 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolos: Russian Dataset for Speech Research
Jun 18, 2021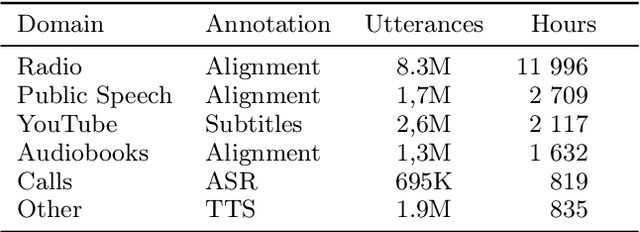



This paper introduces a novel Russian speech dataset called Golos, a large corpus suitable for speech research. The dataset mainly consists of recorded audio files manually annotated on the crowd-sourcing platform. The total duration of the audio is about 1240 hours. We have made the corpus freely available to download, along with the acoustic model with CTC loss prepared on this corpus. Additionally, transfer learning was applied to improve the performance of the acoustic model. In order to evaluate the quality of the dataset with the beam-search algorithm, we have built a 3-gram language model on the open Common Crawl dataset. The total word error rate (WER) metrics turned out to be about 3.3% and 11.5%.
Tumor Delineation For Brain Radiosurgery by a ConvNet and Non-Uniform Patch Generation
Aug 01, 2018

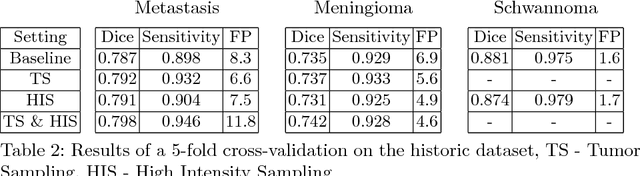

Deep learning methods are actively used for brain lesion segmentation. One of the most popular models is DeepMedic, which was developed for segmentation of relatively large lesions like glioma and ischemic stroke. In our work, we consider segmentation of brain tumors appropriate to stereotactic radiosurgery which limits typical lesion sizes. These differences in target volumes lead to a large number of false negatives (especially for small lesions) as well as to an increased number of false positives for DeepMedic. We propose a new patch-sampling procedure to increase network performance for small lesions. We used a 6-year dataset from a stereotactic radiosurgery center. To evaluate our approach, we conducted experiments with the three most frequent brain tumors: metastasis, meningioma, schwannoma. In addition to cross-validation, we estimated quality on a hold-out test set which was collected several years later than the train one. The experimental results show solid improvements in both cases.