 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexCTC: GPU-powered CTC Beam Decoding With Advanced Contextual Abilities
Aug 13, 2025
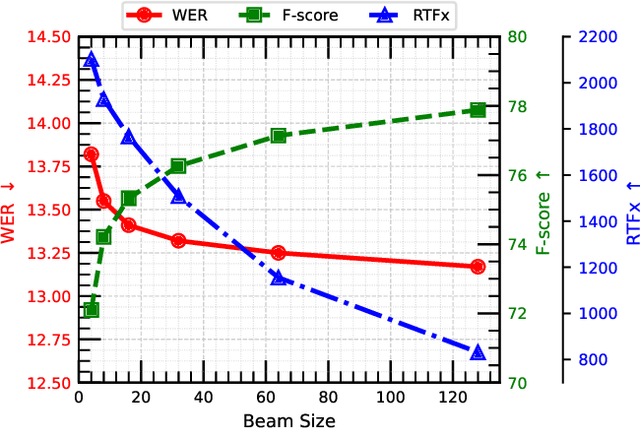


While beam search improves speech recognition quality over greedy decoding, standard implementations are slow, often sequential, and CPU-bound. To fully leverage modern hardware capabilities, we present a novel open-source FlexCTC toolkit for fully GPU-based beam decoding, designed for Connectionist Temporal Classification (CTC) models. Developed entirely in Python and PyTorch, it offers a fast, user-friendly, and extensible alternative to traditional C++, CUDA, or WFST-based decoders. The toolkit features a high-performance, fully batched GPU implementation with eliminated CPU-GPU synchronization and minimized kernel launch overhead via CUDA Graphs. It also supports advanced contextualization techniques, including GPU-powered N-gram language model fusion and phrase-level boosting. These features enable accurate and efficient decoding, making them suitable for both research and production use.
Unified Semi-Supervised Pipeline for Automatic Speech Recognition
Jun 09, 2025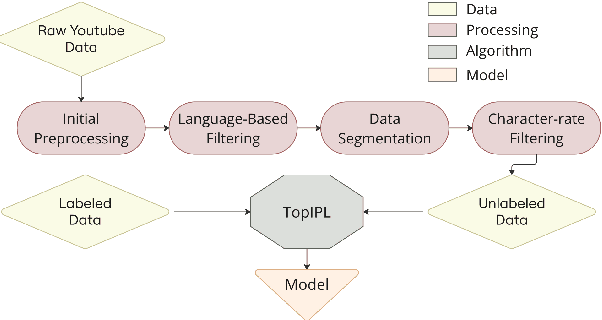
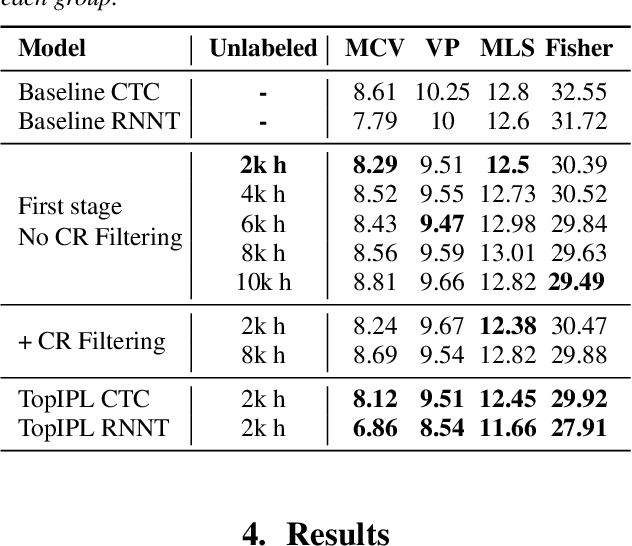
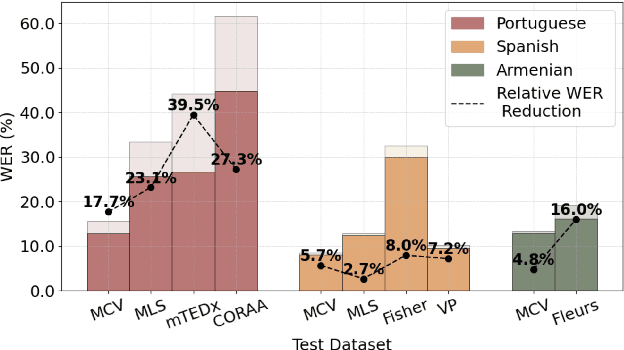
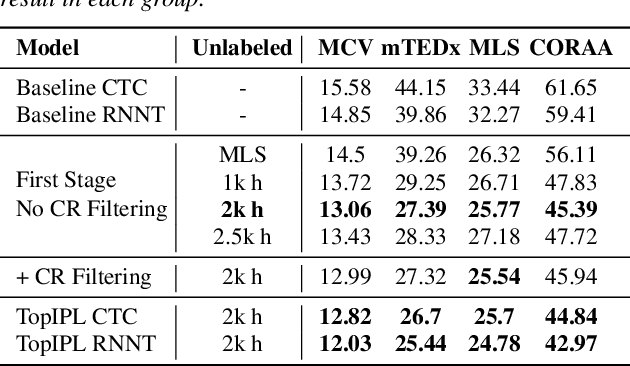
Automatic Speech Recognition has been a longstanding research area, with substantial efforts dedicated to integrating semi-supervised learning due to the scarcity of labeled datasets. However, most prior work has focused on improving learning algorithms using existing datasets, without providing a complete public framework for large-scale semi-supervised training across new datasets or languages. In this work, we introduce a fully open-source semi-supervised training framework encompassing the entire pipeline: from unlabeled data collection to pseudo-labeling and model training. Our approach enables scalable dataset creation for any language using publicly available speech data under Creative Commons licenses. We also propose a novel pseudo-labeling algorithm, TopIPL, and evaluate it in both low-resource (Portuguese, Armenian) and high-resource (Spanish) settings. Notably, TopIPL achieves relative WER improvements of 18-40% for Portuguese, 5-16% for Armenian, and 2-8% for Spanish.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Jun 03, 2024In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is "portable" to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
LibriSpeech-PC: Benchmark for Evaluation of Punctuation and Capitalization Capabilities of end-to-end ASR Models
Oct 04, 2023



Traditional automatic speech recognition (ASR) models output lower-cased words without punctuation marks, which reduces readability and necessitates a subsequent text processing model to convert ASR transcripts into a proper format. Simultaneously, the development of end-to-end ASR models capable of predicting punctuation and capitalization presents several challenges, primarily due to limited data availability and shortcomings in the existing evaluation methods, such as inadequate assessment of punctuation prediction. In this paper, we introduce a LibriSpeech-PC benchmark designed to assess the punctuation and capitalization prediction capabilities of end-to-end ASR models. The benchmark includes a LibriSpeech-PC dataset with restored punctuation and capitalization, a novel evaluation metric called Punctuation Error Rate (PER) that focuses on punctuation marks, and initial baseline models. All code, data, and models are publicly available.
Large Raw Emotional Dataset with Aggregation Mechanism
Dec 23, 2022



We present a new data set for speech emotion recognition (SER) tasks called Dusha. The corpus contains approximately 350 hours of data, more than 300 000 audio recordings with Russian speech and their transcripts. Therefore it is the biggest open bi-modal data collection for SER task nowadays. It is annotated using a crowd-sourcing platform and includes two subsets: acted and real-life. Acted subset has a more balanced class distribution than the unbalanced real-life part consisting of audio podcasts. So the first one is suitable for model pre-training, and the second is elaborated for fine-tuning purposes, model approbation, and validation. This paper describes pre-processing routine, annotation, and experiment with a baseline model to demonstrate some actual metrics which could be obtained with the Dusha data set.
Golos: Russian Dataset for Speech Research
Jun 18, 2021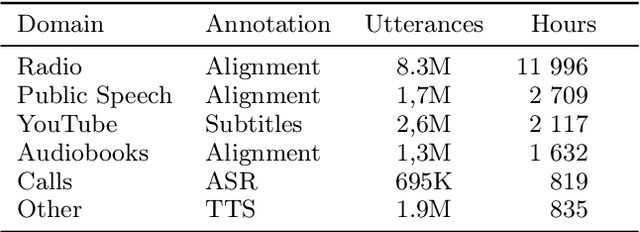



This paper introduces a novel Russian speech dataset called Golos, a large corpus suitable for speech research. The dataset mainly consists of recorded audio files manually annotated on the crowd-sourcing platform. The total duration of the audio is about 1240 hours. We have made the corpus freely available to download, along with the acoustic model with CTC loss prepared on this corpus. Additionally, transfer learning was applied to improve the performance of the acoustic model. In order to evaluate the quality of the dataset with the beam-search algorithm, we have built a 3-gram language model on the open Common Crawl dataset. The total word error rate (WER) metrics turned out to be about 3.3% and 11.5%.