 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccLock: Unlocking Identity with Heartbeat Using In-Ear Accelerometers
May 12, 2026The widespread use of earphones has enabled various sensing applications, including activity recognition, health monitoring, and context-aware computing. Among these, earphone-based user authentication has become a key technique by leveraging unique biometric features. However, existing earphone-based authentication systems face key limitations: they either require explicit user interaction or active speaker output, or suffer from poor accessibility and vulnerability to environmental noise, which hinders large-scale deployment. In this paper, we propose a passive authentication system, called AccLock, which leverages distinctive features extracted from in-ear BCG signals to enable secure and unobtrusive user verification. Our system offers several advantages over previous systems, including zero-involvement for both the device and the user, ubiquitous, and resilient to environmental noise. To realize this, we first design a two-stage denoising scheme to suppress both inherent and sporadic interference. To extract user-specific features, we then propose a disentanglement-based deep learning model, HIDNet, which explicitly separates user-specific features from shared nuisance components. Lastly, we develop a scalable authentication framework based on a Siamese network that eliminates the need for per-user classifier training. We conduct extensive experiments with 33 participants, achieving an average FAR of 3.13% and FRR of 2.99%, which demonstrates the practical feasibility of AccLock.
Semantic Alignment across Ancient Egyptian Language Stages via Normalization-Aware Multitask Learning
Mar 25, 2026We study word-level semantic alignment across four historical stages of Ancient Egyptian. These stages differ in script and orthography, and parallel data are scarce. We jointly train a compact encoder-decoder model with a shared byte-level tokenizer on all four stages, combining masked language modeling (MLM), translation language modeling (TLM), sequence-to-sequence translation, and part-of-speech tagging under a task-aware loss with fixed weights and uncertainty-based scaling. To reduce surface divergence we add Latin transliteration and IPA reconstruction as auxiliary views. We integrate these views through KL-based consistency and through embedding-level fusion. We evaluate alignment quality using pairwise metrics, specifically ROC-AUC and triplet accuracy, on curated Egyptian-English and intra-Egyptian cognate datasets. Translation yields the strongest gains. IPA with KL consistency improves cross-branch alignment, while early fusion demonstrates limited efficacy. Although the overall alignment remains limited, the findings provide a reproducible baseline and practical guidance for modeling historical languages under real constraints. They also show how normalization and task design shape what counts as alignment in typologically distant settings.
Beyond Motion Imitation: Is Human Motion Data Alone Sufficient to Explain Gait Control and Biomechanics?
Mar 12, 2026With the growing interest in motion imitation learning (IL) for human biomechanics and wearable robotics, this study investigates how additional foot-ground interaction measures, used as reward terms, affect human gait kinematics and kinetics estimation within a reinforcement learning-based IL framework. Results indicate that accurate reproduction of forward kinematics alone does not ensure biomechanically plausible joint kinetics. Adding foot-ground contacts and contact forces to the IL reward terms enables the prediction of joint moments in forward walking simulation, which are significantly closer to those computed by inverse dynamics. This finding highlights a fundamental limitation of motion-only IL approaches, which may prioritize kinematics matching over physical consistency. Incorporating kinetic constraints, particularly ground reaction force and center of pressure information, significantly enhances the realism of internal and external kinetics. These findings suggest that, when imitation learning is applied to human-related research domains such as biomechanics and wearable robot co-design, kinetics-based reward shaping is necessary to achieve physically consistent gait representations.
HybridINR-PCGC: Hybrid Lossless Point Cloud Geometry Compression Bridging Pretrained Model and Implicit Neural Representation
Feb 25, 2026Learning-based point cloud compression presents superior performance to handcrafted codecs. However, pretrained-based methods, which are based on end-to-end training and expected to generalize to all the potential samples, suffer from training data dependency. Implicit neural representation (INR) based methods are distribution-agnostic and more robust, but they require time-consuming online training and suffer from the bitstream overhead from the overfitted model. To address these limitations, we propose HybridINR-PCGC, a novel hybrid framework that bridges the pretrained model and INR. Our framework retains distribution-agnostic properties while leveraging a pretrained network to accelerate convergence and reduce model overhead, which consists of two parts: the Pretrained Prior Network (PPN) and the Distribution Agnostic Refiner (DAR). We leverage the PPN, designed for fast inference and stable performance, to generate a robust prior for accelerating the DAR's convergence. The DAR is decomposed into a base layer and an enhancement layer, and only the enhancement layer needed to be packed into the bitstream. Finally, we propose a supervised model compression module to further supervise and minimize the bitrate of the enhancement layer parameters. Based on experiment results, HybridINR-PCGC achieves a significantly improved compression rate and encoding efficiency. Specifically, our method achieves a Bpp reduction of approximately 20.43% compared to G-PCC on 8iVFB. In the challenging out-of-distribution scenario Cat1B, our method achieves a Bpp reduction of approximately 57.85% compared to UniPCGC. And our method exhibits a superior time-rate trade-off, achieving an average Bpp reduction of 15.193% relative to the LINR-PCGC on 8iVFB.
TVMC: Time-Varying Mesh Compression via Multi-Stage Anchor Mesh Generation
Oct 26, 2025Time-varying meshes, characterized by dynamic connectivity and varying vertex counts, hold significant promise for applications such as augmented reality. However, their practical utilization remains challenging due to the substantial data volume required for high-fidelity representation. While various compression methods attempt to leverage temporal redundancy between consecutive mesh frames, most struggle with topological inconsistency and motion-induced artifacts. To address these issues, we propose Time-Varying Mesh Compression (TVMC), a novel framework built on multi-stage coarse-to-fine anchor mesh generation for inter-frame prediction. Specifically, the anchor mesh is progressively constructed in three stages: initial, coarse, and fine. The initial anchor mesh is obtained through fast topology alignment to exploit temporal coherence. A Kalman filter-based motion estimation module then generates a coarse anchor mesh by accurately compensating inter-frame motions. Subsequently, a Quadric Error Metric-based refinement step optimizes vertex positions to form a fine anchor mesh with improved geometric fidelity. Based on the refined anchor mesh, the inter-frame motions relative to the reference base mesh are encoded, while the residual displacements between the subdivided fine anchor mesh and the input mesh are adaptively quantized and compressed. This hierarchical strategy preserves consistent connectivity and high-quality surface approximation, while achieving an efficient and compact representation of dynamic geometry. Extensive experiments on standard MPEG dynamic mesh sequences demonstrate that TVMC achieves state-of-the-art compression performance. Compared to the latest V-DMC standard, it delivers a significant BD-rate gain of 10.2% ~ 16.9%, while preserving high reconstruction quality. The code is available at https://github.com/H-Huang774/TVMC.
Optimal Real-time Communication in 6G Ultra-Massive V2X Mobile Networks
Oct 08, 2025This paper introduces a novel cooperative vehicular communication algorithm tailored for future 6G ultra-massive vehicle-to-everything (V2X) networks leveraging integrated space-air-ground communication systems. Specifically, we address the challenge of real-time information exchange among rapidly moving vehicles. We demonstrate the existence of an upper bound on channel capacity given a fixed number of relays, and propose a low-complexity relay selection heuristic algorithm. Simulation results verify that our proposed algorithm achieves superior channel capacities compared to existing cooperative vehicular communication approaches.
Energy Detection over Composite $κ-μ$ Shadowed Fading Channels with Inverse Gaussian Distribution in Ultra mMTC Networks
Aug 29, 2025This paper investigates the characteristics of energy detection (ED) over composite $\kappa$-$\mu$ shadowed fading channels in ultra machine-type communication (mMTC) networks. We have derived the closed-form expressions of the probability density function (PDF) of signal-to-noise ratio (SNR) based on the Inverse Gaussian (\emph{IG}) distribution. By adopting novel integration and mathematical transformation techniques, we derive a truncation-based closed-form expression for the average detection probability for the first time. It can be observed from our simulations that the number of propagation paths has a more pronounced effect on average detection probability compared to average SNR, which is in contrast to earlier studies that focus on device-to-device networks. It suggests that for 6G mMTC network design, we should consider enhancing transmitter-receiver placement and antenna alignment strategies, rather than relying solely on increasing the device-to-device average SNR.
Word Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025
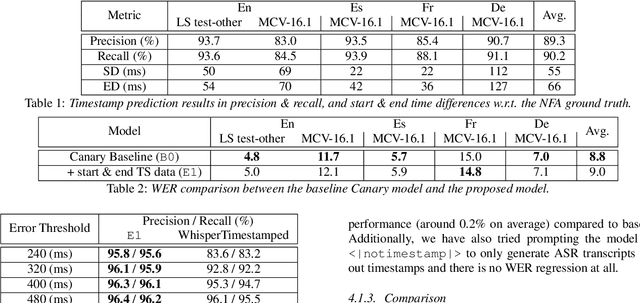
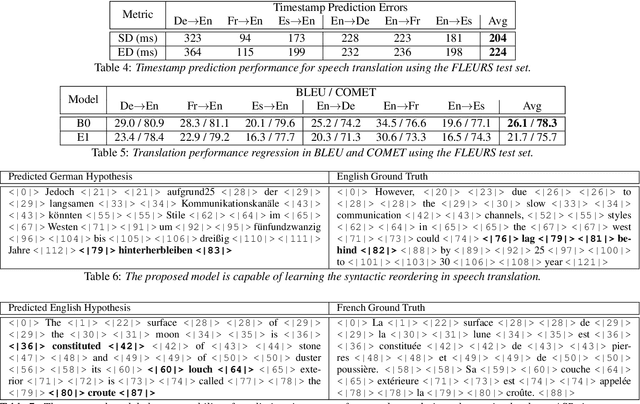
We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
IPENS:Interactive Unsupervised Framework for Rapid Plant Phenotyping Extraction via NeRF-SAM2 Fusion
May 19, 2025Advanced plant phenotyping technologies play a crucial role in targeted trait improvement and accelerating intelligent breeding. Due to the species diversity of plants, existing methods heavily rely on large-scale high-precision manually annotated data. For self-occluded objects at the grain level, unsupervised methods often prove ineffective. This study proposes IPENS, an interactive unsupervised multi-target point cloud extraction method. The method utilizes radiance field information to lift 2D masks, which are segmented by SAM2 (Segment Anything Model 2), into 3D space for target point cloud extraction. A multi-target collaborative optimization strategy is designed to effectively resolve the single-interaction multi-target segmentation challenge. Experimental validation demonstrates that IPENS achieves a grain-level segmentation accuracy (mIoU) of 63.72% on a rice dataset, with strong phenotypic estimation capabilities: grain volume prediction yields R2 = 0.7697 (RMSE = 0.0025), leaf surface area R2 = 0.84 (RMSE = 18.93), and leaf length and width predictions achieve R2 = 0.97 and 0.87 (RMSE = 1.49 and 0.21). On a wheat dataset,IPENS further improves segmentation accuracy to 89.68% (mIoU), with equally outstanding phenotypic estimation performance: spike volume prediction achieves R2 = 0.9956 (RMSE = 0.0055), leaf surface area R2 = 1.00 (RMSE = 0.67), and leaf length and width predictions reach R2 = 0.99 and 0.92 (RMSE = 0.23 and 0.15). This method provides a non-invasive, high-quality phenotyping extraction solution for rice and wheat. Without requiring annotated data, it rapidly extracts grain-level point clouds within 3 minutes through simple single-round interactions on images for multiple targets, demonstrating significant potential to accelerate intelligent breeding efficiency.