 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding-Guided Pseudo-Label Learning for Cross-Modal Building Damage Mapping
May 08, 2025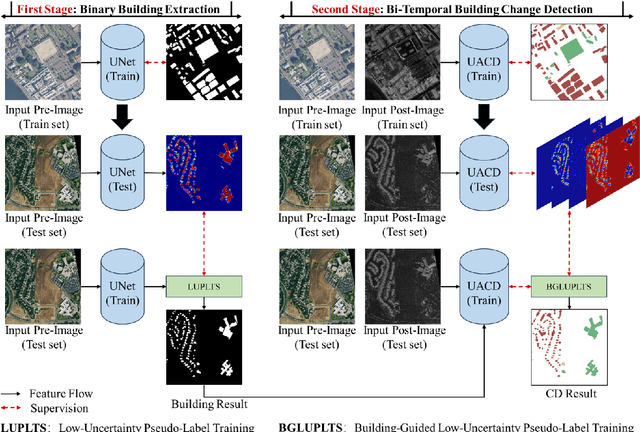
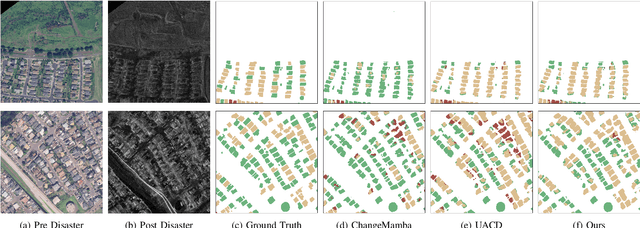

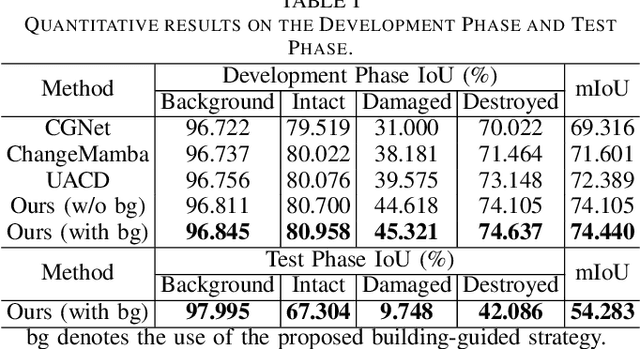
Accurate building damage assessment using bi-temporal multi-modal remote sensing images is essential for effective disaster response and recovery planning. This study proposes a novel Building-Guided Pseudo-Label Learning Framework to address the challenges of mapping building damage from pre-disaster optical and post-disaster SAR images. First, we train a series of building extraction models using pre-disaster optical images and building labels. To enhance building segmentation, we employ multi-model fusion and test-time augmentation strategies to generate pseudo-probabilities, followed by a low-uncertainty pseudo-label training method for further refinement. Next, a change detection model is trained on bi-temporal cross-modal images and damaged building labels. To improve damage classification accuracy, we introduce a building-guided low-uncertainty pseudo-label refinement strategy, which leverages building priors from the previous step to guide pseudo-label generation for damaged buildings, reducing uncertainty and enhancing reliability. Experimental results on the 2025 IEEE GRSS Data Fusion Contest dataset demonstrate the effectiveness of our approach, which achieved the highest mIoU score (54.28%) and secured first place in the competition.
Identifying every building's function in large-scale urban areas with multi-modality remote-sensing data
May 08, 2024
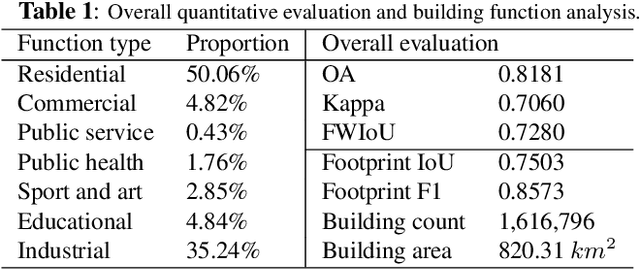

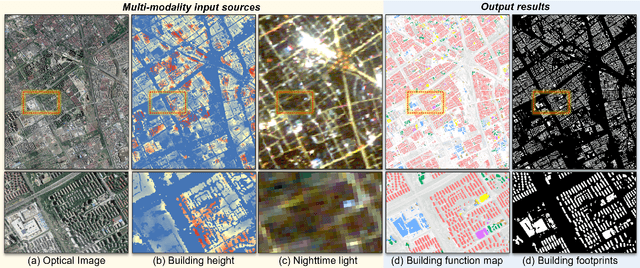
Buildings, as fundamental man-made structures in urban environments, serve as crucial indicators for understanding various city function zones. Rapid urbanization has raised an urgent need for efficiently surveying building footprints and functions. In this study, we proposed a semi-supervised framework to identify every building's function in large-scale urban areas with multi-modality remote-sensing data. In detail, optical images, building height, and nighttime-light data are collected to describe the morphological attributes of buildings. Then, the area of interest (AOI) and building masks from the volunteered geographic information (VGI) data are collected to form sparsely labeled samples. Furthermore, the multi-modality data and weak labels are utilized to train a segmentation model with a semi-supervised strategy. Finally, results are evaluated by 20,000 validation points and statistical survey reports from the government. The evaluations reveal that the produced function maps achieve an OA of 82% and Kappa of 71% among 1,616,796 buildings in Shanghai, China. This study has the potential to support large-scale urban management and sustainable urban development. All collected data and produced maps are open access at https://github.com/LiZhuoHong/BuildingMap.
C2F-SemiCD: A Coarse-to-Fine Semi-Supervised Change Detection Method Based on Consistency Regularization in High-Resolution Remote Sensing Images
Apr 22, 2024



A high-precision feature extraction model is crucial for change detection (CD). In the past, many deep learning-based supervised CD methods learned to recognize change feature patterns from a large number of labelled bi-temporal images, whereas labelling bi-temporal remote sensing images is very expensive and often time-consuming; therefore, we propose a coarse-to-fine semi-supervised CD method based on consistency regularization (C2F-SemiCD), which includes a coarse-to-fine CD network with a multiscale attention mechanism (C2FNet) and a semi-supervised update method. Among them, the C2FNet network gradually completes the extraction of change features from coarse-grained to fine-grained through multiscale feature fusion, channel attention mechanism, spatial attention mechanism, global context module, feature refine module, initial aggregation module, and final aggregation module. The semi-supervised update method uses the mean teacher method. The parameters of the student model are updated to the parameters of the teacher Model by using the exponential moving average (EMA) method. Through extensive experiments on three datasets and meticulous ablation studies, including crossover experiments across datasets, we verify the significant effectiveness and efficiency of the proposed C2F-SemiCD method. The code will be open at: https://github.com/ChengxiHAN/C2F-SemiCDand-C2FNet.
Change Guiding Network: Incorporating Change Prior to Guide Change Detection in Remote Sensing Imagery
Apr 14, 2024



The rapid advancement of automated artificial intelligence algorithms and remote sensing instruments has benefited change detection (CD) tasks. However, there is still a lot of space to study for precise detection, especially the edge integrity and internal holes phenomenon of change features. In order to solve these problems, we design the Change Guiding Network (CGNet), to tackle the insufficient expression problem of change features in the conventional U-Net structure adopted in previous methods, which causes inaccurate edge detection and internal holes. Change maps from deep features with rich semantic information are generated and used as prior information to guide multi-scale feature fusion, which can improve the expression ability of change features. Meanwhile, we propose a self-attention module named Change Guide Module (CGM), which can effectively capture the long-distance dependency among pixels and effectively overcome the problem of the insufficient receptive field of traditional convolutional neural networks. On four major CD datasets, we verify the usefulness and efficiency of the CGNet, and a large number of experiments and ablation studies demonstrate the effectiveness of CGNet. We're going to open-source our code at https://github.com/ChengxiHAN/CGNet-CD.
Learning without Exact Guidance: Updating Large-scale High-resolution Land Cover Maps from Low-resolution Historical Labels
Mar 08, 2024Large-scale high-resolution (HR) land-cover mapping is a vital task to survey the Earth's surface and resolve many challenges facing humanity. However, it is still a non-trivial task hindered by complex ground details, various landforms, and the scarcity of accurate training labels over a wide-span geographic area. In this paper, we propose an efficient, weakly supervised framework (Paraformer) to guide large-scale HR land-cover mapping with easy-access historical land-cover data of low resolution (LR). Specifically, existing land-cover mapping approaches reveal the dominance of CNNs in preserving local ground details but still suffer from insufficient global modeling in various landforms. Therefore, we design a parallel CNN-Transformer feature extractor in Paraformer, consisting of a downsampling-free CNN branch and a Transformer branch, to jointly capture local and global contextual information. Besides, facing the spatial mismatch of training data, a pseudo-label-assisted training (PLAT) module is adopted to reasonably refine LR labels for weakly supervised semantic segmentation of HR images. Experiments on two large-scale datasets demonstrate the superiority of Paraformer over other state-of-the-art methods for automatically updating HR land-cover maps from LR historical labels.
Cross-level Attention with Overlapped Windows for Camouflaged Object Detection
Nov 28, 2023Camouflaged objects adaptively fit their color and texture with the environment, which makes them indistinguishable from the surroundings. Current methods revealed that high-level semantic features can highlight the differences between camouflaged objects and the backgrounds. Consequently, they integrate high-level semantic features with low-level detailed features for accurate camouflaged object detection (COD). Unlike previous designs for multi-level feature fusion, we state that enhancing low-level features is more impending for COD. In this paper, we propose an overlapped window cross-level attention (OWinCA) to achieve the low-level feature enhancement guided by the highest-level features. By sliding an aligned window pair on both the highest- and low-level feature maps, the high-level semantics are explicitly integrated into the low-level details via cross-level attention. Additionally, it employs an overlapped window partition strategy to alleviate the incoherence among windows, which prevents the loss of global information. These adoptions enable the proposed OWinCA to enhance low-level features by promoting the separability of camouflaged objects. The associated proposed OWinCANet fuses these enhanced multi-level features by simple convolution operation to achieve the final COD. Experiments conducted on three large-scale COD datasets demonstrate that our OWinCANet significantly surpasses the current state-of-the-art COD methods.
Building Extraction from Remote Sensing Images via an Uncertainty-Aware Network
Jul 23, 2023



Building extraction aims to segment building pixels from remote sensing images and plays an essential role in many applications, such as city planning and urban dynamic monitoring. Over the past few years, deep learning methods with encoder-decoder architectures have achieved remarkable performance due to their powerful feature representation capability. Nevertheless, due to the varying scales and styles of buildings, conventional deep learning models always suffer from uncertain predictions and cannot accurately distinguish the complete footprints of the building from the complex distribution of ground objects, leading to a large degree of omission and commission. In this paper, we realize the importance of uncertain prediction and propose a novel and straightforward Uncertainty-Aware Network (UANet) to alleviate this problem. To verify the performance of our proposed UANet, we conduct extensive experiments on three public building datasets, including the WHU building dataset, the Massachusetts building dataset, and the Inria aerial image dataset. Results demonstrate that the proposed UANet outperforms other state-of-the-art algorithms by a large margin.
Towards Complex Backgrounds: A Unified Difference-Aware Decoder for Binary Segmentation
Oct 27, 2022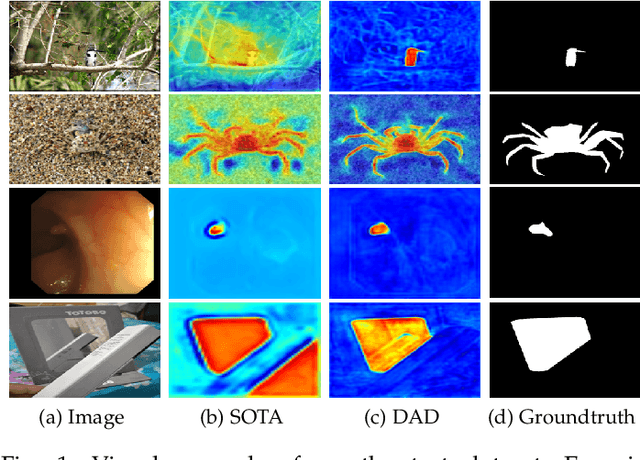



Binary segmentation is used to distinguish objects of interest from background, and is an active area of convolutional encoder-decoder network research. The current decoders are designed for specific objects based on the common backbones as the encoders, but cannot deal with complex backgrounds. Inspired by the way human eyes detect objects of interest, a new unified dual-branch decoder paradigm named the difference-aware decoder is proposed in this paper to explore the difference between the foreground and the background and separate the objects of interest in optical images. The difference-aware decoder imitates the human eye in three stages using the multi-level features output by the encoder. In Stage A, the first branch decoder of the difference-aware decoder is used to obtain a guide map. The highest-level features are enhanced with a novel field expansion module and a dual residual attention module, and are combined with the lowest-level features to obtain the guide map. In Stage B, the other branch decoder adopts a middle feature fusion module to make trade-offs between textural details and semantic information and generate background-aware features. In Stage C, the proposed difference-aware extractor, consisting of a difference guidance model and a difference enhancement module, fuses the guide map from Stage A and the background-aware features from Stage B, to enlarge the differences between the foreground and the background and output a final detection result. The results demonstrate that the difference-aware decoder can achieve a higher accuracy than the other state-of-the-art binary segmentation methods for these tasks.