 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Building Change Detection for Large-Scale Small Changes: Benchmark and Baseline
Mar 19, 2026Change detection in optical remote sensing imagery is susceptible to illumination fluctuations, seasonal changes, and variations in surface land-cover materials. Relying solely on RGB imagery often produces pseudo-changes and leads to semantic ambiguity in features. Incorporating near-infrared (NIR) information provides heterogeneous physical cues that are complementary to visible light, thereby enhancing the discriminability of building materials and tiny structures while improving detection accuracy. However, existing multi-modal datasets generally lack high-resolution and accurately registered bi-temporal imagery, and current methods often fail to fully exploit the inherent heterogeneity between these modalities. To address these issues, we introduce the Large-scale Small-change Multi-modal Dataset (LSMD), a bi-temporal RGB-NIR building change detection benchmark dataset targeting small changes in realistic scenarios, providing a rigorous testing platform for evaluating multi-modal change detection methods in complex environments. Based on LSMD, we further propose the Multi-modal Spectral Complementarity Network (MSCNet) to achieve effective cross-modal feature fusion. MSCNet comprises three key components: the Neighborhood Context Enhancement Module (NCEM) to strengthen local spatial details, the Cross-modal Alignment and Interaction Module (CAIM) to enable deep interaction between RGB and NIR features, and the Saliency-aware Multisource Refinement Module (SMRM) to progressively refine fused features. Extensive experiments demonstrate that MSCNet effectively leverages multi-modal information and consistently outperforms existing methods under multiple input configurations, validating its efficacy for fine-grained building change detection. The source code will be made publicly available at: https://github.com/AeroVILab-AHU/LSMD
MM-OVSeg:Multimodal Optical-SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
Mar 18, 2026Open-vocabulary segmentation enables pixel-level recognition from an open set of textual categories, allowing generalization beyond fixed classes. Despite great potential in remote sensing, progress in this area remains largely limited to clear-sky optical data and struggles under cloudy or haze-contaminated conditions. We present MM-OVSeg, a multimodal Optical-SAR fusion framework for resilient open-vocabulary segmentation under adverse weather conditions. MM-OVSeg leverages the complementary strengths of the two modalities--optical imagery provides rich spectral semantics, while synthetic aperture radar (SAR) offers cloud-penetrating structural cues. To address the cross-modal domain gap and the limited dense prediction capability of current vision-language models, we propose two key designs: a cross-modal unification process for multi-sensor representation alignment, and a dual-encoder fusion module that integrates hierarchical features from multiple vision foundation models for text-aligned multimodal segmentation. Extensive experiments demonstrate that MM-OVSeg achieves superior robustness and generalization across diverse cloud conditions. The source dataset and code are available here.
CrossEarth-SAR: A SAR-Centric and Billion-Scale Geospatial Foundation Model for Domain Generalizable Semantic Segmentation
Mar 12, 2026Synthetic Aperture Radar (SAR) enables global, all-weather earth observation. However, owing to diverse imaging mechanisms, domain shifts across sensors and regions severely hinder its semantic generalization. To address this, we present CrossEarth-SAR, the first billion-scale SAR vision foundation model built upon a novel physics-guided sparse mixture-of-experts (MoE) architecture incorporating physical descriptors, explicitly designed for cross-domain semantic segmentation. To facilitate large-scale pre-training, we develop CrossEarth-SAR-200K, a weakly and fully supervised dataset that unifies public and private SAR imagery. We also introduce a benchmark suite comprising 22 sub-benchmarks across 8 distinct domain gaps, establishing the first unified standard for domain generalization semantic segmentation on SAR imagery. Extensive experiments demonstrate that CrossEarth-SAR achieves state-of-the-art results on 20 benchmarks, surpassing previous methods by over 10\% mIoU on some benchmarks under multi-gap transfer. All code, benchmark and datasets will be publicly available.
Experience-Driven Multi-Agent Systems Are Training-free Context-aware Earth Observers
Jan 30, 2026Recent advances have enabled large language model (LLM) agents to solve complex tasks by orchestrating external tools. However, these agents often struggle in specialized, tool-intensive domains that demand long-horizon execution, tight coordination across modalities, and strict adherence to implicit tool constraints. Earth Observation (EO) tasks exemplify this challenge due to the multi-modal and multi-temporal data inputs, as well as the requirements of geo-knowledge constraints (spectrum library, spatial reasoning, etc): many high-level plans can be derailed by subtle execution errors that propagate through a pipeline and invalidate final results. A core difficulty is that existing agents lack a mechanism to learn fine-grained, tool-level expertise from interaction. Without such expertise, they cannot reliably configure tool parameters or recover from mid-execution failures, limiting their effectiveness in complex EO workflows. To address this, we introduce \textbf{GeoEvolver}, a self-evolving multi-agent system~(MAS) that enables LLM agents to acquire EO expertise through structured interaction without any parameter updates. GeoEvolver decomposes each query into independent sub-goals via a retrieval-augmented multi-agent orchestrator, then explores diverse tool-parameter configurations at the sub-goal level. Successful patterns and root-cause attribution from failures are then distilled in an evolving memory bank that provides in-context demonstrations for future queries. Experiments on three tool-integrated EO benchmarks show that GeoEvolver consistently improves end-to-end task success, with an average gain of 12\% across multiple LLM backbones, demonstrating that EO expertise can emerge progressively from efficient, fine-grained interactions with the environment.
Advancing Weakly-Supervised Change Detection in Satellite Images via Adversarial Class Prompting
Aug 24, 2025


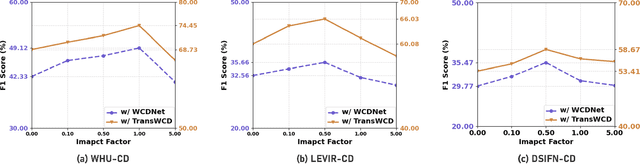
Weakly-Supervised Change Detection (WSCD) aims to distinguish specific object changes (e.g., objects appearing or disappearing) from background variations (e.g., environmental changes due to light, weather, or seasonal shifts) in paired satellite images, relying only on paired image (i.e., image-level) classification labels. This technique significantly reduces the need for dense annotations required in fully-supervised change detection. However, as image-level supervision only indicates whether objects have changed in a scene, WSCD methods often misclassify background variations as object changes, especially in complex remote-sensing scenarios. In this work, we propose an Adversarial Class Prompting (AdvCP) method to address this co-occurring noise problem, including two phases: a) Adversarial Prompt Mining: After each training iteration, we introduce adversarial prompting perturbations, using incorrect one-hot image-level labels to activate erroneous feature mappings. This process reveals co-occurring adversarial samples under weak supervision, namely background variation features that are likely to be misclassified as object changes. b) Adversarial Sample Rectification: We integrate these adversarially prompt-activated pixel samples into training by constructing an online global prototype. This prototype is built from an exponentially weighted moving average of the current batch and all historical training data. Our AdvCP can be seamlessly integrated into current WSCD methods without adding additional inference cost. Experiments on ConvNet, Transformer, and Segment Anything Model (SAM)-based baselines demonstrate significant performance enhancements. Furthermore, we demonstrate the generalizability of AdvCP to other multi-class weakly-supervised dense prediction scenarios. Code is available at https://github.com/zhenghuizhao/AdvCP
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
Enhancing Monocular Height Estimation via Sparse LiDAR-Guided Correction
May 11, 2025Monocular height estimation (MHE) from very-high-resolution (VHR) remote sensing imagery via deep learning is notoriously challenging due to the lack of sufficient structural information. Conventional digital elevation models (DEMs), typically derived from airborne LiDAR or multi-view stereo, remain costly and geographically limited. Recently, models trained on synthetic data and refined through domain adaptation have shown remarkable performance in MHE, yet it remains unclear how these models make predictions or how reliable they truly are. In this paper, we investigate a state-of-the-art MHE model trained purely on synthetic data to explore where the model looks when making height predictions. Through systematic analyses, we find that the model relies heavily on shadow cues, a factor that can lead to overestimation or underestimation of heights when shadows deviate from expected norms. Furthermore, the inherent difficulty of evaluating regression tasks with the human eye underscores additional limitations of purely synthetic training. To address these issues, we propose a novel correction pipeline that integrates sparse, imperfect global LiDAR measurements (ICESat-2) with deep-learning outputs to improve local accuracy and achieve spatially consistent corrections. Our method comprises two stages: pre-processing raw ICESat-2 data, followed by a random forest-based approach to densely refine height estimates. Experiments in three representative urban regions -- Saint-Omer, Tokyo, and Sao Paulo -- reveal substantial error reductions, with mean absolute error (MAE) decreased by 22.8\%, 6.9\%, and 4.9\%, respectively. These findings highlight the critical role of shadow awareness in synthetic data-driven models and demonstrate how fusing imperfect real-world LiDAR data can bolster the robustness of MHE, paving the way for more reliable and scalable 3D mapping solutions.
SARLANG-1M: A Benchmark for Vision-Language Modeling in SAR Image Understanding
Apr 04, 2025

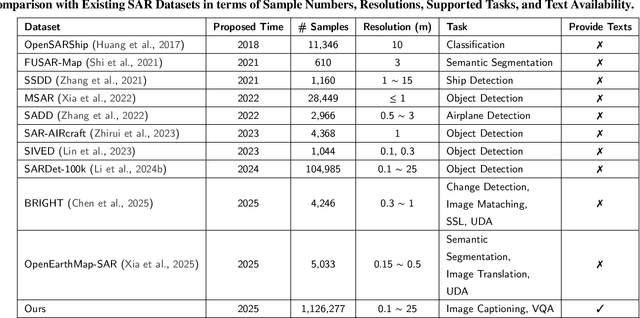
Synthetic Aperture Radar (SAR) is a crucial remote sensing technology, enabling all-weather, day-and-night observation with strong surface penetration for precise and continuous environmental monitoring and analysis. However, SAR image interpretation remains challenging due to its complex physical imaging mechanisms and significant visual disparities from human perception. Recently, Vision-Language Models (VLMs) have demonstrated remarkable success in RGB image understanding, offering powerful open-vocabulary interpretation and flexible language interaction. However, their application to SAR images is severely constrained by the absence of SAR-specific knowledge in their training distributions, leading to suboptimal performance. To address this limitation, we introduce SARLANG-1M, a large-scale benchmark tailored for multimodal SAR image understanding, with a primary focus on integrating SAR with textual modality. SARLANG-1M comprises more than 1 million high-quality SAR image-text pairs collected from over 59 cities worldwide. It features hierarchical resolutions (ranging from 0.1 to 25 meters), fine-grained semantic descriptions (including both concise and detailed captions), diverse remote sensing categories (1,696 object types and 16 land cover classes), and multi-task question-answering pairs spanning seven applications and 1,012 question types. Extensive experiments on mainstream VLMs demonstrate that fine-tuning with SARLANG-1M significantly enhances their performance in SAR image interpretation, reaching performance comparable to human experts. The dataset and code will be made publicly available at https://github.com/Jimmyxichen/SARLANG-1M.
Multi-label classification for multi-temporal, multi-spatial coral reef condition monitoring using vision foundation model with adapter learning
Mar 29, 2025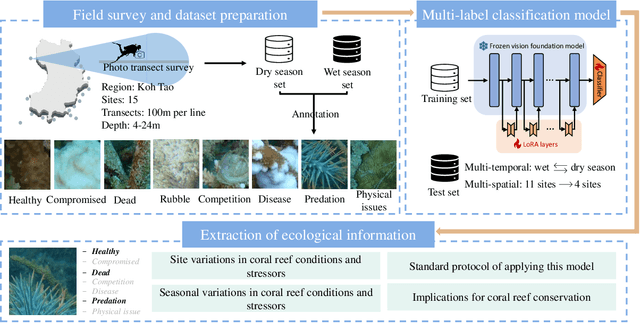
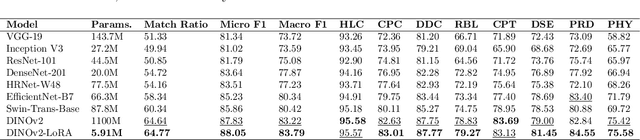
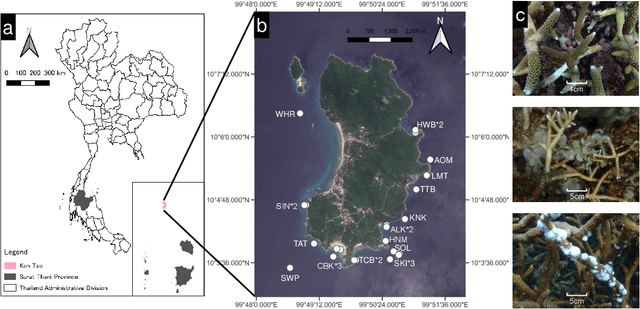
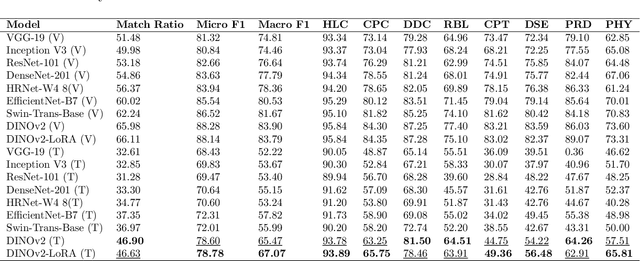
Coral reef ecosystems provide essential ecosystem services, but face significant threats from climate change and human activities. Although advances in deep learning have enabled automatic classification of coral reef conditions, conventional deep models struggle to achieve high performance when processing complex underwater ecological images. Vision foundation models, known for their high accuracy and cross-domain generalizability, offer promising solutions. However, fine-tuning these models requires substantial computational resources and results in high carbon emissions. To address these challenges, adapter learning methods such as Low-Rank Adaptation (LoRA) have emerged as a solution. This study introduces an approach integrating the DINOv2 vision foundation model with the LoRA fine-tuning method. The approach leverages multi-temporal field images collected through underwater surveys at 15 dive sites at Koh Tao, Thailand, with all images labeled according to universal standards used in citizen science-based conservation programs. The experimental results demonstrate that the DINOv2-LoRA model achieved superior accuracy, with a match ratio of 64.77%, compared to 60.34% achieved by the best conventional model. Furthermore, incorporating LoRA reduced the trainable parameters from 1,100M to 5.91M. Transfer learning experiments conducted under different temporal and spatial settings highlight the exceptional generalizability of DINOv2-LoRA across different seasons and sites. This study is the first to explore the efficient adaptation of foundation models for multi-label classification of coral reef conditions under multi-temporal and multi-spatial settings. The proposed method advances the classification of coral reef conditions and provides a tool for monitoring, conserving, and managing coral reef ecosystems.
A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Feb 05, 2025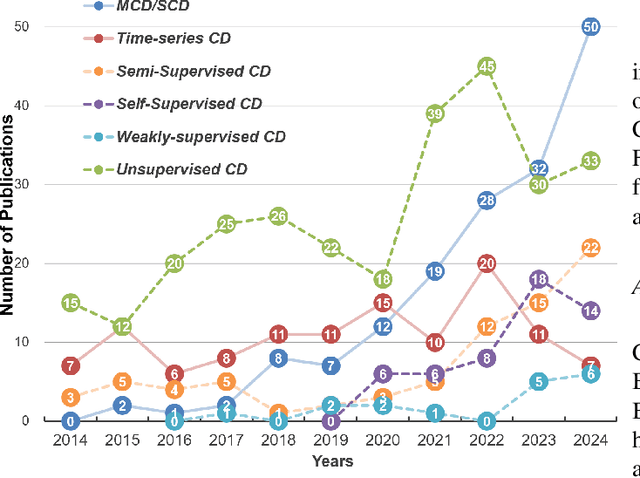
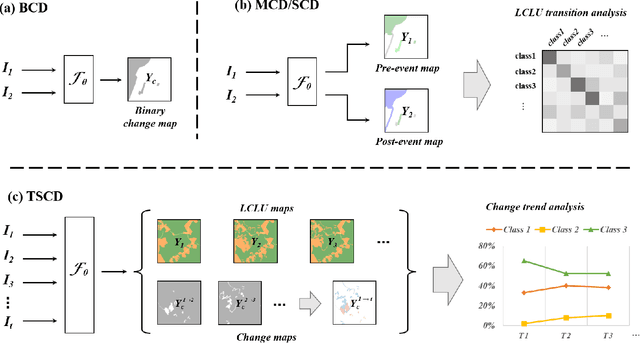
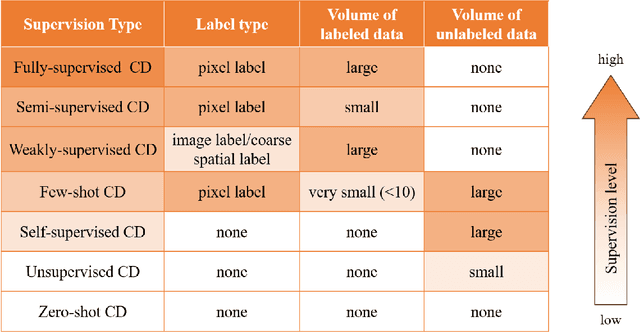
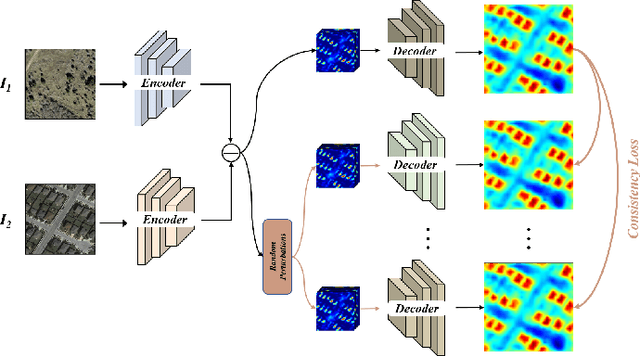
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the 'data-hungry' issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.