 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGPU-LM: GPU-Accelerated N-Gram Language Model for Context-Biasing in Greedy ASR Decoding
May 28, 2025Statistical n-gram language models are widely used for context-biasing tasks in Automatic Speech Recognition (ASR). However, existing implementations lack computational efficiency due to poor parallelization, making context-biasing less appealing for industrial use. This work rethinks data structures for statistical n-gram language models to enable fast and parallel operations for GPU-optimized inference. Our approach, named NGPU-LM, introduces customizable greedy decoding for all major ASR model types - including transducers, attention encoder-decoder models, and CTC - with less than 7% computational overhead. The proposed approach can eliminate more than 50% of the accuracy gap between greedy and beam search for out-of-domain scenarios while avoiding significant slowdown caused by beam search. The implementation of the proposed NGPU-LM is open-sourced.
Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter
Jun 11, 2024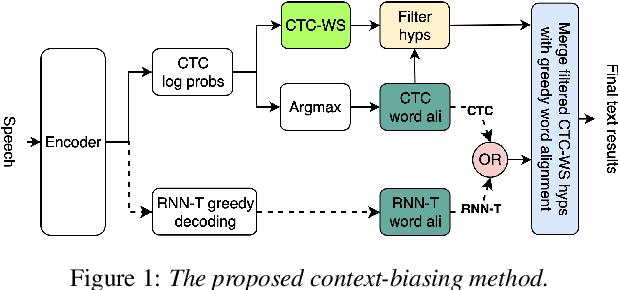
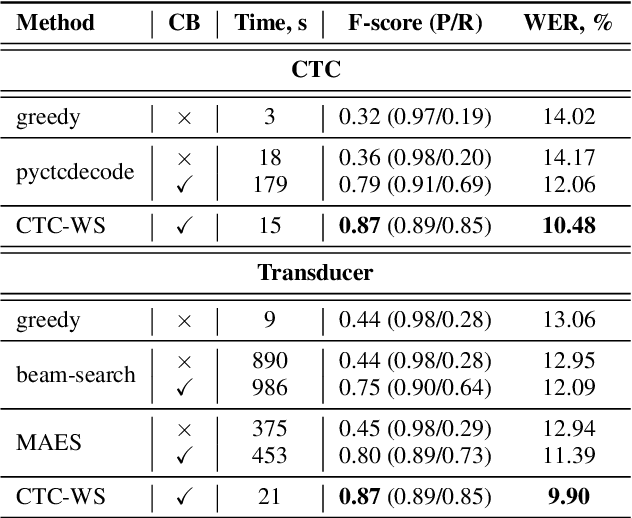
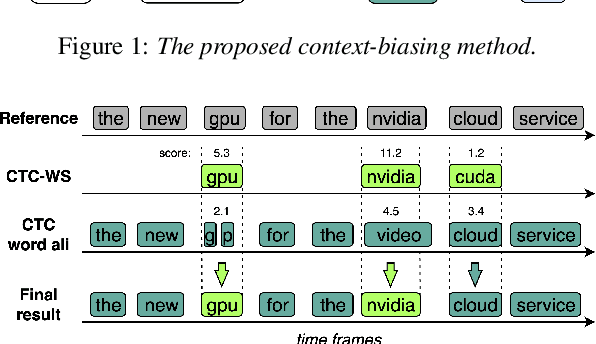
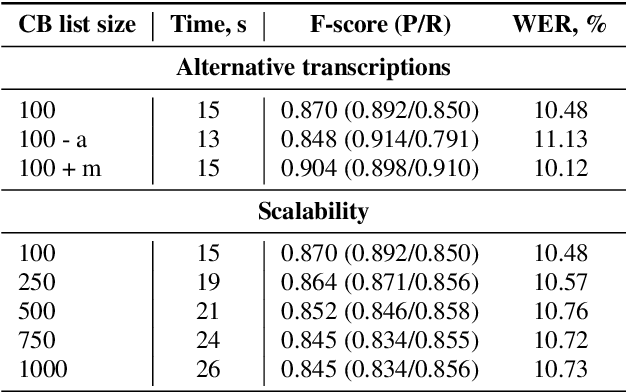
Accurate recognition of rare and new words remains a pressing problem for contextualized Automatic Speech Recognition (ASR) systems. Most context-biasing methods involve modification of the ASR model or the beam-search decoding algorithm, complicating model reuse and slowing down inference. This work presents a new approach to fast context-biasing with CTC-based Word Spotter (CTC-WS) for CTC and Transducer (RNN-T) ASR models. The proposed method matches CTC log-probabilities against a compact context graph to detect potential context-biasing candidates. The valid candidates then replace their greedy recognition counterparts in corresponding frame intervals. A Hybrid Transducer-CTC model enables the CTC-WS application for the Transducer model. The results demonstrate a significant acceleration of the context-biasing recognition with a simultaneous improvement in F-score and WER compared to baseline methods. The proposed method is publicly available in the NVIDIA NeMo toolkit.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
Confidence-based Ensembles of End-to-End Speech Recognition Models
Jun 27, 2023



The number of end-to-end speech recognition models grows every year. These models are often adapted to new domains or languages resulting in a proliferation of expert systems that achieve great results on target data, while generally showing inferior performance outside of their domain of expertise. We explore combination of such experts via confidence-based ensembles: ensembles of models where only the output of the most-confident model is used. We assume that models' target data is not available except for a small validation set. We demonstrate effectiveness of our approach with two applications. First, we show that a confidence-based ensemble of 5 monolingual models outperforms a system where model selection is performed via a dedicated language identification block. Second, we demonstrate that it is possible to combine base and adapted models to achieve strong results on both original and target data. We validate all our results on multiple datasets and model architectures.
Powerful and Extensible WFST Framework for RNN-Transducer Losses
Mar 18, 2023This paper presents a framework based on Weighted Finite-State Transducers (WFST) to simplify the development of modifications for RNN-Transducer (RNN-T) loss. Existing implementations of RNN-T use CUDA-related code, which is hard to extend and debug. WFSTs are easy to construct and extend, and allow debugging through visualization. We introduce two WFST-powered RNN-T implementations: (1) "Compose-Transducer", based on a composition of the WFST graphs from acoustic and textual schema -- computationally competitive and easy to modify; (2) "Grid-Transducer", which constructs the lattice directly for further computations -- most compact, and computationally efficient. We illustrate the ease of extensibility through introduction of a new W-Transducer loss -- the adaptation of the Connectionist Temporal Classification with Wild Cards. W-Transducer (W-RNNT) consistently outperforms the standard RNN-T in a weakly-supervised data setup with missing parts of transcriptions at the beginning and end of utterances. All RNN-T losses are implemented with the k2 framework and are available in the NeMo toolkit.
Fast Entropy-Based Methods of Word-Level Confidence Estimation for End-To-End Automatic Speech Recognition
Dec 16, 2022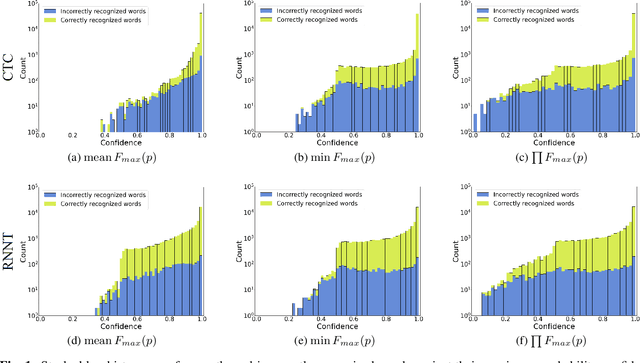
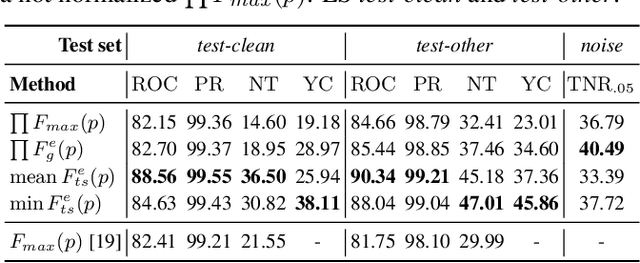
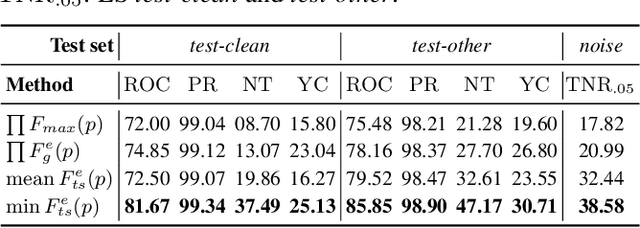
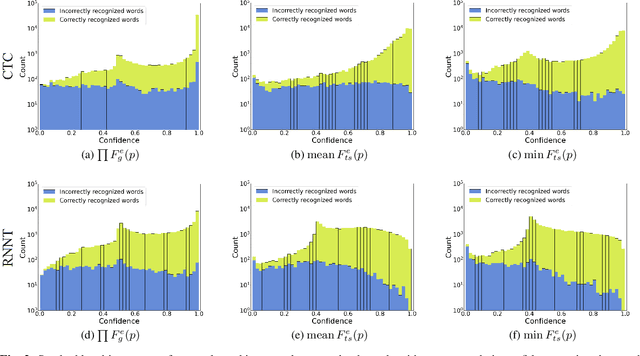
This paper presents a class of new fast non-trainable entropy-based confidence estimation methods for automatic speech recognition. We show how per-frame entropy values can be normalized and aggregated to obtain a confidence measure per unit and per word for Connectionist Temporal Classification (CTC) and Recurrent Neural Network Transducer (RNN-T) models. Proposed methods have similar computational complexity to the traditional method based on the maximum per-frame probability, but they are more adjustable, have a wider effective threshold range, and better push apart the confidence distributions of correct and incorrect words. We evaluate the proposed confidence measures on LibriSpeech test sets, and show that they are up to 2 and 4 times better than confidence estimation based on the maximum per-frame probability at detecting incorrect words for Conformer-CTC and Conformer-RNN-T models, respectively.
CTC Variations Through New WFST Topologies
Oct 06, 2021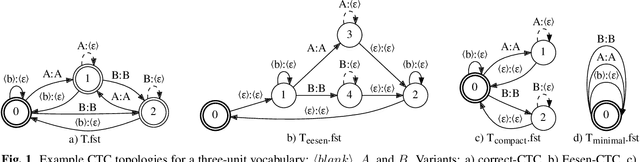
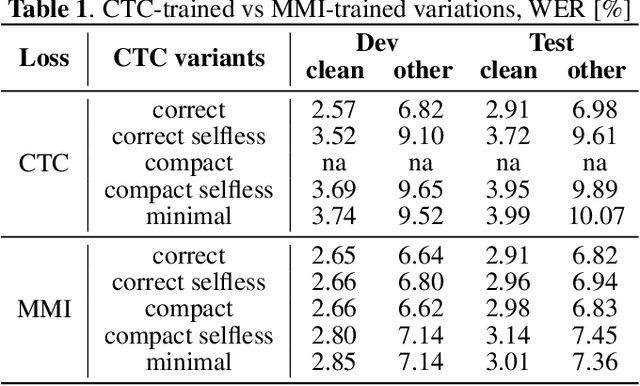
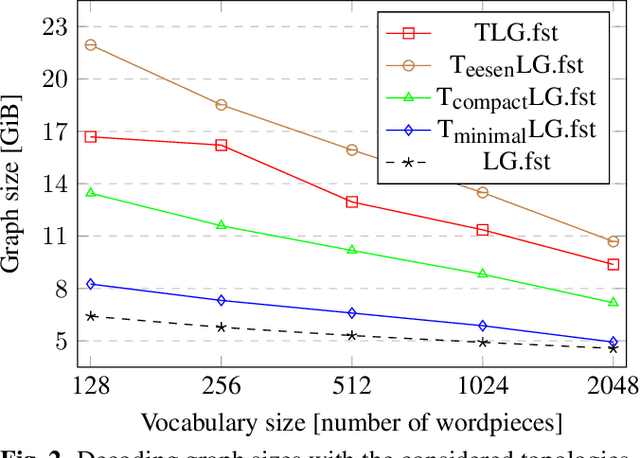
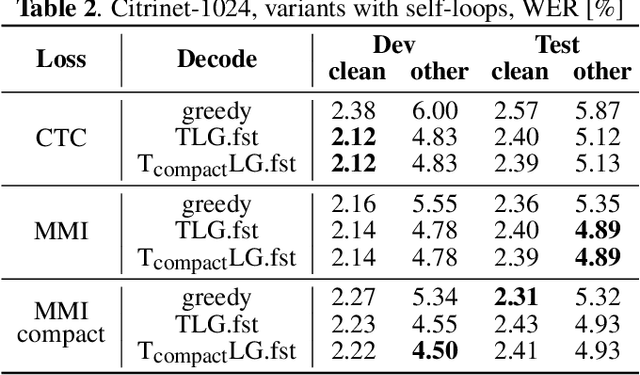
This paper presents novel Weighted Finite-State Transducer (WFST) topologies to implement Connectionist Temporal Classification (CTC)-like algorithms for automatic speech recognition. Three new CTC variants are proposed: (1) the "compact-CTC", in which direct transitions between units are replaced with <epsilon> back-off transitions; (2) the "minimal-CTC", that only adds <blank> self-loops when used in WFST-composition; and (3) "selfless-CTC", that disallows self-loop for non-blank units. The new CTC variants have several benefits, such as reducing decoding graph size and GPU memory required for training while keeping model accuracy.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
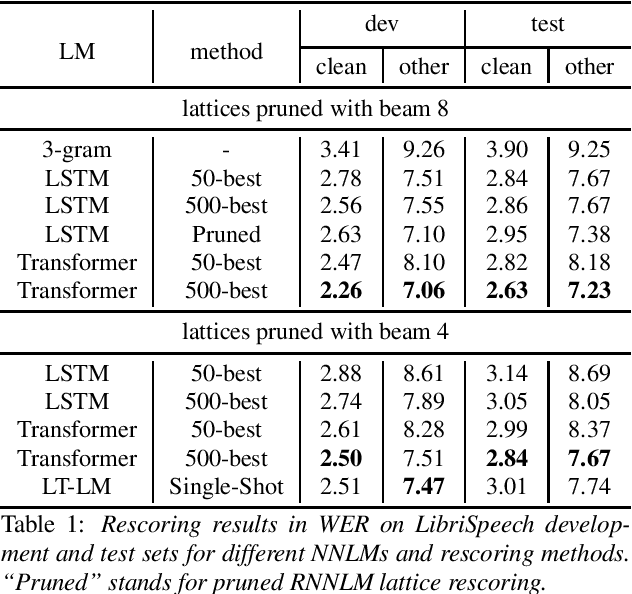
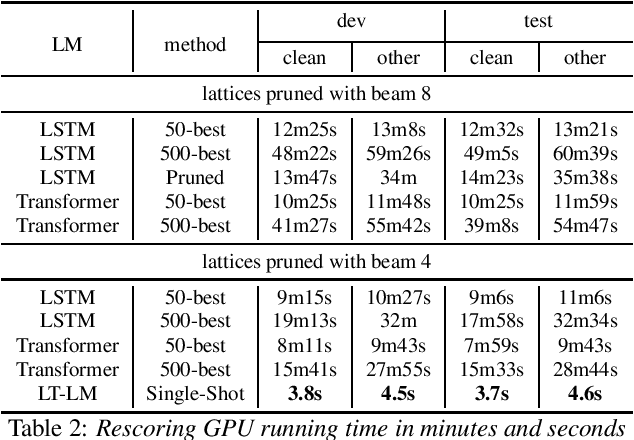
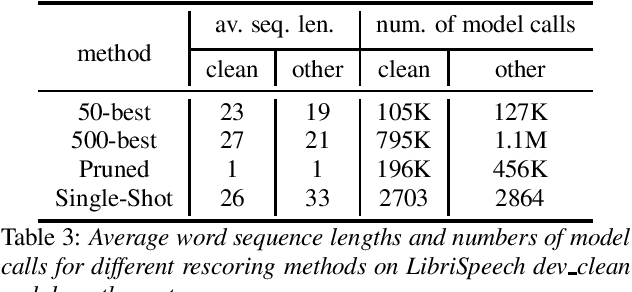
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021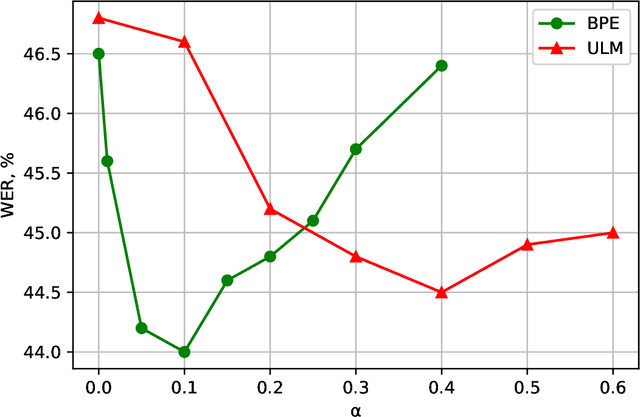
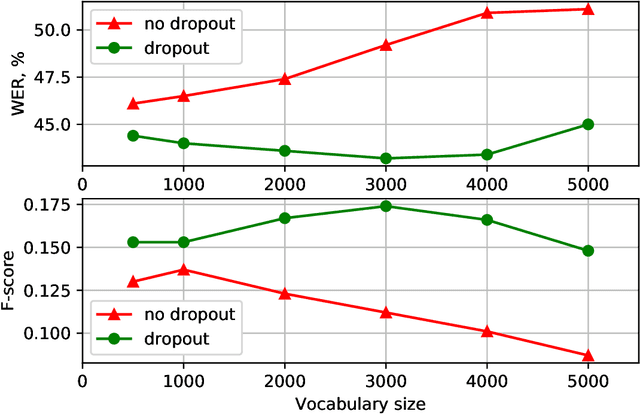
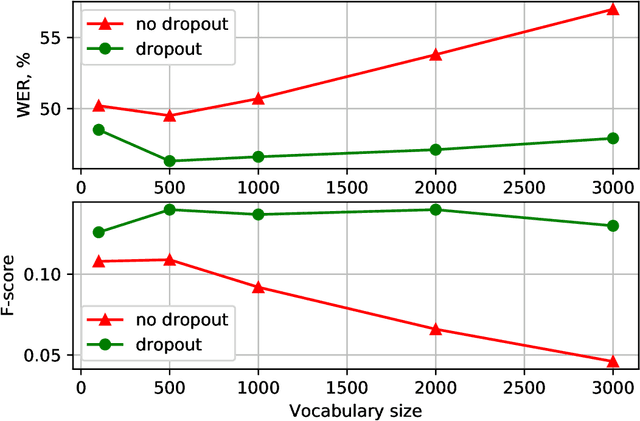
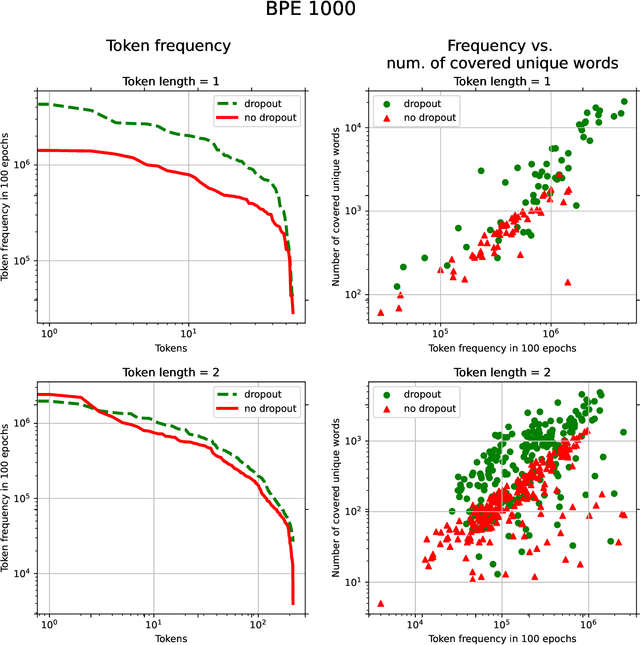
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Exploration of End-to-End ASR for OpenSTT -- Russian Open Speech-to-Text Dataset
Jun 15, 2020
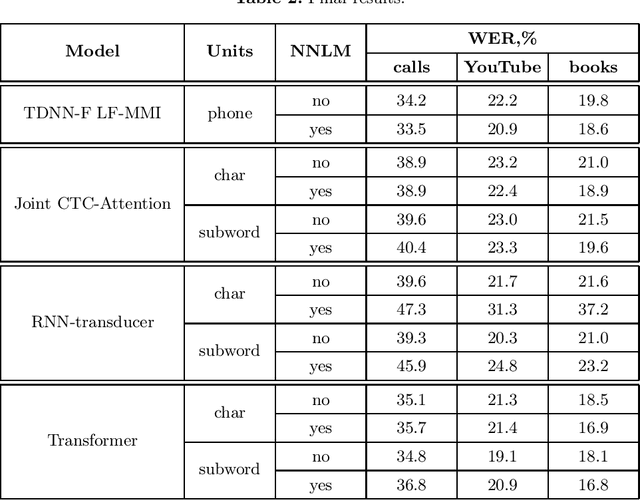
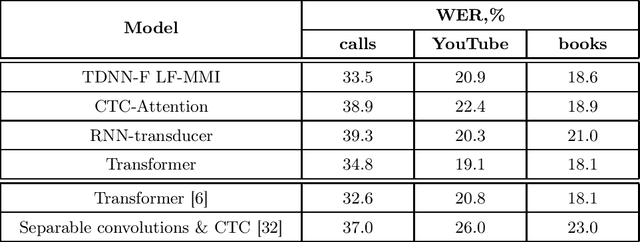
This paper presents an exploration of end-to-end automatic speech recognition systems (ASR) for the largest open-source Russian language data set -- OpenSTT. We evaluate different existing end-to-end approaches such as joint CTC/Attention, RNN-Transducer, and Transformer. All of them are compared with the strong hybrid ASR system based on LF-MMI TDNN-F acoustic model. For the three available validation sets (phone calls, YouTube, and books), our best end-to-end model achieves word error rate (WER) of 34.8%, 19.1%, and 18.1%, respectively. Under the same conditions, the hybridASR system demonstrates 33.5%, 20.9%, and 18.6% WER.