Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of End-to-End ASR for OpenSTT -- Russian Open Speech-to-Text Dataset
Paper and Code

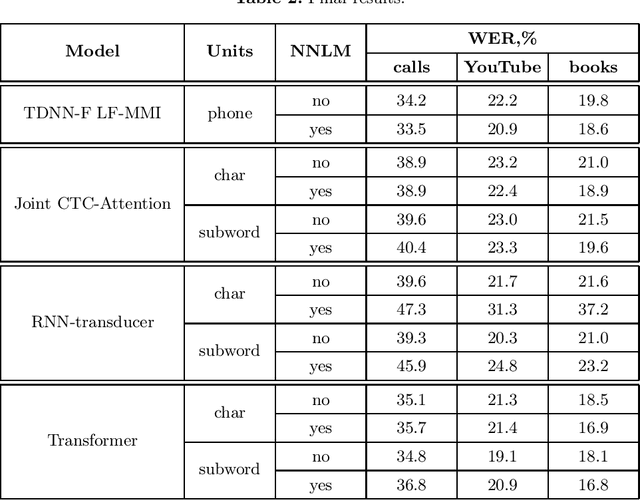
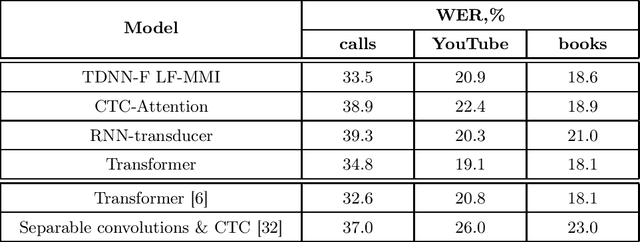
This paper presents an exploration of end-to-end automatic speech recognition systems (ASR) for the largest open-source Russian language data set -- OpenSTT. We evaluate different existing end-to-end approaches such as joint CTC/Attention, RNN-Transducer, and Transformer. All of them are compared with the strong hybrid ASR system based on LF-MMI TDNN-F acoustic model. For the three available validation sets (phone calls, YouTube, and books), our best end-to-end model achieves word error rate (WER) of 34.8%, 19.1%, and 18.1%, respectively. Under the same conditions, the hybridASR system demonstrates 33.5%, 20.9%, and 18.6% WER.
* Submitted to SPECOM 2020
View paper on