, 2025Machine Translation (MT) has been predominantly designed for sentence-level translation using transformer-based architectures. While next-token prediction based Large Language Models (LLMs) demonstrate strong capabilities in long-text translation, non-extensive language models often suffer from omissions and semantic inconsistencies when processing paragraphs. Existing preference alignment methods improve sentence-level translation but fail to ensure coherence over extended contexts due to the myopic nature of next-token generation. We introduce Plan2Align, a test-time alignment framework that treats translation as a predictive planning problem, adapting Model Predictive Control to iteratively refine translation outputs. Experiments on WMT24 Discourse-Level Literary Translation show that Plan2Align significantly improves paragraph-level translation, achieving performance surpassing or on par with the existing training-time and test-time alignment methods on LLaMA-3.1 8B.
Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains
Feb 28, 2024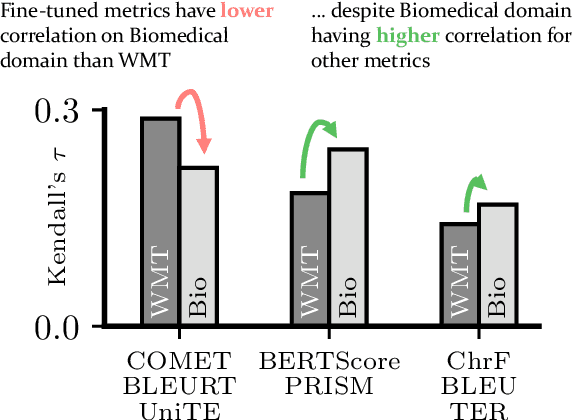
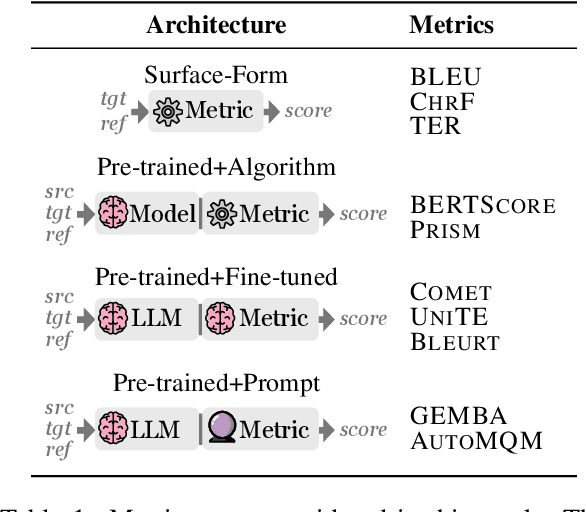
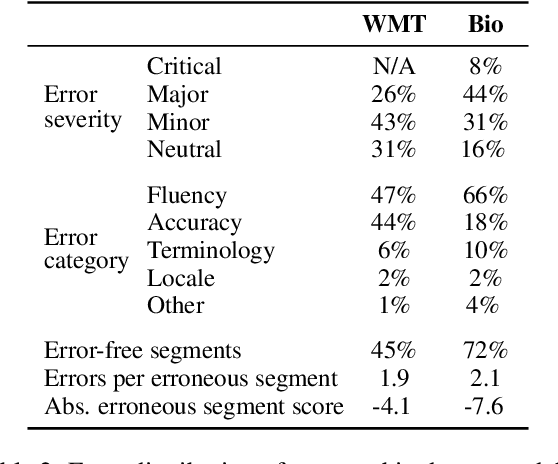
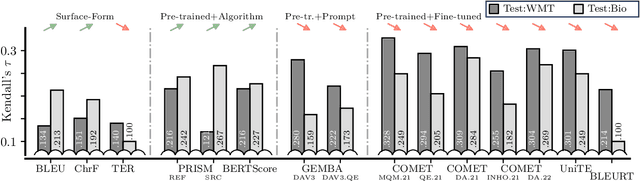
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation
Oct 12, 2021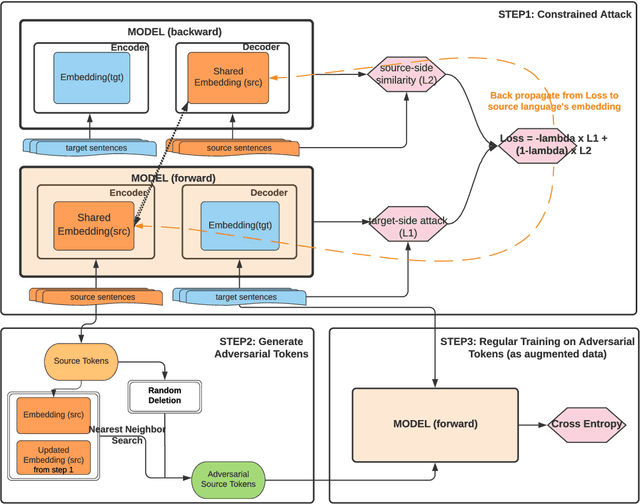

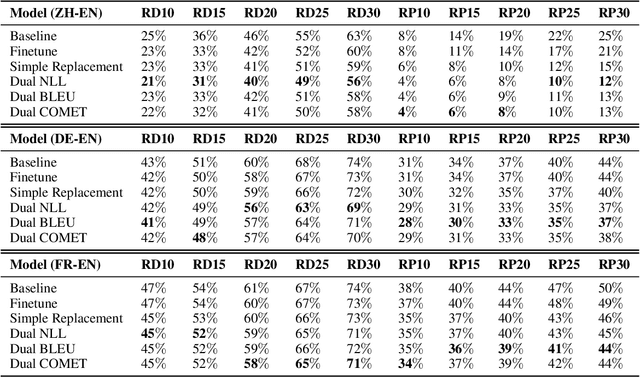
Neural Machine Translation (NMT) models are known to suffer from noisy inputs. To make models robust, we generate adversarial augmentation samples that attack the model and preserve the source-side semantic meaning at the same time. To generate such samples, we propose a doubly-trained architecture that pairs two NMT models of opposite translation directions with a joint loss function, which combines the target-side attack and the source-side semantic similarity constraint. The results from our experiments across three different language pairs and two evaluation metrics show that these adversarial samples improve the model robustness.
The JHU-Microsoft Submission for WMT21 Quality Estimation Shared Task
Sep 17, 2021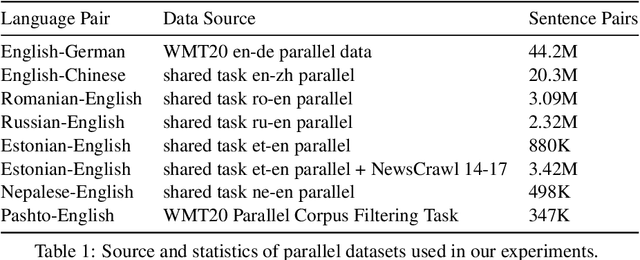
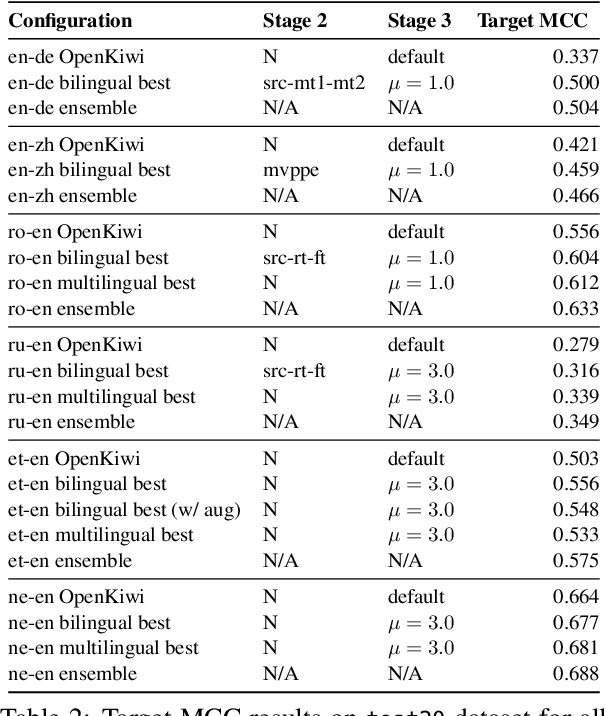
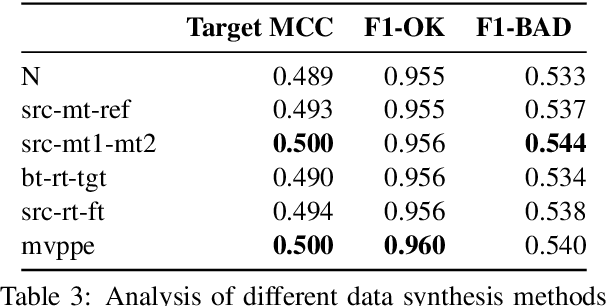
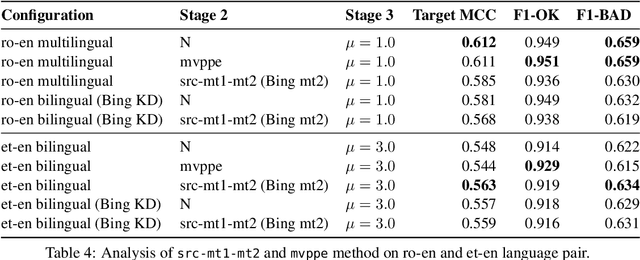
This paper presents the JHU-Microsoft joint submission for WMT 2021 quality estimation shared task. We only participate in Task 2 (post-editing effort estimation) of the shared task, focusing on the target-side word-level quality estimation. The techniques we experimented with include Levenshtein Transformer training and data augmentation with a combination of forward, backward, round-trip translation, and pseudo post-editing of the MT output. We demonstrate the competitiveness of our system compared to the widely adopted OpenKiwi-XLM baseline. Our system is also the top-ranking system on the MT MCC metric for the English-German language pair.