 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee It, Say It, Sorted: An Iterative Training-Free Framework for Visually-Grounded Multimodal Reasoning in LVLMs
Feb 25, 2026Recent large vision-language models (LVLMs) have demonstrated impressive reasoning ability by generating long chain-of-thought (CoT) responses. However, CoT reasoning in multimodal contexts is highly vulnerable to visual hallucination propagation: once an intermediate reasoning step becomes inconsistent with the visual evidence, subsequent steps-even if logically valid-can still lead to incorrect final answers. Existing solutions attempt to mitigate this issue by training models to "think with images" via reinforcement learning (RL). While effective, these methods are costly, model-specific, and difficult to generalize across architectures. Differently, we present a lightweight method that bypasses RL training and provides an iterative, training-free, plug-and-play framework for visually-grounded multimodal reasoning. Our key idea is to supervise each reasoning step at test time with visual evidence, ensuring that every decoded token is justified by corresponding visual cues. Concretely, we construct a textual visual-evidence pool that guides the model's reasoning generation. When existing evidence is insufficient, a visual decider module dynamically extracts additional relevant evidence from the image based on the ongoing reasoning context, expanding the pool until the model achieves sufficient visual certainty to terminate reasoning and produce the final answer. Extensive experiments on multiple LVLM backbones and benchmarks demonstrate the effectiveness of our approach. Our method achieves 16.5%-29.5% improvements on TreeBench and 13.7% RH-AUC gains on RH-Bench, substantially reducing hallucination rates while improving reasoning accuracy without additional training.
Inferring Dynamic Physical Properties from Video Foundation Models
Oct 02, 2025We study the task of predicting dynamic physical properties from videos. More specifically, we consider physical properties that require temporal information to be inferred: elasticity of a bouncing object, viscosity of a flowing liquid, and dynamic friction of an object sliding on a surface. To this end, we make the following contributions: (i) We collect a new video dataset for each physical property, consisting of synthetic training and testing splits, as well as a real split for real world evaluation. (ii) We explore three ways to infer the physical property from videos: (a) an oracle method where we supply the visual cues that intrinsically reflect the property using classical computer vision techniques; (b) a simple read out mechanism using a visual prompt and trainable prompt vector for cross-attention on pre-trained video generative and self-supervised models; and (c) prompt strategies for Multi-modal Large Language Models (MLLMs). (iii) We show that video foundation models trained in a generative or self-supervised manner achieve a similar performance, though behind that of the oracle, and MLLMs are currently inferior to the other models, though their performance can be improved through suitable prompting.
Robotic Visual Instruction
May 01, 2025Recently, natural language has been the primary medium for human-robot interaction. However, its inherent lack of spatial precision for robotic control introduces challenges such as ambiguity and verbosity. To address these limitations, we introduce the Robotic Visual Instruction (RoVI), a novel paradigm to guide robotic tasks through an object-centric, hand-drawn symbolic representation. RoVI effectively encodes spatial-temporal information into human-interpretable visual instructions through 2D sketches, utilizing arrows, circles, colors, and numbers to direct 3D robotic manipulation. To enable robots to understand RoVI better and generate precise actions based on RoVI, we present Visual Instruction Embodied Workflow (VIEW), a pipeline formulated for RoVI-conditioned policies. This approach leverages Vision-Language Models (VLMs) to interpret RoVI inputs, decode spatial and temporal constraints from 2D pixel space via keypoint extraction, and then transform them into executable 3D action sequences. We additionally curate a specialized dataset of 15K instances to fine-tune small VLMs for edge deployment, enabling them to effectively learn RoVI capabilities. Our approach is rigorously validated across 11 novel tasks in both real and simulated environments, demonstrating significant generalization capability. Notably, VIEW achieves an 87.5% success rate in real-world scenarios involving unseen tasks that feature multi-step actions, with disturbances, and trajectory-following requirements. Code and Datasets in this paper will be released soon.
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
Oct 31, 2024


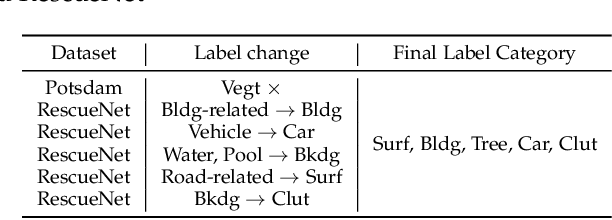
The field of Remote Sensing Domain Generalization (RSDG) has emerged as a critical and valuable research frontier, focusing on developing models that generalize effectively across diverse scenarios. Despite the substantial domain gaps in RS images that are characterized by variabilities such as location, wavelength, and sensor type, research in this area remains underexplored: (1) Current cross-domain methods primarily focus on Domain Adaptation (DA), which adapts models to predefined domains rather than to unseen ones; (2) Few studies targeting the RSDG issue, especially for semantic segmentation tasks, where existing models are developed for specific unknown domains, struggling with issues of underfitting on other unknown scenarios; (3) Existing RS foundation models tend to prioritize in-domain performance over cross-domain generalization. To this end, we introduce the first vision foundation model for RSDG semantic segmentation, CrossEarth. CrossEarth demonstrates strong cross-domain generalization through a specially designed data-level Earth-Style Injection pipeline and a model-level Multi-Task Training pipeline. In addition, for the semantic segmentation task, we have curated an RSDG benchmark comprising 28 cross-domain settings across various regions, spectral bands, platforms, and climates, providing a comprehensive framework for testing the generalizability of future RSDG models. Extensive experiments on this benchmark demonstrate the superiority of CrossEarth over existing state-of-the-art methods.
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024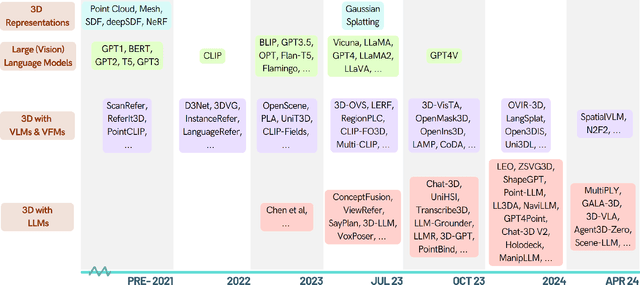
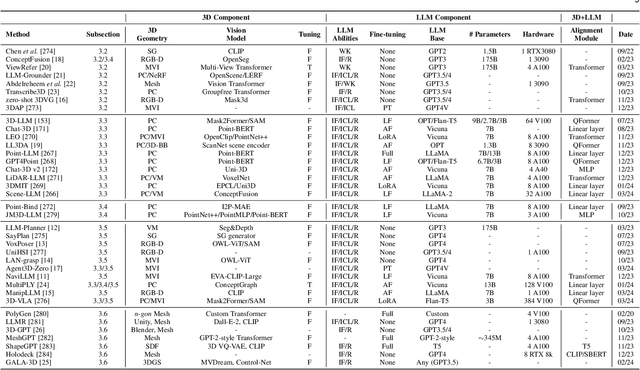
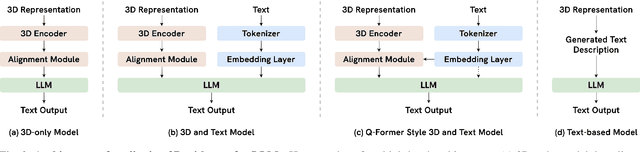
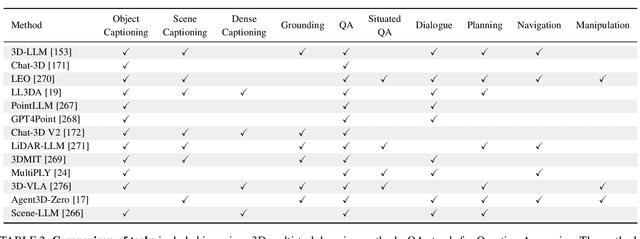
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
Dec 15, 2023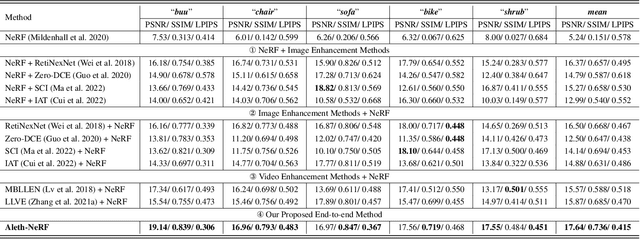

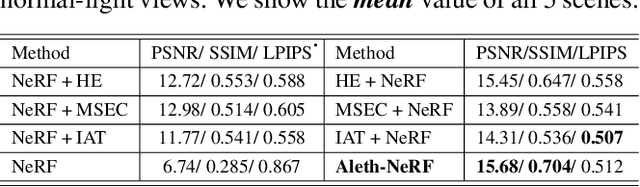

The standard Neural Radiance Fields (NeRF) paradigm employs a viewer-centered methodology, entangling the aspects of illumination and material reflectance into emission solely from 3D points. This simplified rendering approach presents challenges in accurately modeling images captured under adverse lighting conditions, such as low light or over-exposure. Motivated by the ancient Greek emission theory that posits visual perception as a result of rays emanating from the eyes, we slightly refine the conventional NeRF framework to train NeRF under challenging light conditions and generate normal-light condition novel views unsupervised. We introduce the concept of a "Concealing Field," which assigns transmittance values to the surrounding air to account for illumination effects. In dark scenarios, we assume that object emissions maintain a standard lighting level but are attenuated as they traverse the air during the rendering process. Concealing Field thus compel NeRF to learn reasonable density and colour estimations for objects even in dimly lit situations. Similarly, the Concealing Field can mitigate over-exposed emissions during the rendering stage. Furthermore, we present a comprehensive multi-view dataset captured under challenging illumination conditions for evaluation. Our code and dataset available at https://github.com/cuiziteng/Aleth-NeRF
Unifying Image Processing as Visual Prompting Question Answering
Oct 16, 2023



Image processing is a fundamental task in computer vision, which aims at enhancing image quality and extracting essential features for subsequent vision applications. Traditionally, task-specific models are developed for individual tasks and designing such models requires distinct expertise. Building upon the success of large language models (LLMs) in natural language processing (NLP), there is a similar trend in computer vision, which focuses on developing large-scale models through pretraining and in-context learning. This paradigm shift reduces the reliance on task-specific models, yielding a powerful unified model to deal with various tasks. However, these advances have predominantly concentrated on high-level vision tasks, with less attention paid to low-level vision tasks. To address this issue, we propose a universal model for general image processing that covers image restoration, image enhancement, image feature extraction tasks, \textit{etc}. Our proposed framework, named PromptGIP, unifies these diverse image processing tasks within a universal framework. Inspired by NLP question answering (QA) techniques, we employ a visual prompting question answering paradigm. Specifically, we treat the input-output image pair as a structured question-answer sentence, thereby reprogramming the image processing task as a prompting QA problem. PromptGIP can undertake diverse \textbf{cross-domain} tasks using provided visual prompts, eliminating the need for task-specific finetuning. Our methodology offers a universal and adaptive solution to general image processing. While PromptGIP has demonstrated a certain degree of out-of-domain task generalization capability, further research is expected to fully explore its more powerful emergent generalization.
Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following
Sep 01, 2023



We introduce Point-Bind, a 3D multi-modality model aligning point clouds with 2D image, language, audio, and video. Guided by ImageBind, we construct a joint embedding space between 3D and multi-modalities, enabling many promising applications, e.g., any-to-3D generation, 3D embedding arithmetic, and 3D open-world understanding. On top of this, we further present Point-LLM, the first 3D large language model (LLM) following 3D multi-modal instructions. By parameter-efficient fine-tuning techniques, Point-LLM injects the semantics of Point-Bind into pre-trained LLMs, e.g., LLaMA, which requires no 3D instruction data, but exhibits superior 3D and multi-modal question-answering capacity. We hope our work may cast a light on the community for extending 3D point clouds to multi-modality applications. Code is available at https://github.com/ZiyuGuo99/Point-Bind_Point-LLM.
Networks are Slacking Off: Understanding Generalization Problem in Image Deraining
May 24, 2023



Deep deraining networks, while successful in laboratory benchmarks, consistently encounter substantial generalization issues when deployed in real-world applications. A prevailing perspective in deep learning encourages the use of highly complex training data, with the expectation that a richer image content knowledge will facilitate overcoming the generalization problem. However, through comprehensive and systematic experimentation, we discovered that this strategy does not enhance the generalization capability of these networks. On the contrary, it exacerbates the tendency of networks to overfit to specific degradations. Our experiments reveal that better generalization in a deraining network can be achieved by simplifying the complexity of the training data. This is due to the networks are slacking off during training, that is, learning the least complex elements in the image content and degradation to minimize training loss. When the complexity of the background image is less than that of the rain streaks, the network will prioritize the reconstruction of the background, thereby avoiding overfitting to the rain patterns and resulting in improved generalization performance. Our research not only offers a valuable perspective and methodology for better understanding the generalization problem in low-level vision tasks, but also displays promising practical potential.
Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
Dec 08, 2022



Continual Test-Time Adaptation (CTTA) aims to adapt the source model to continually changing unlabeled target domains without access to the source data. Existing methods mainly focus on model-based adaptation in a self-training manner, such as predicting pseudo labels for new domain datasets. Since pseudo labels are noisy and unreliable, these methods suffer from catastrophic forgetting and error accumulation when dealing with dynamic data distributions. Motivated by the prompt learning in NLP, in this paper, we propose to learn an image-level visual domain prompt for target domains while having the source model parameters frozen. During testing, the changing target datasets can be adapted to the source model by reformulating the input data with the learned visual prompts. Specifically, we devise two types of prompts, i.e., domains-specific prompts and domains-agnostic prompts, to extract current domain knowledge and maintain the domain-shared knowledge in the continual adaptation. Furthermore, we design a homeostasis-based prompt adaptation strategy to suppress domain-sensitive parameters in domain-invariant prompts to learn domain-shared knowledge more effectively. This transition from the model-dependent paradigm to the model-free one enables us to bypass the catastrophic forgetting and error accumulation problems. Experiments show that our proposed method achieves significant performance gains over state-of-the-art methods on four widely-used benchmarks, including CIFAR-10C, CIFAR-100C, ImageNet-C, and VLCS datasets.