Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC Variations Through New WFST Topologies
Paper and Code
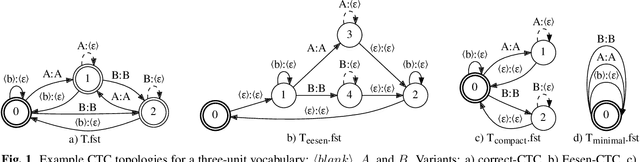
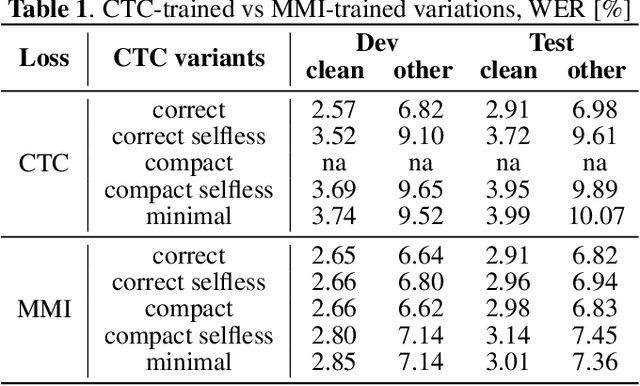
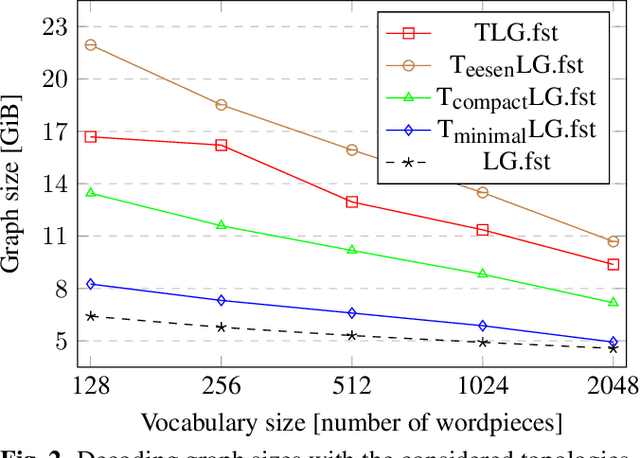
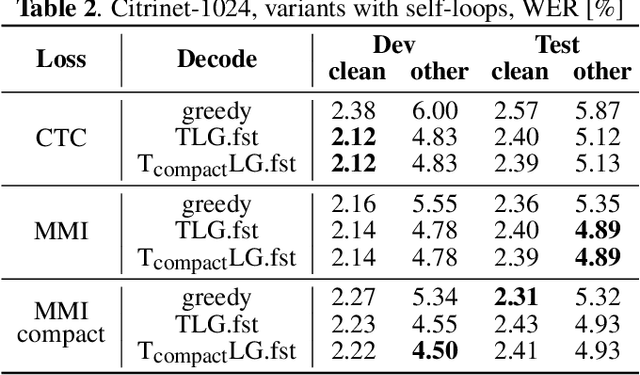
This paper presents novel Weighted Finite-State Transducer (WFST) topologies to implement Connectionist Temporal Classification (CTC)-like algorithms for automatic speech recognition. Three new CTC variants are proposed: (1) the "compact-CTC", in which direct transitions between units are replaced with <epsilon> back-off transitions; (2) the "minimal-CTC", that only adds <blank> self-loops when used in WFST-composition; and (3) "selfless-CTC", that disallows self-loop for non-blank units. The new CTC variants have several benefits, such as reducing decoding graph size and GPU memory required for training while keeping model accuracy.
* Submitted to ICASSP 2022, 5 pages, 2 figures, 7 tables
View paper on