 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk-wise Attention Transducers for Fast and Accurate Streaming Speech-to-Text
Feb 27, 2026We propose Chunk-wise Attention Transducer (CHAT), a novel extension to RNN-T models that processes audio in fixed-size chunks while employing cross-attention within each chunk. This hybrid approach maintains RNN-T's streaming capability while introducing controlled flexibility for local alignment modeling. CHAT significantly reduces the temporal dimension that RNN-T must handle, yielding substantial efficiency improvements: up to 46.2% reduction in peak training memory, up to 1.36X faster training, and up to 1.69X faster inference. Alongside these efficiency gains, CHAT achieves consistent accuracy improvements over RNN-T across multiple languages and tasks -- up to 6.3% relative WER reduction for speech recognition and up to 18.0% BLEU improvement for speech translation. The method proves particularly effective for speech translation, where RNN-T's strict monotonic alignment hurts performance. Our results demonstrate that the CHAT model offers a practical solution for deploying more capable streaming speech models without sacrificing real-time constraints.
Word Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025
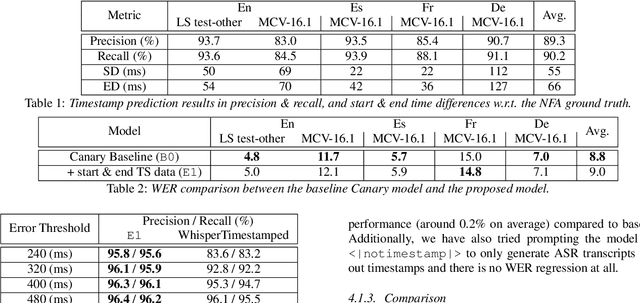
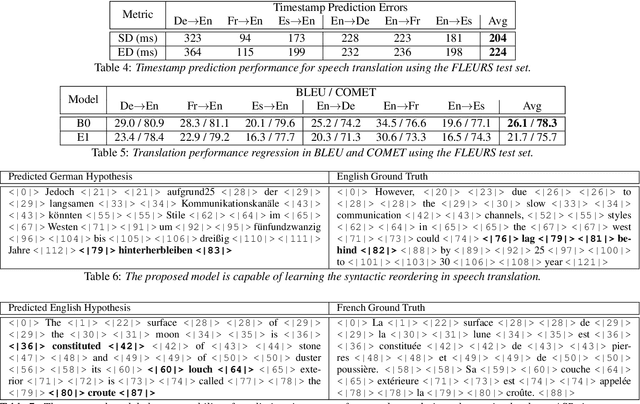
We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
WIND: Accelerated RNN-T Decoding with Windowed Inference for Non-blank Detection
May 19, 2025We propose Windowed Inference for Non-blank Detection (WIND), a novel strategy that significantly accelerates RNN-T inference without compromising model accuracy. During model inference, instead of processing frames sequentially, WIND processes multiple frames simultaneously within a window in parallel, allowing the model to quickly locate non-blank predictions during decoding, resulting in significant speed-ups. We implement WIND for greedy decoding, batched greedy decoding with label-looping techniques, and also propose a novel beam-search decoding method. Experiments on multiple datasets with different conditions show that our method, when operating in greedy modes, speeds up as much as 2.4X compared to the baseline sequential approach while maintaining identical Word Error Rate (WER) performance. Our beam-search algorithm achieves slightly better accuracy than alternative methods, with significantly improved speed. We will open-source our WIND implementation.
Three-in-One: Fast and Accurate Transducer for Hybrid-Autoregressive ASR
Oct 03, 2024



We present \textbf{H}ybrid-\textbf{A}utoregressive \textbf{IN}ference Tr\textbf{AN}sducers (HAINAN), a novel architecture for speech recognition that extends the Token-and-Duration Transducer (TDT) model. Trained with randomly masked predictor network outputs, HAINAN supports both autoregressive inference with all network components and non-autoregressive inference without the predictor. Additionally, we propose a novel semi-autoregressive inference paradigm that first generates an initial hypothesis using non-autoregressive inference, followed by refinement steps where each token prediction is regenerated using parallelized autoregression on the initial hypothesis. Experiments on multiple datasets across different languages demonstrate that HAINAN achieves efficiency parity with CTC in non-autoregressive mode and with TDT in autoregressive mode. In terms of accuracy, autoregressive HAINAN outperforms TDT and RNN-T, while non-autoregressive HAINAN significantly outperforms CTC. Semi-autoregressive inference further enhances the model's accuracy with minimal computational overhead, and even outperforms TDT results in some cases. These results highlight HAINAN's flexibility in balancing accuracy and speed, positioning it as a strong candidate for real-world speech recognition applications.
Longer is (Not Necessarily) Stronger: Punctuated Long-Sequence Training for Enhanced Speech Recognition and Translation
Sep 09, 2024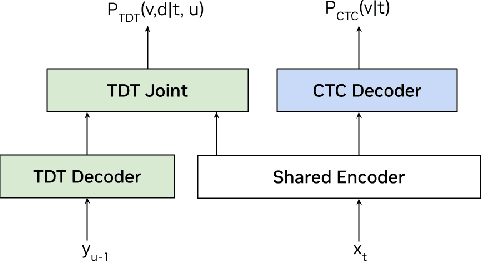
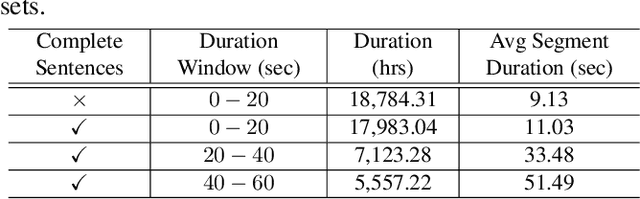

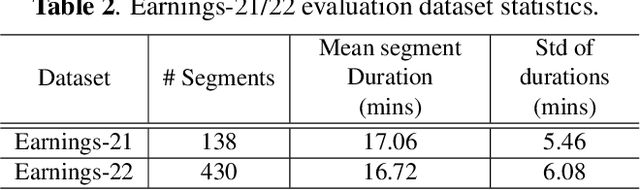
This paper presents a new method for training sequence-to-sequence models for speech recognition and translation tasks. Instead of the traditional approach of training models on short segments containing only lowercase or partial punctuation and capitalization (PnC) sentences, we propose training on longer utterances that include complete sentences with proper punctuation and capitalization. We achieve this by using the FastConformer architecture which allows training 1 Billion parameter models with sequences up to 60 seconds long with full attention. However, while training with PnC enhances the overall performance, we observed that accuracy plateaus when training on sequences longer than 40 seconds across various evaluation settings. Our proposed method significantly improves punctuation and capitalization accuracy, showing a 25% relative word error rate (WER) improvement on the Earnings-21 and Earnings-22 benchmarks. Additionally, training on longer audio segments increases the overall model accuracy across speech recognition and translation benchmarks. The model weights and training code are open-sourced though NVIDIA NeMo.
Romanization Encoding For Multilingual ASR
Jul 05, 2024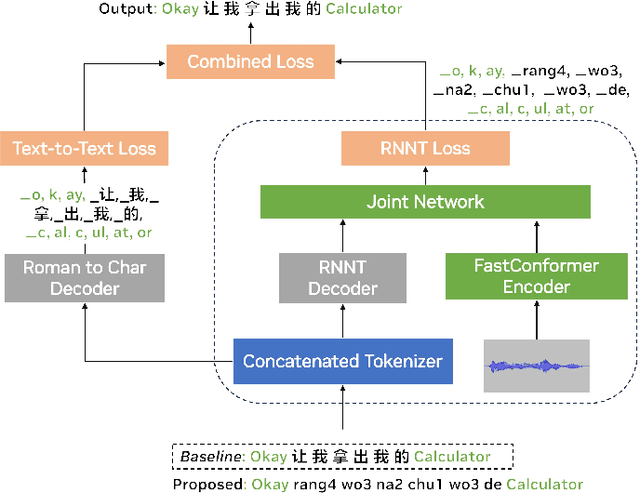


We introduce romanization encoding for script-heavy languages to optimize multilingual and code-switching Automatic Speech Recognition (ASR) systems. By adopting romanization encoding alongside a balanced concatenated tokenizer within a FastConformer-RNNT framework equipped with a Roman2Char module, we significantly reduce vocabulary and output dimensions, enabling larger training batches and reduced memory consumption. Our method decouples acoustic modeling and language modeling, enhancing the flexibility and adaptability of the system. In our study, applying this method to Mandarin-English ASR resulted in a remarkable 63.51% vocabulary reduction and notable performance gains of 13.72% and 15.03% on SEAME code-switching benchmarks. Ablation studies on Mandarin-Korean and Mandarin-Japanese highlight our method's strong capability to address the complexities of other script-heavy languages, paving the way for more versatile and effective multilingual ASR systems.
Label-Looping: Highly Efficient Decoding for Transducers
Jun 10, 2024



This paper introduces a highly efficient greedy decoding algorithm for Transducer inference. We propose a novel data structure using CUDA tensors to represent partial hypotheses in a batch that supports parallelized hypothesis manipulations. During decoding, our algorithm maximizes GPU parallelism by adopting a nested-loop design, where the inner loop consumes all blank predictions, while non-blank predictions are handled in the outer loop. Our algorithm is general-purpose and can work with both conventional Transducers and Token-and-Duration Transducers. Experiments show that the label-looping algorithm can bring a speedup up to 2.0X compared to conventional batched decoding algorithms when using batch size 32, and can be combined with other compiler or GPU call-related techniques to bring more speedup. We will open-source our implementation to benefit the research community.
Speed of Light Exact Greedy Decoding for RNN-T Speech Recognition Models on GPU
Jun 06, 2024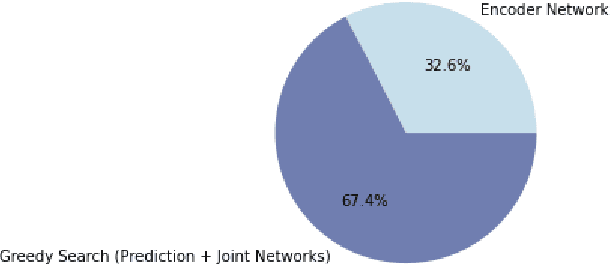
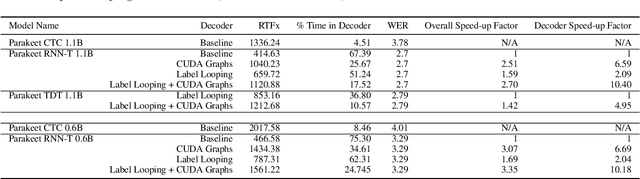

The vast majority of inference time for RNN Transducer (RNN-T) models today is spent on decoding. Current state-of-the-art RNN-T decoding implementations leave the GPU idle ~80% of the time. Leveraging a new CUDA 12.4 feature, CUDA graph conditional nodes, we present an exact GPU-based implementation of greedy decoding for RNN-T models that eliminates this idle time. Our optimizations speed up a 1.1 billion parameter RNN-T model end-to-end by a factor of 2.5x. This technique can applied to the "label looping" alternative greedy decoding algorithm as well, achieving 1.7x and 1.4x end-to-end speedups when applied to 1.1 billion parameter RNN-T and Token and Duration Transducer models respectively. This work enables a 1.1 billion parameter RNN-T model to run only 16% slower than a similarly sized CTC model, contradicting the common belief that RNN-T models are not suitable for high throughput inference. The implementation is available in NVIDIA NeMo.
Transducers with Pronunciation-aware Embeddings for Automatic Speech Recognition
Apr 04, 2024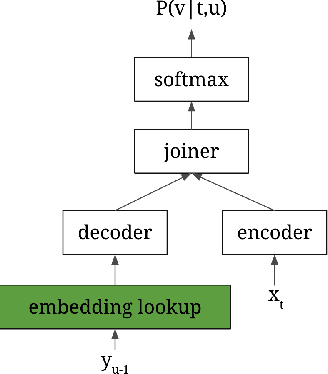

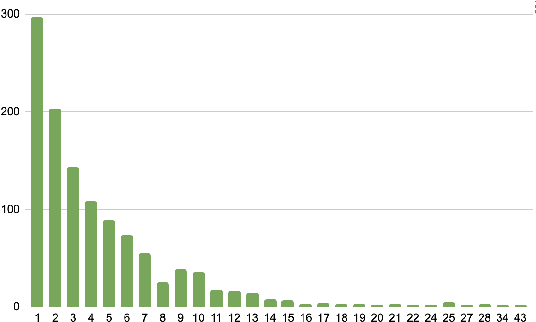
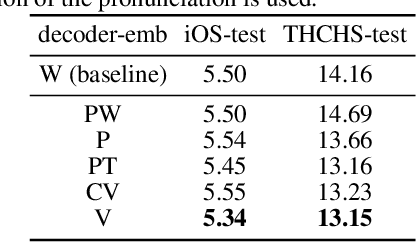
This paper proposes Transducers with Pronunciation-aware Embeddings (PET). Unlike conventional Transducers where the decoder embeddings for different tokens are trained independently, the PET model's decoder embedding incorporates shared components for text tokens with the same or similar pronunciations. With experiments conducted in multiple datasets in Mandarin Chinese and Korean, we show that PET models consistently improve speech recognition accuracy compared to conventional Transducers. Our investigation also uncovers a phenomenon that we call error chain reactions. Instead of recognition errors being evenly spread throughout an utterance, they tend to group together, with subsequent errors often following earlier ones. Our analysis shows that PET models effectively mitigate this issue by substantially reducing the likelihood of the model generating additional errors following a prior one. Our implementation will be open-sourced with the NeMo toolkit.
TDT-KWS: Fast And Accurate Keyword Spotting Using Token-and-duration Transducer
Mar 20, 2024



Designing an efficient keyword spotting (KWS) system that delivers exceptional performance on resource-constrained edge devices has long been a subject of significant attention. Existing KWS search algorithms typically follow a frame-synchronous approach, where search decisions are made repeatedly at each frame despite the fact that most frames are keyword-irrelevant. In this paper, we propose TDT-KWS, which leverages token-and-duration Transducers (TDT) for KWS tasks. We also propose a novel KWS task-specific decoding algorithm for Transducer-based models, which supports highly effective frame-asynchronous keyword search in streaming speech scenarios. With evaluations conducted on both the public Hey Snips and self-constructed LibriKWS-20 datasets, our proposed KWS-decoding algorithm produces more accurate results than conventional ASR decoding algorithms. Additionally, TDT-KWS achieves on-par or better wake word detection performance than both RNN-T and traditional TDT-ASR systems while achieving significant inference speed-up. Furthermore, experiments show that TDT-KWS is more robust to noisy environments compared to RNN-T KWS.