 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleRL: Sim-to-Real Deep Reinforcement Learning for Robust Autonomous Bicycle Control
Mar 16, 2026Autonomous bicycles offer a promising agile solution for urban mobility and last-mile logistics, however, conventional control strategies often struggle with their underactuated nonlinear dynamics, suffering from sensitivity to model mismatches and limited adaptability to real-world uncertainties. To address this, this paper presents CycleRL, the first sim-to-real deep reinforcement learning framework designed for robust autonomous bicycle control. Our approach trains an end-to-end neural control policy within the high-fidelity NVIDIA Isaac Sim environment, leveraging Proximal Policy Optimization (PPO) to circumvent the need for an explicit dynamics model. The framework features a composite reward function tailored for concurrent balance maintenance, velocity tracking, and steering control. Crucially, systematic domain randomization is employed to bridge the simulation-to-reality gap and facilitate direct transfer. In simulation, CycleRL achieves considerable performance, including a 99.90% balance success rate, a low steering tracking error of 1.15°, and a velocity tracking error of 0.18 m/s. These quantitative results, coupled with successful hardware transfer, validate DRL as an effective paradigm for autonomous bicycle control, offering superior adaptability over traditional methods. Video demonstrations are available at https://anony6f05.github.io/CycleRL/.
FLYINGTRUST: A Benchmark for Quadrotor Navigation Across Scenarios and Vehicles
Oct 30, 2025Visual navigation algorithms for quadrotors often exhibit a large variation in performance when transferred across different vehicle platforms and scene geometries, which increases the cost and risk of field deployment. To support systematic early-stage evaluation, we introduce FLYINGTRUST, a high-fidelity, configurable benchmarking framework that measures how platform kinodynamics and scenario structure jointly affect navigation robustness. FLYINGTRUST models vehicle capability with two compact, physically interpretable indicators: maximum thrust-to-weight ratio and axis-wise maximum angular acceleration. The benchmark pairs a diverse scenario library with a heterogeneous set of real and virtual platforms and prescribes a standardized evaluation protocol together with a composite scoring method that balances scenario importance, platform importance and performance stability. We use FLYINGTRUST to compare representative optimization-based and learning-based navigation approaches under identical conditions, performing repeated trials per platform-scenario combination and reporting uncertainty-aware metrics. The results reveal systematic patterns: navigation success depends predictably on platform capability and scene geometry, and different algorithms exhibit distinct preferences and failure modes across the evaluated conditions. These observations highlight the practical necessity of incorporating both platform capability and scenario structure into algorithm design, evaluation, and selection, and they motivate future work on methods that remain robust across diverse platforms and scenarios.
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
Oct 31, 2024


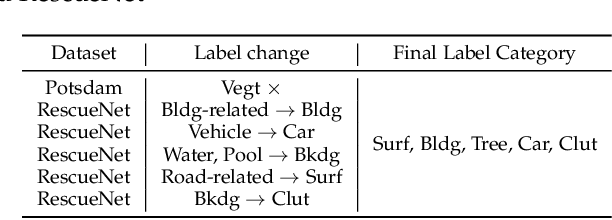
The field of Remote Sensing Domain Generalization (RSDG) has emerged as a critical and valuable research frontier, focusing on developing models that generalize effectively across diverse scenarios. Despite the substantial domain gaps in RS images that are characterized by variabilities such as location, wavelength, and sensor type, research in this area remains underexplored: (1) Current cross-domain methods primarily focus on Domain Adaptation (DA), which adapts models to predefined domains rather than to unseen ones; (2) Few studies targeting the RSDG issue, especially for semantic segmentation tasks, where existing models are developed for specific unknown domains, struggling with issues of underfitting on other unknown scenarios; (3) Existing RS foundation models tend to prioritize in-domain performance over cross-domain generalization. To this end, we introduce the first vision foundation model for RSDG semantic segmentation, CrossEarth. CrossEarth demonstrates strong cross-domain generalization through a specially designed data-level Earth-Style Injection pipeline and a model-level Multi-Task Training pipeline. In addition, for the semantic segmentation task, we have curated an RSDG benchmark comprising 28 cross-domain settings across various regions, spectral bands, platforms, and climates, providing a comprehensive framework for testing the generalizability of future RSDG models. Extensive experiments on this benchmark demonstrate the superiority of CrossEarth over existing state-of-the-art methods.
CoDA: Instructive Chain-of-Domain Adaptation with Severity-Aware Visual Prompt Tuning
Apr 04, 2024Unsupervised Domain Adaptation (UDA) aims to adapt models from labeled source domains to unlabeled target domains. When adapting to adverse scenes, existing UDA methods fail to perform well due to the lack of instructions, leading their models to overlook discrepancies within all adverse scenes. To tackle this, we propose CoDA which instructs models to distinguish, focus, and learn from these discrepancies at scene and image levels. Specifically, CoDA consists of a Chain-of-Domain (CoD) strategy and a Severity-Aware Visual Prompt Tuning (SAVPT) mechanism. CoD focuses on scene-level instructions to divide all adverse scenes into easy and hard scenes, guiding models to adapt from source to easy domains with easy scene images, and then to hard domains with hard scene images, thereby laying a solid foundation for whole adaptations. Building upon this foundation, we employ SAVPT to dive into more detailed image-level instructions to boost performance. SAVPT features a novel metric Severity that divides all adverse scene images into low-severity and high-severity images. Then Severity directs visual prompts and adapters, instructing models to concentrate on unified severity features instead of scene-specific features, without adding complexity to the model architecture. CoDA achieves SOTA performances on widely-used benchmarks under all adverse scenes. Notably, CoDA outperforms the existing ones by 4.6%, and 10.3% mIoU on the Foggy Driving, and Foggy Zurich benchmarks, respectively. Our code is available at https://github.com/Cuzyoung/CoDA
FGO-ILNS: Tightly Coupled Multi-Sensor Integrated Navigation System Based on Factor Graph Optimization for Autonomous Underwater Vehicle
Oct 22, 2023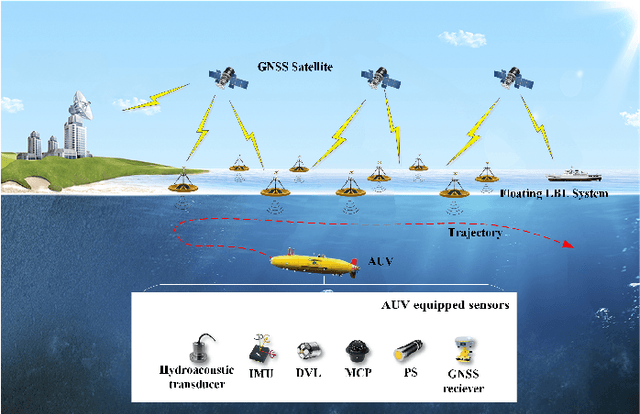
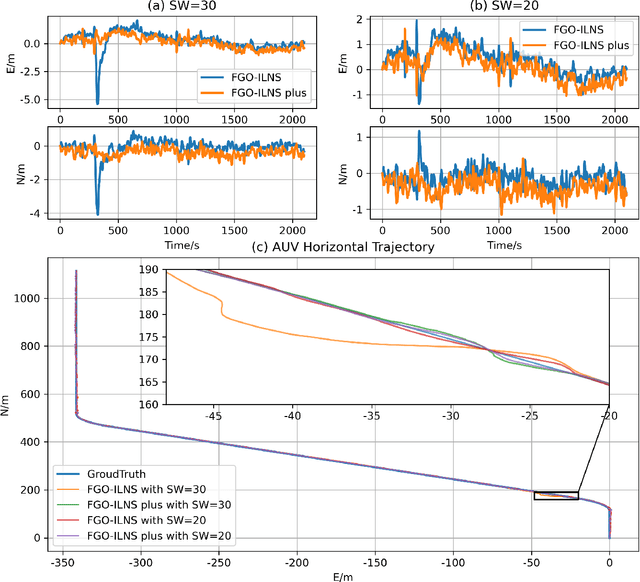
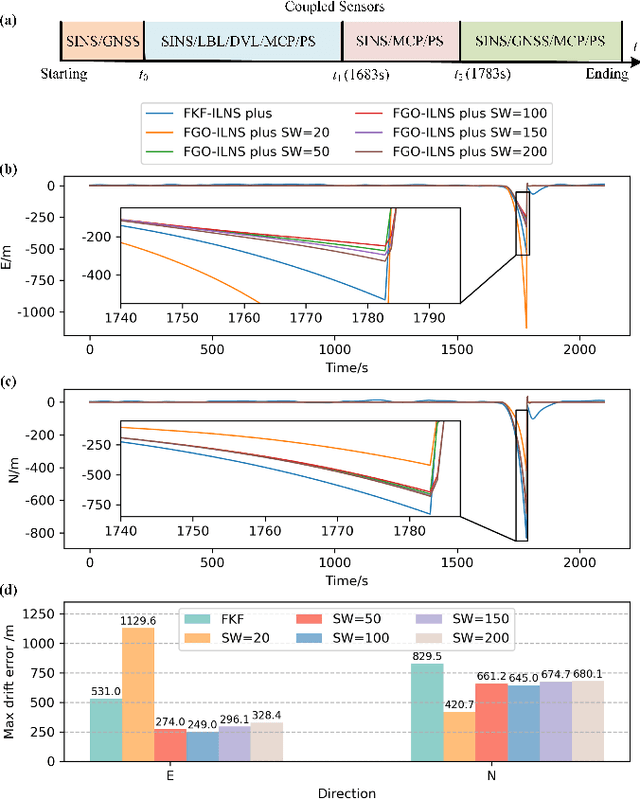
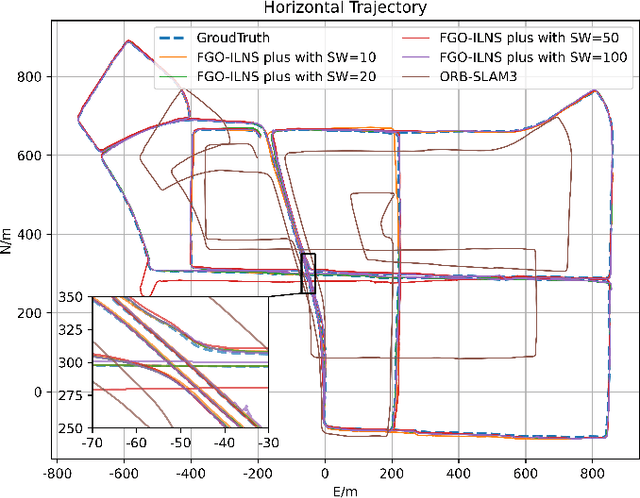
Multi-sensor fusion is an effective way to enhance the positioning performance of autonomous underwater vehicles (AUVs). However, underwater multi-sensor fusion faces challenges such as heterogeneous frequency and dynamic availability of sensors. Traditional filter-based algorithms suffer from low accuracy and robustness when sensors become unavailable. The factor graph optimization (FGO) can enable multi-sensor plug-and-play despite data frequency. Therefore, we present an FGO-based strapdown inertial navigation system (SINS) and long baseline location (LBL) system tightly coupled navigation system (FGO-ILNS). Sensors such as Doppler velocity log (DVL), magnetic compass pilot (MCP), pressure sensor (PS), and global navigation satellite system (GNSS) can be tightly coupled with FGO-ILNS to satisfy different navigation scenarios. In this system, we propose a floating LBL slant range difference factor model tightly coupled with IMU preintegration factor to achieve unification of global position above and below water. Furthermore, to address the issue of sensor measurements not being synchronized with the LBL during fusion, we employ forward-backward IMU preintegration to construct sensor factors such as GNSS and DVL. Moreover, we utilize the marginalization method to reduce the computational load of factor graph optimization. Simulation and public KAIST dataset experiments have verified that, compared to filter-based algorithms like the extended Kalman filter and federal Kalman filter, as well as the state-of-the-art optimization-based algorithm ORB-SLAM3, our proposed FGO-ILNS leads in accuracy and robustness.