 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
FlexCTC: GPU-powered CTC Beam Decoding With Advanced Contextual Abilities
Aug 13, 2025While beam search improves speech recognition quality over greedy decoding, standard implementations are slow, often sequential, and CPU-bound. To fully leverage modern hardware capabilities, we present a novel open-source FlexCTC toolkit for fully GPU-based beam decoding, designed for Connectionist Temporal Classification (CTC) models. Developed entirely in Python and PyTorch, it offers a fast, user-friendly, and extensible alternative to traditional C++, CUDA, or WFST-based decoders. The toolkit features a high-performance, fully batched GPU implementation with eliminated CPU-GPU synchronization and minimized kernel launch overhead via CUDA Graphs. It also supports advanced contextualization techniques, including GPU-powered N-gram language model fusion and phrase-level boosting. These features enable accurate and efficient decoding, making them suitable for both research and production use.
TurboBias: Universal ASR Context-Biasing powered by GPU-accelerated Phrase-Boosting Tree
Aug 12, 2025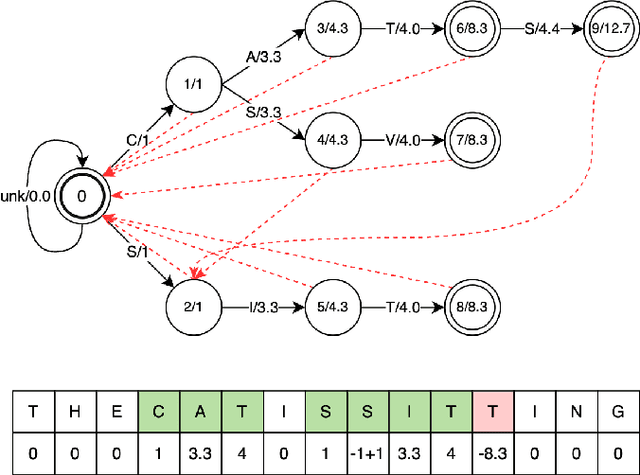
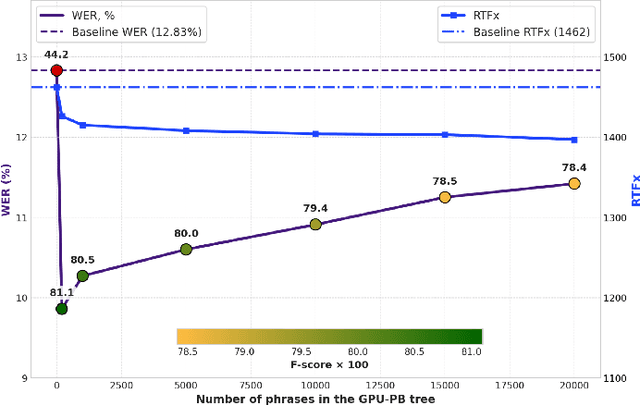
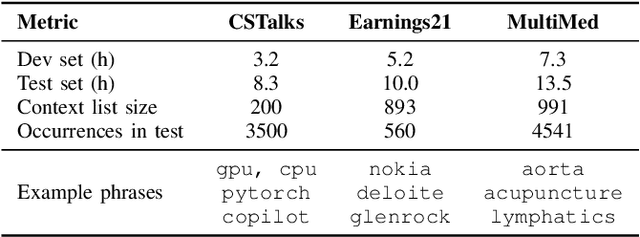
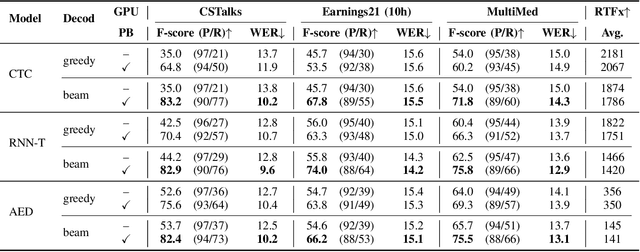
Recognizing specific key phrases is an essential task for contextualized Automatic Speech Recognition (ASR). However, most existing context-biasing approaches have limitations associated with the necessity of additional model training, significantly slow down the decoding process, or constrain the choice of the ASR system type. This paper proposes a universal ASR context-biasing framework that supports all major types: CTC, Transducers, and Attention Encoder-Decoder models. The framework is based on a GPU-accelerated word boosting tree, which enables it to be used in shallow fusion mode for greedy and beam search decoding without noticeable speed degradation, even with a vast number of key phrases (up to 20K items). The obtained results showed high efficiency of the proposed method, surpassing the considered open-source context-biasing approaches in accuracy and decoding speed. Our context-biasing framework is open-sourced as a part of the NeMo toolkit.
Unified Semi-Supervised Pipeline for Automatic Speech Recognition
Jun 09, 2025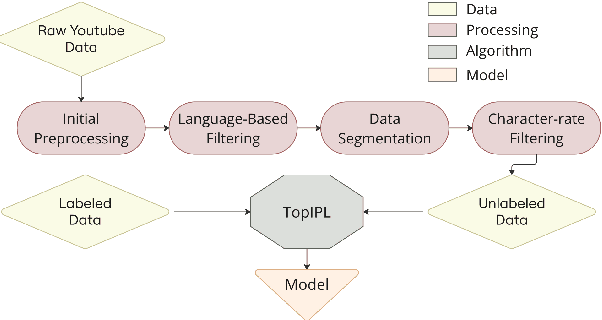
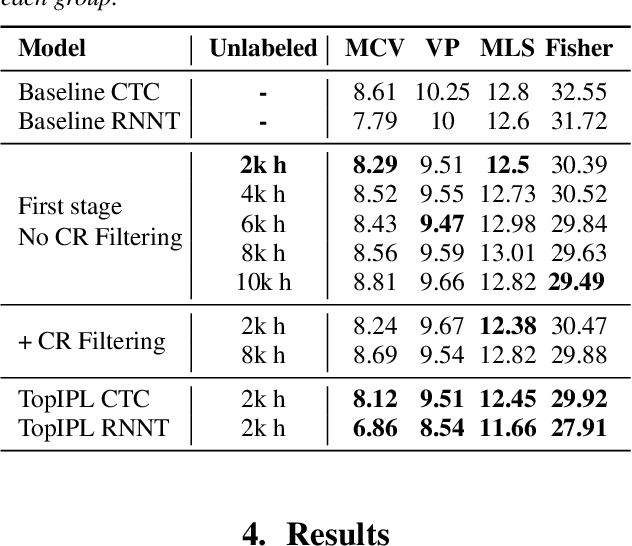
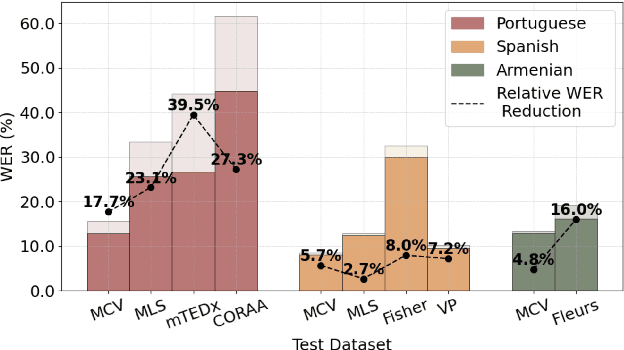
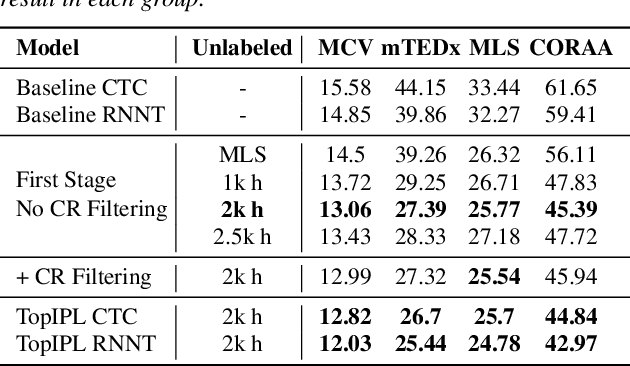
Automatic Speech Recognition has been a longstanding research area, with substantial efforts dedicated to integrating semi-supervised learning due to the scarcity of labeled datasets. However, most prior work has focused on improving learning algorithms using existing datasets, without providing a complete public framework for large-scale semi-supervised training across new datasets or languages. In this work, we introduce a fully open-source semi-supervised training framework encompassing the entire pipeline: from unlabeled data collection to pseudo-labeling and model training. Our approach enables scalable dataset creation for any language using publicly available speech data under Creative Commons licenses. We also propose a novel pseudo-labeling algorithm, TopIPL, and evaluate it in both low-resource (Portuguese, Armenian) and high-resource (Spanish) settings. Notably, TopIPL achieves relative WER improvements of 18-40% for Portuguese, 5-16% for Armenian, and 2-8% for Spanish.
NGPU-LM: GPU-Accelerated N-Gram Language Model for Context-Biasing in Greedy ASR Decoding
May 28, 2025Statistical n-gram language models are widely used for context-biasing tasks in Automatic Speech Recognition (ASR). However, existing implementations lack computational efficiency due to poor parallelization, making context-biasing less appealing for industrial use. This work rethinks data structures for statistical n-gram language models to enable fast and parallel operations for GPU-optimized inference. Our approach, named NGPU-LM, introduces customizable greedy decoding for all major ASR model types - including transducers, attention encoder-decoder models, and CTC - with less than 7% computational overhead. The proposed approach can eliminate more than 50% of the accuracy gap between greedy and beam search for out-of-domain scenarios while avoiding significant slowdown caused by beam search. The implementation of the proposed NGPU-LM is open-sourced.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
Training and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025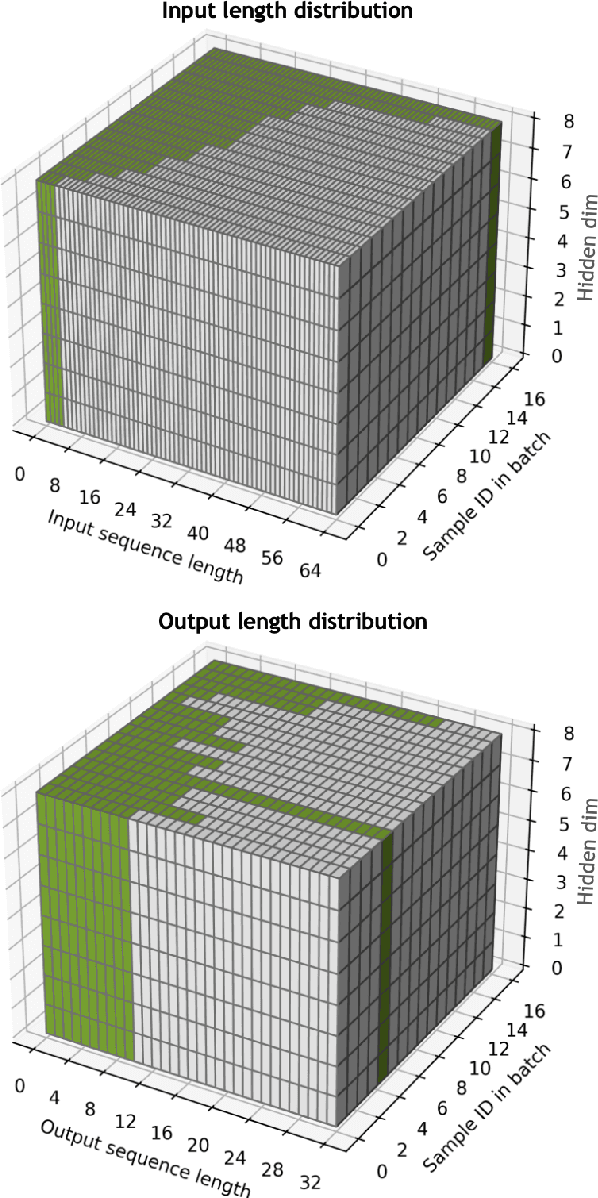

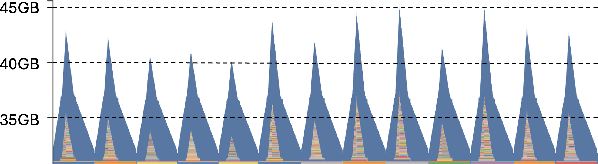
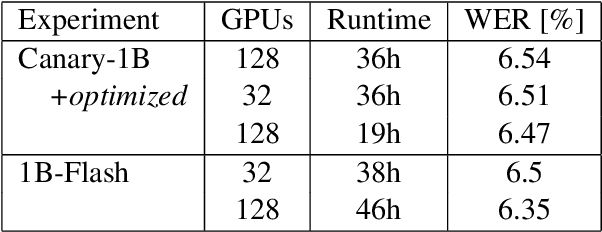
Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Jan 10, 2025This work introduces TTS-Transducer - a novel architecture for text-to-speech, leveraging the strengths of audio codec models and neural transducers. Transducers, renowned for their superior quality and robustness in speech recognition, are employed to learn monotonic alignments and allow for avoiding using explicit duration predictors. Neural audio codecs efficiently compress audio into discrete codes, revealing the possibility of applying text modeling approaches to speech generation. However, the complexity of predicting multiple tokens per frame from several codebooks, as necessitated by audio codec models with residual quantizers, poses a significant challenge. The proposed system first uses a transducer architecture to learn monotonic alignments between tokenized text and speech codec tokens for the first codebook. Next, a non-autoregressive Transformer predicts the remaining codes using the alignment extracted from transducer loss. The proposed system is trained end-to-end. We show that TTS-Transducer is a competitive and robust alternative to contemporary TTS systems.