 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexCTC: GPU-powered CTC Beam Decoding With Advanced Contextual Abilities
Aug 13, 2025
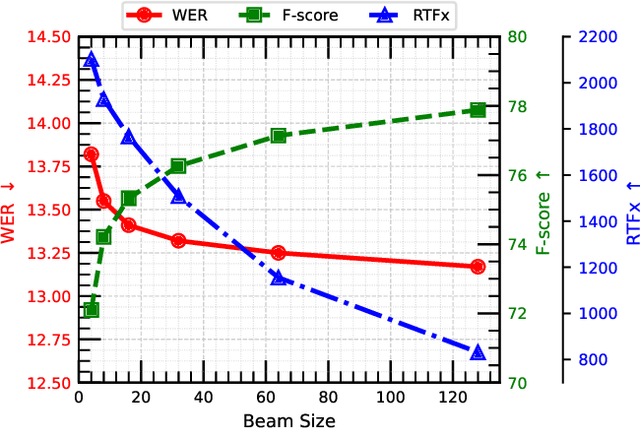


While beam search improves speech recognition quality over greedy decoding, standard implementations are slow, often sequential, and CPU-bound. To fully leverage modern hardware capabilities, we present a novel open-source FlexCTC toolkit for fully GPU-based beam decoding, designed for Connectionist Temporal Classification (CTC) models. Developed entirely in Python and PyTorch, it offers a fast, user-friendly, and extensible alternative to traditional C++, CUDA, or WFST-based decoders. The toolkit features a high-performance, fully batched GPU implementation with eliminated CPU-GPU synchronization and minimized kernel launch overhead via CUDA Graphs. It also supports advanced contextualization techniques, including GPU-powered N-gram language model fusion and phrase-level boosting. These features enable accurate and efficient decoding, making them suitable for both research and production use.
TurboBias: Universal ASR Context-Biasing powered by GPU-accelerated Phrase-Boosting Tree
Aug 12, 2025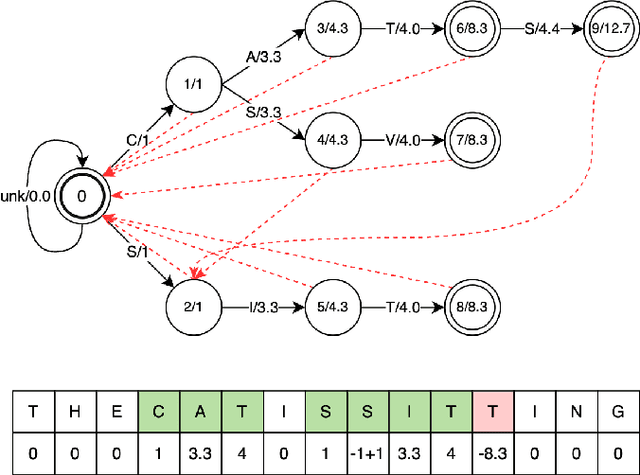
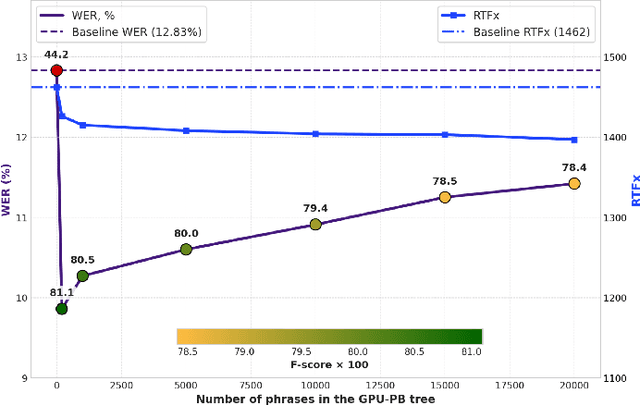
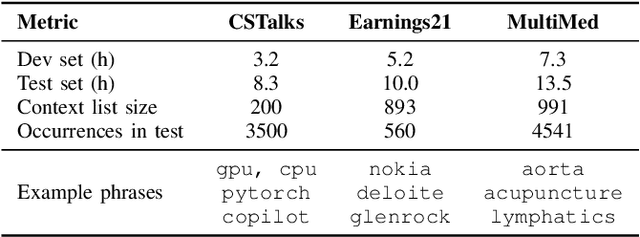
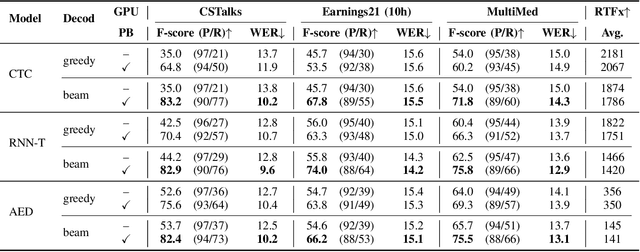
Recognizing specific key phrases is an essential task for contextualized Automatic Speech Recognition (ASR). However, most existing context-biasing approaches have limitations associated with the necessity of additional model training, significantly slow down the decoding process, or constrain the choice of the ASR system type. This paper proposes a universal ASR context-biasing framework that supports all major types: CTC, Transducers, and Attention Encoder-Decoder models. The framework is based on a GPU-accelerated word boosting tree, which enables it to be used in shallow fusion mode for greedy and beam search decoding without noticeable speed degradation, even with a vast number of key phrases (up to 20K items). The obtained results showed high efficiency of the proposed method, surpassing the considered open-source context-biasing approaches in accuracy and decoding speed. Our context-biasing framework is open-sourced as a part of the NeMo toolkit.
Unified Semi-Supervised Pipeline for Automatic Speech Recognition
Jun 09, 2025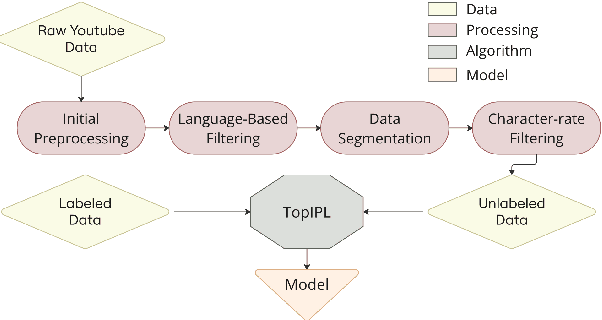
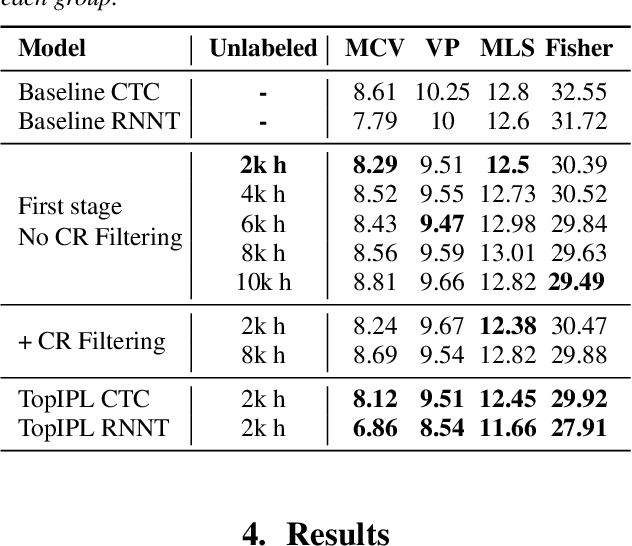
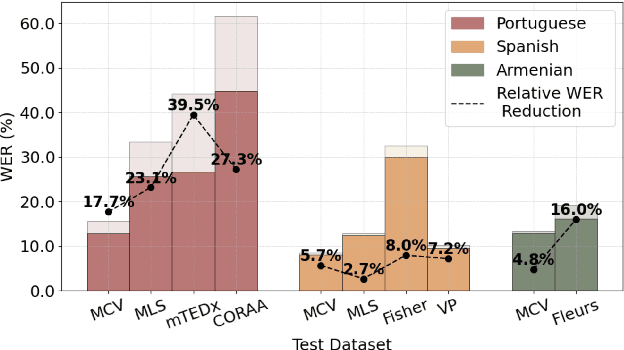
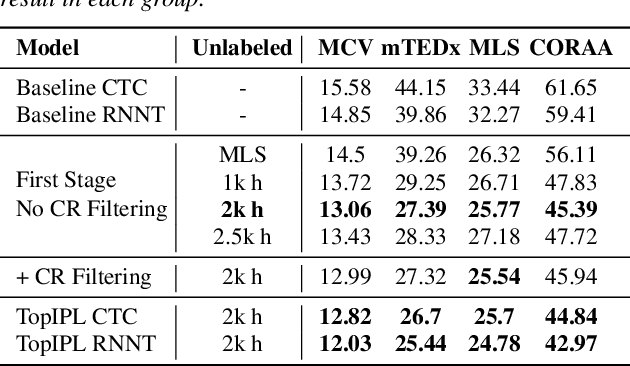
Automatic Speech Recognition has been a longstanding research area, with substantial efforts dedicated to integrating semi-supervised learning due to the scarcity of labeled datasets. However, most prior work has focused on improving learning algorithms using existing datasets, without providing a complete public framework for large-scale semi-supervised training across new datasets or languages. In this work, we introduce a fully open-source semi-supervised training framework encompassing the entire pipeline: from unlabeled data collection to pseudo-labeling and model training. Our approach enables scalable dataset creation for any language using publicly available speech data under Creative Commons licenses. We also propose a novel pseudo-labeling algorithm, TopIPL, and evaluate it in both low-resource (Portuguese, Armenian) and high-resource (Spanish) settings. Notably, TopIPL achieves relative WER improvements of 18-40% for Portuguese, 5-16% for Armenian, and 2-8% for Spanish.
NGPU-LM: GPU-Accelerated N-Gram Language Model for Context-Biasing in Greedy ASR Decoding
May 28, 2025Statistical n-gram language models are widely used for context-biasing tasks in Automatic Speech Recognition (ASR). However, existing implementations lack computational efficiency due to poor parallelization, making context-biasing less appealing for industrial use. This work rethinks data structures for statistical n-gram language models to enable fast and parallel operations for GPU-optimized inference. Our approach, named NGPU-LM, introduces customizable greedy decoding for all major ASR model types - including transducers, attention encoder-decoder models, and CTC - with less than 7% computational overhead. The proposed approach can eliminate more than 50% of the accuracy gap between greedy and beam search for out-of-domain scenarios while avoiding significant slowdown caused by beam search. The implementation of the proposed NGPU-LM is open-sourced.
Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter
Jun 11, 2024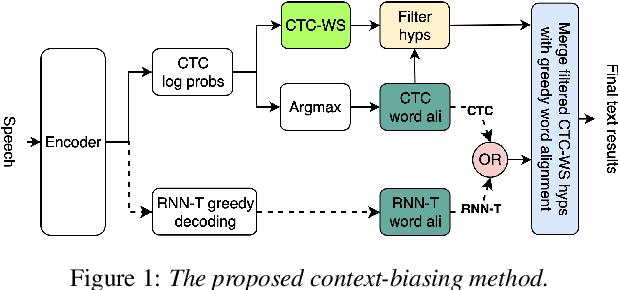
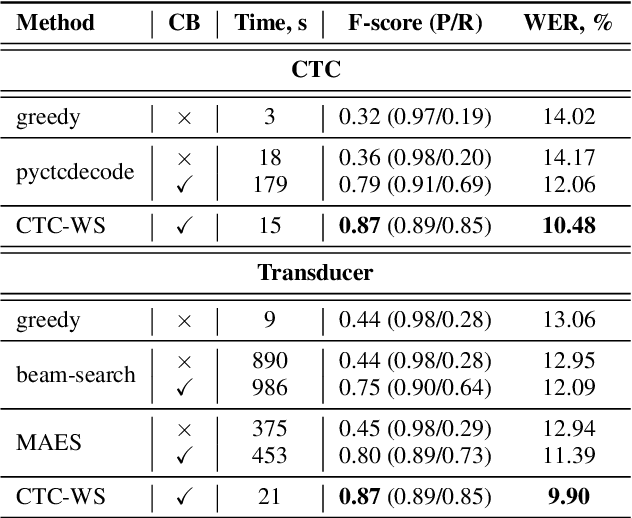
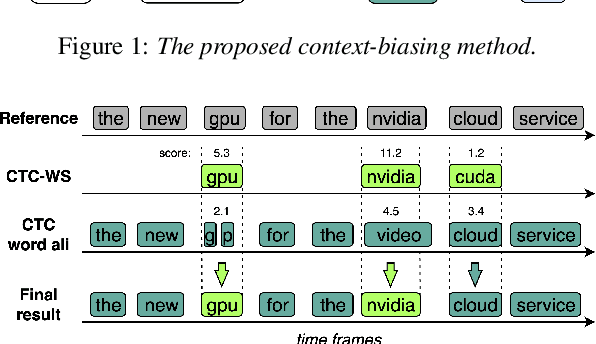
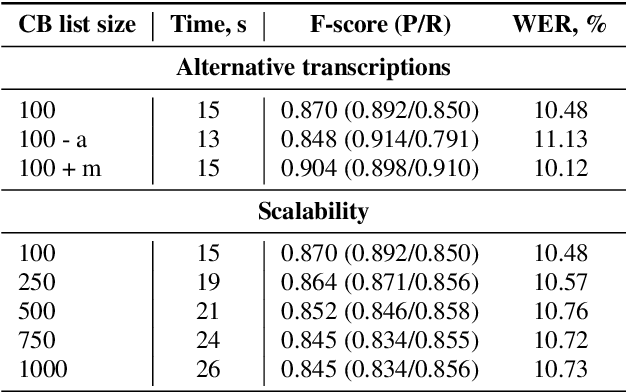
Accurate recognition of rare and new words remains a pressing problem for contextualized Automatic Speech Recognition (ASR) systems. Most context-biasing methods involve modification of the ASR model or the beam-search decoding algorithm, complicating model reuse and slowing down inference. This work presents a new approach to fast context-biasing with CTC-based Word Spotter (CTC-WS) for CTC and Transducer (RNN-T) ASR models. The proposed method matches CTC log-probabilities against a compact context graph to detect potential context-biasing candidates. The valid candidates then replace their greedy recognition counterparts in corresponding frame intervals. A Hybrid Transducer-CTC model enables the CTC-WS application for the Transducer model. The results demonstrate a significant acceleration of the context-biasing recognition with a simultaneous improvement in F-score and WER compared to baseline methods. The proposed method is publicly available in the NVIDIA NeMo toolkit.
SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
Oct 13, 2023
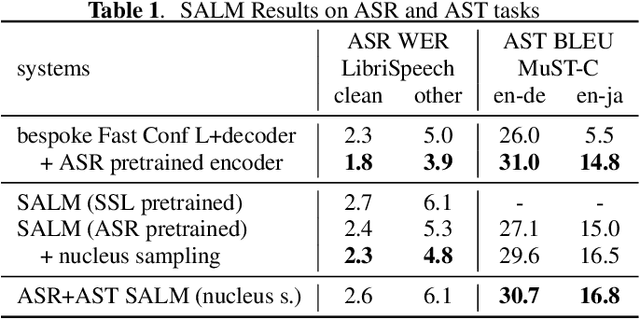


We present a novel Speech Augmented Language Model (SALM) with {\em multitask} and {\em in-context} learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST. Moreover, {\em speech supervised in-context training} is proposed to bridge the gap between LLM training and downstream speech tasks, which further boosts the in-context learning ability of speech-to-text models. Proposed model is open-sourced via NeMo toolkit.
Uconv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition
Aug 16, 2022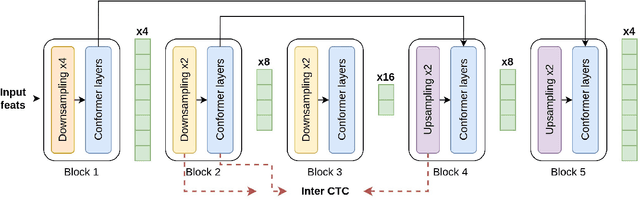
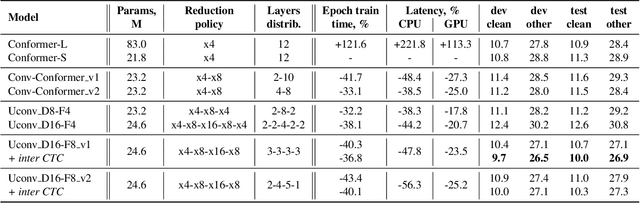
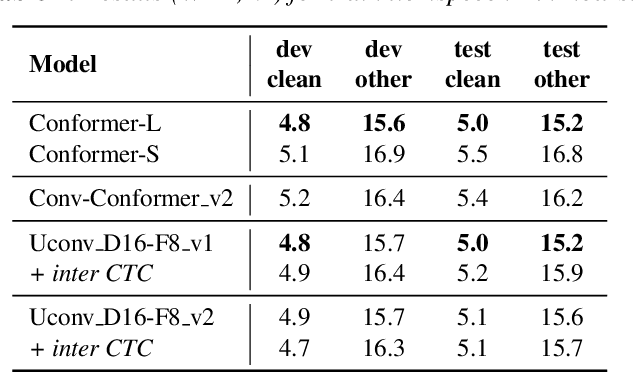
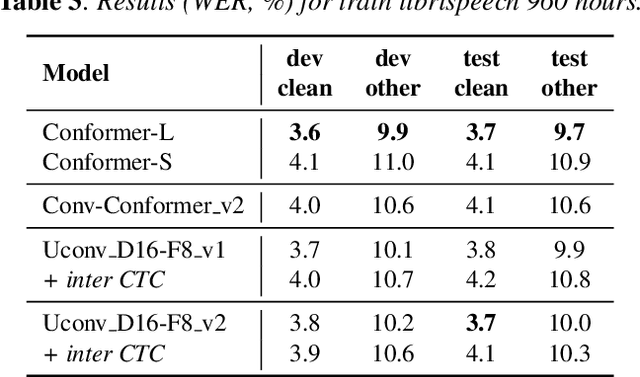
Optimization of modern ASR architectures is among the highest priority tasks since it saves many computational resources for model training and inference. The work proposes a new Uconv-Conformer architecture based on the standard Conformer model that consistently reduces the input sequence length by 16 times, which results in speeding up the work of the intermediate layers. To solve the convergence problem with such a significant reduction of the time dimension, we use upsampling blocks similar to the U-Net architecture to ensure the correct CTC loss calculation and stabilize network training. The Uconv-Conformer architecture appears to be not only faster in terms of training and inference but also shows better WER compared to the baseline Conformer. Our best Uconv-Conformer model showed 40.3% epoch training time reduction, 47.8%, and 23.5% inference acceleration on the CPU and GPU, respectively. Relative WER on Librispeech test_clean and test_other decreased by 7.3% and 9.2%.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
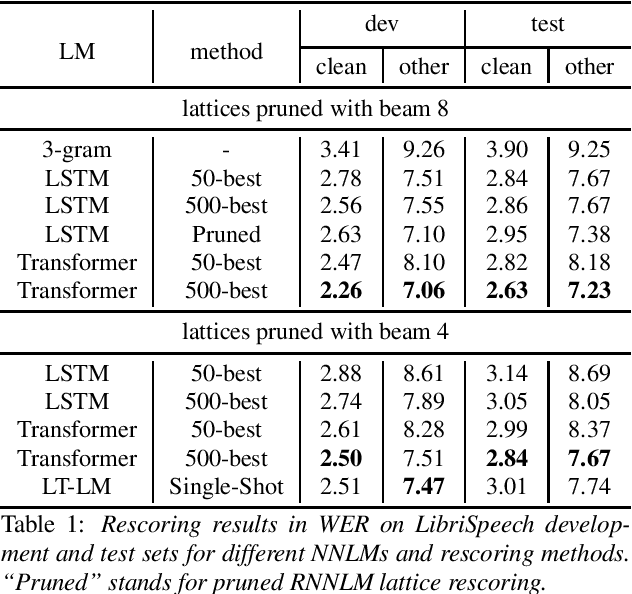
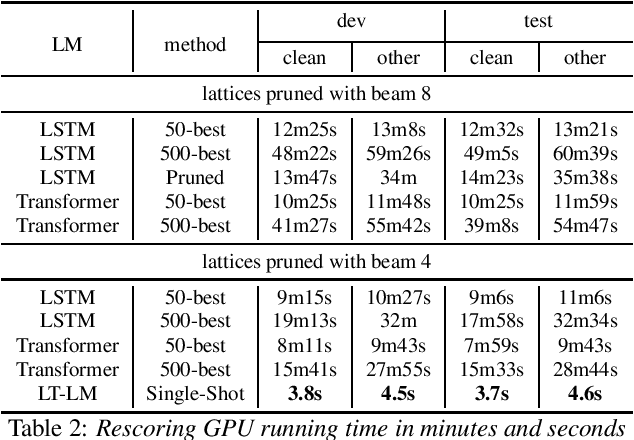
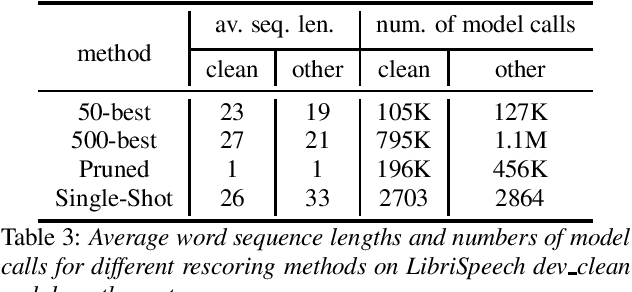
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021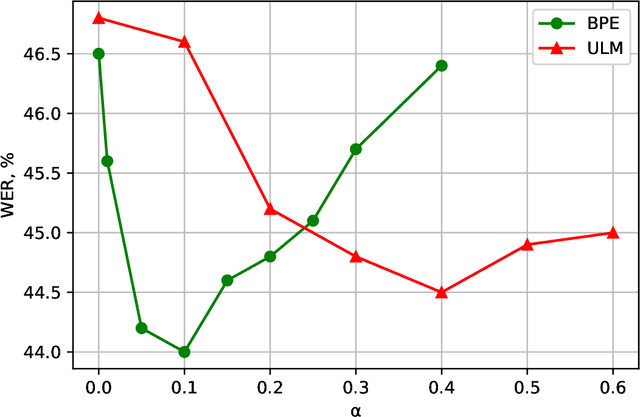
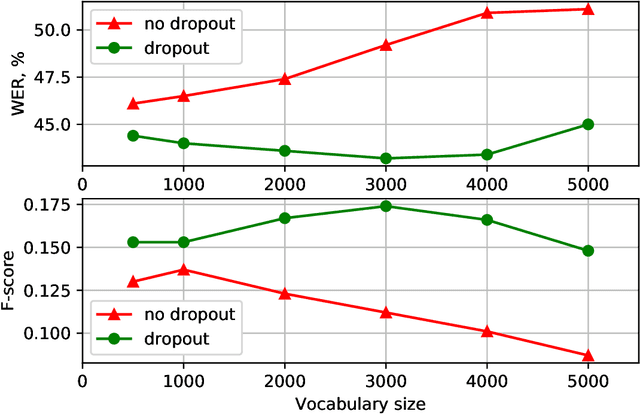
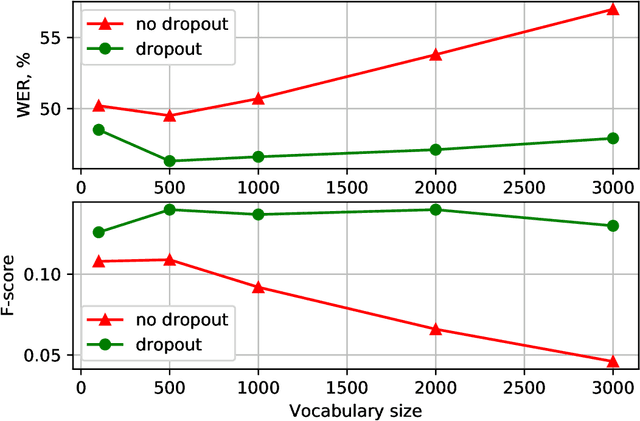
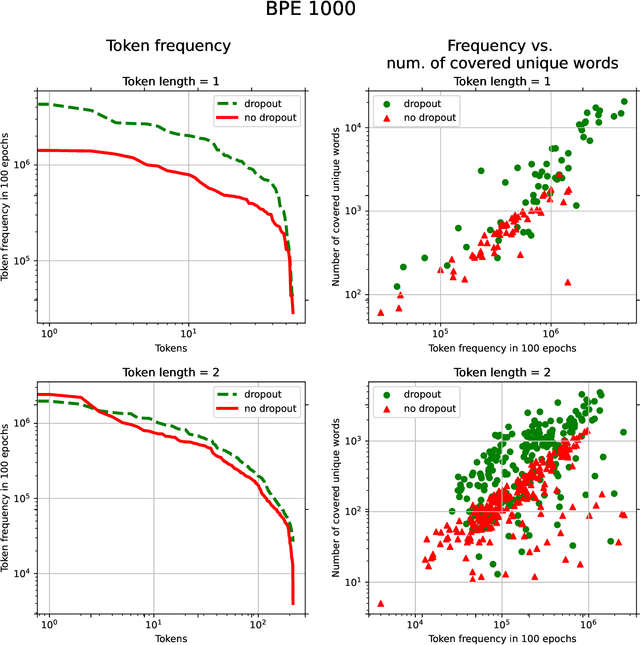
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Exploration of End-to-End ASR for OpenSTT -- Russian Open Speech-to-Text Dataset
Jun 15, 2020
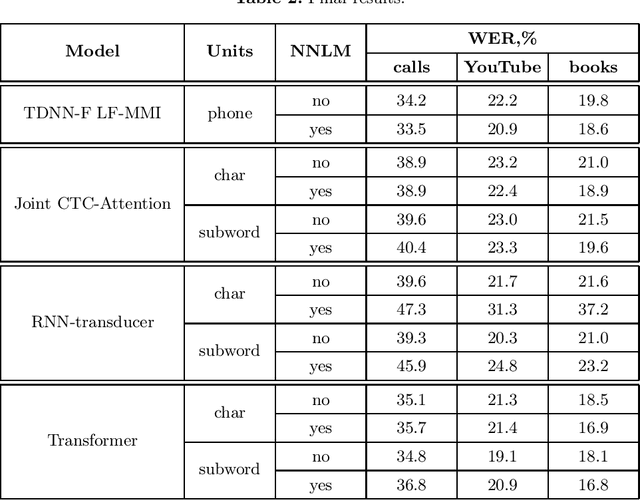
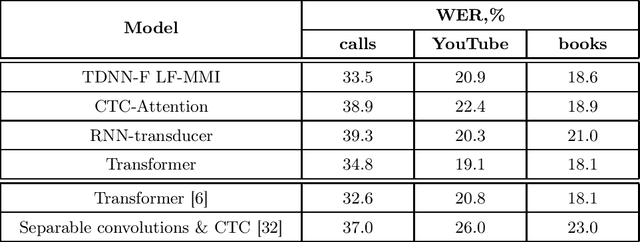
This paper presents an exploration of end-to-end automatic speech recognition systems (ASR) for the largest open-source Russian language data set -- OpenSTT. We evaluate different existing end-to-end approaches such as joint CTC/Attention, RNN-Transducer, and Transformer. All of them are compared with the strong hybrid ASR system based on LF-MMI TDNN-F acoustic model. For the three available validation sets (phone calls, YouTube, and books), our best end-to-end model achieves word error rate (WER) of 34.8%, 19.1%, and 18.1%, respectively. Under the same conditions, the hybridASR system demonstrates 33.5%, 20.9%, and 18.6% WER.