 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiCLIP: An Efficient Contrastive Baseline for Open-domain Visual Entity Recognition
Mar 10, 2026Open-domain visual entity recognition (VER) seeks to associate images with entities in encyclopedic knowledge bases such as Wikipedia. Recent generative methods tailored for VER demonstrate strong performance but incur high computational costs, limiting their scalability and practical deployment. In this work, we revisit the contrastive paradigm for VER and introduce WikiCLIP, a simple yet effective framework that establishes a strong and efficient baseline for open-domain VER. WikiCLIP leverages large language model embeddings as knowledge-rich entity representations and enhances them with a Vision-Guided Knowledge Adaptor (VGKA) that aligns textual semantics with visual cues at the patch level. To further encourage fine-grained discrimination, a Hard Negative Synthesis Mechanism generates visually similar but semantically distinct negatives during training. Experimental results on popular open-domain VER benchmarks, such as OVEN, demonstrate that WikiCLIP significantly outperforms strong baselines. Specifically, WikiCLIP achieves a 16% improvement on the challenging OVEN unseen set, while reducing inference latency by nearly 100 times compared with the leading generative model, AutoVER. The project page is available at https://artanic30.github.io/project_pages/WikiCLIP/
Wiki-R1: Incentivizing Multimodal Reasoning for Knowledge-based VQA via Data and Sampling Curriculum
Mar 05, 2026Knowledge-Based Visual Question Answering (KB-VQA) requires models to answer questions about an image by integrating external knowledge, posing significant challenges due to noisy retrieval and the structured, encyclopedic nature of the knowledge base. These characteristics create a distributional gap from pretrained multimodal large language models (MLLMs), making effective reasoning and domain adaptation difficult in the post-training stage. In this work, we propose \textit{Wiki-R1}, a data-generation-based curriculum reinforcement learning framework that systematically incentivizes reasoning in MLLMs for KB-VQA. Wiki-R1 constructs a sequence of training distributions aligned with the model's evolving capability, bridging the gap from pretraining to the KB-VQA target distribution. We introduce \textit{controllable curriculum data generation}, which manipulates the retriever to produce samples at desired difficulty levels, and a \textit{curriculum sampling strategy} that selects informative samples likely to yield non-zero advantages during RL updates. Sample difficulty is estimated using observed rewards and propagated to unobserved samples to guide learning. Experiments on two KB-VQA benchmarks, Encyclopedic VQA and InfoSeek, demonstrate that Wiki-R1 achieves new state-of-the-art results, improving accuracy from 35.5\% to 37.1\% on Encyclopedic VQA and from 40.1\% to 44.1\% on InfoSeek. The project page is available at https://artanic30.github.io/project_pages/WikiR1/.
DA-DPO: Cost-efficient Difficulty-aware Preference Optimization for Reducing MLLM Hallucinations
Jan 02, 2026Direct Preference Optimization (DPO) has shown strong potential for mitigating hallucinations in Multimodal Large Language Models (MLLMs). However, existing multimodal DPO approaches often suffer from overfitting due to the difficulty imbalance in preference data. Our analysis shows that MLLMs tend to overemphasize easily distinguishable preference pairs, which hinders fine-grained hallucination suppression and degrades overall performance. To address this issue, we propose Difficulty-Aware Direct Preference Optimization (DA-DPO), a cost-effective framework designed to balance the learning process. DA-DPO consists of two main components: (1) Difficulty Estimation leverages pre-trained vision--language models with complementary generative and contrastive objectives, whose outputs are integrated via a distribution-aware voting strategy to produce robust difficulty scores without additional training; and (2) Difficulty-Aware Training reweights preference pairs based on their estimated difficulty, down-weighting easy samples while emphasizing harder ones to alleviate overfitting. This framework enables more effective preference optimization by prioritizing challenging examples, without requiring new data or extra fine-tuning stages. Extensive experiments demonstrate that DA-DPO consistently improves multimodal preference optimization, yielding stronger robustness to hallucinations and better generalization across standard benchmarks, while remaining computationally efficient. The project page is available at https://artanic30.github.io/project_pages/DA-DPO/.
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
May 09, 2024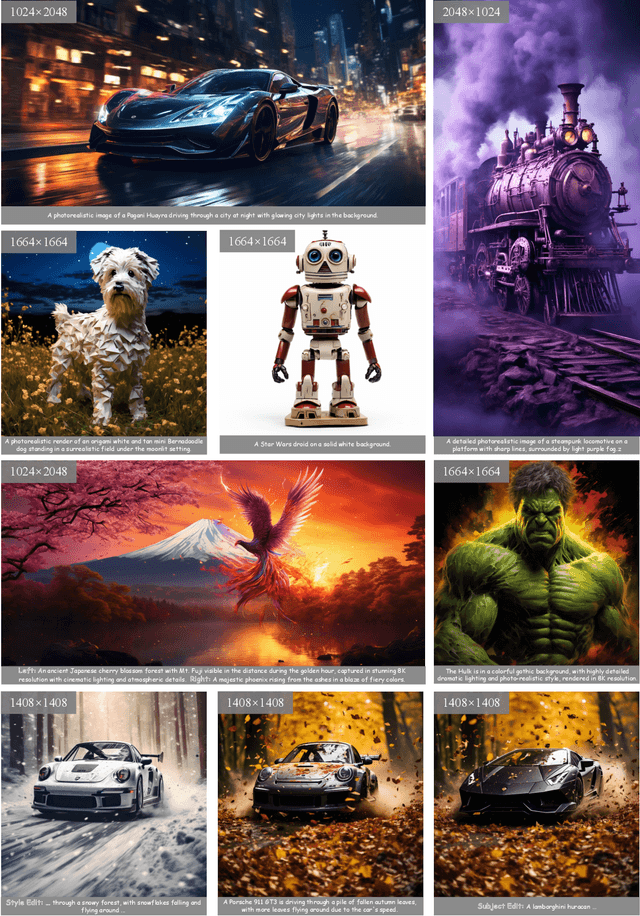
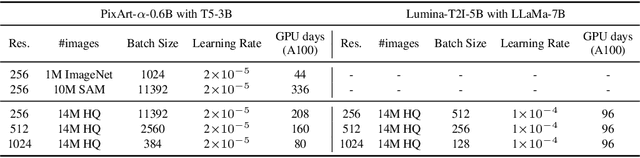
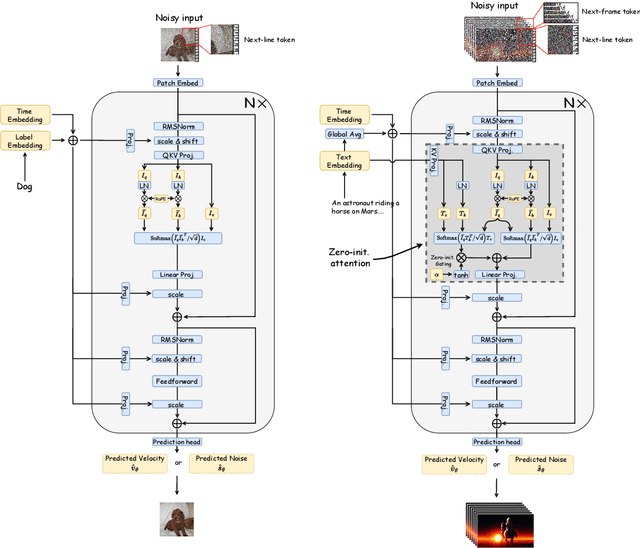
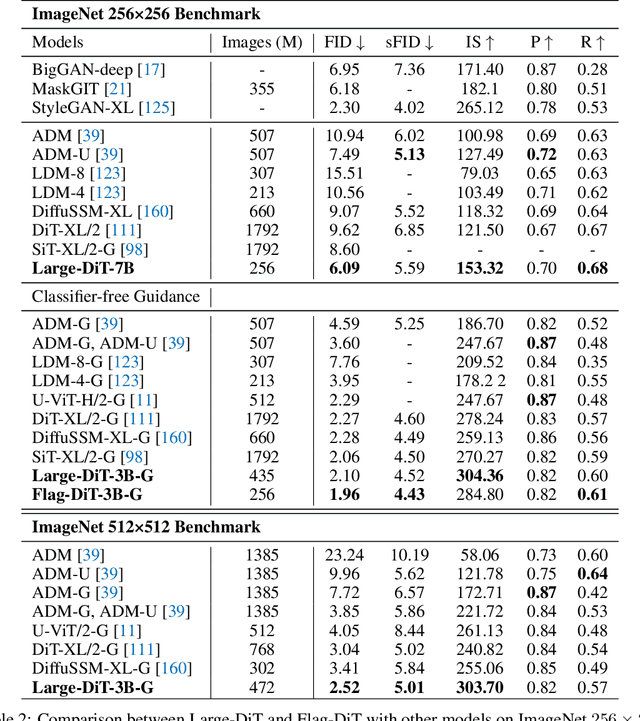
Sora unveils the potential of scaling Diffusion Transformer for generating photorealistic images and videos at arbitrary resolutions, aspect ratios, and durations, yet it still lacks sufficient implementation details. In this technical report, we introduce the Lumina-T2X family - a series of Flow-based Large Diffusion Transformers (Flag-DiT) equipped with zero-initialized attention, as a unified framework designed to transform noise into images, videos, multi-view 3D objects, and audio clips conditioned on text instructions. By tokenizing the latent spatial-temporal space and incorporating learnable placeholders such as [nextline] and [nextframe] tokens, Lumina-T2X seamlessly unifies the representations of different modalities across various spatial-temporal resolutions. This unified approach enables training within a single framework for different modalities and allows for flexible generation of multimodal data at any resolution, aspect ratio, and length during inference. Advanced techniques like RoPE, RMSNorm, and flow matching enhance the stability, flexibility, and scalability of Flag-DiT, enabling models of Lumina-T2X to scale up to 7 billion parameters and extend the context window to 128K tokens. This is particularly beneficial for creating ultra-high-definition images with our Lumina-T2I model and long 720p videos with our Lumina-T2V model. Remarkably, Lumina-T2I, powered by a 5-billion-parameter Flag-DiT, requires only 35% of the training computational costs of a 600-million-parameter naive DiT. Our further comprehensive analysis underscores Lumina-T2X's preliminary capability in resolution extrapolation, high-resolution editing, generating consistent 3D views, and synthesizing videos with seamless transitions. We expect that the open-sourcing of Lumina-T2X will further foster creativity, transparency, and diversity in the generative AI community.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024



We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
Mining Fine-Grained Image-Text Alignment for Zero-Shot Captioning via Text-Only Training
Jan 04, 2024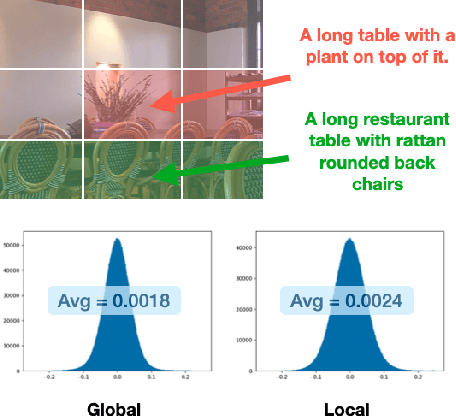
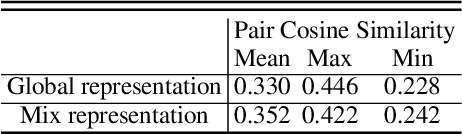
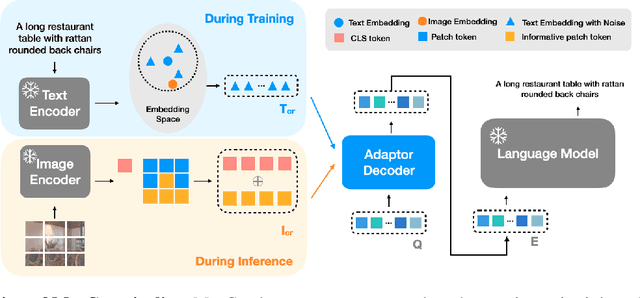
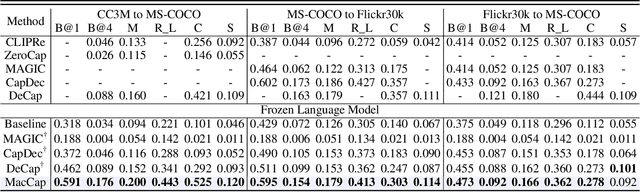
Image captioning aims at generating descriptive and meaningful textual descriptions of images, enabling a broad range of vision-language applications. Prior works have demonstrated that harnessing the power of Contrastive Image Language Pre-training (CLIP) offers a promising approach to achieving zero-shot captioning, eliminating the need for expensive caption annotations. However, the widely observed modality gap in the latent space of CLIP harms the performance of zero-shot captioning by breaking the alignment between paired image-text features. To address this issue, we conduct an analysis on the CLIP latent space which leads to two findings. Firstly, we observe that the CLIP's visual feature of image subregions can achieve closer proximity to the paired caption due to the inherent information loss in text descriptions. In addition, we show that the modality gap between a paired image-text can be empirically modeled as a zero-mean Gaussian distribution. Motivated by the findings, we propose a novel zero-shot image captioning framework with text-only training to reduce the modality gap. In particular, we introduce a subregion feature aggregation to leverage local region information, which produces a compact visual representation for matching text representation. Moreover, we incorporate a noise injection and CLIP reranking strategy to boost captioning performance. We also extend our framework to build a zero-shot VQA pipeline, demonstrating its generality. Through extensive experiments on common captioning and VQA datasets such as MSCOCO, Flickr30k and VQAV2, we show that our method achieves remarkable performance improvements. Code is available at https://github.com/Artanic30/MacCap.
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023


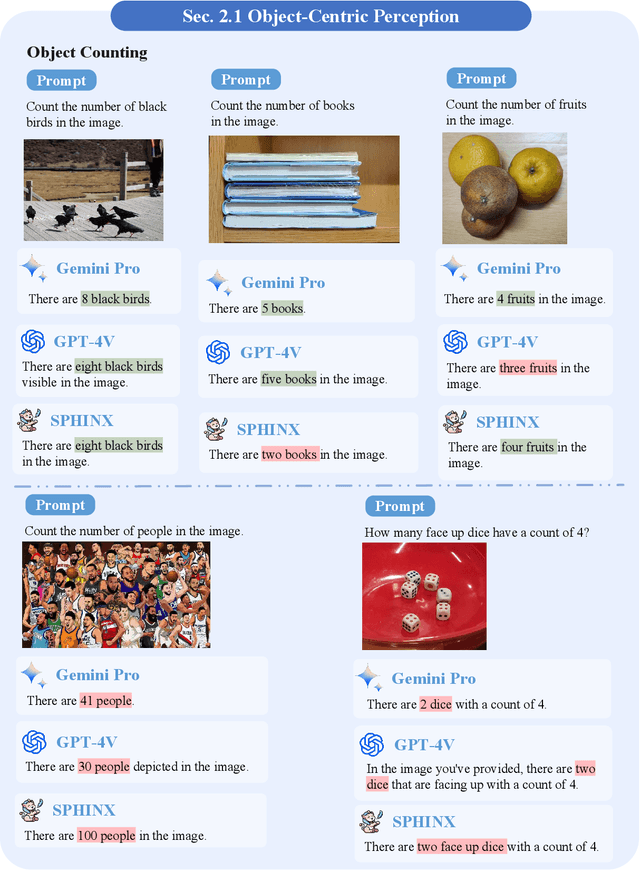
The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
Nov 13, 2023
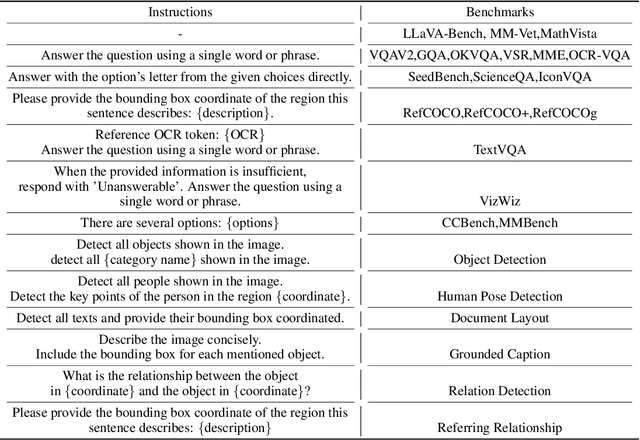

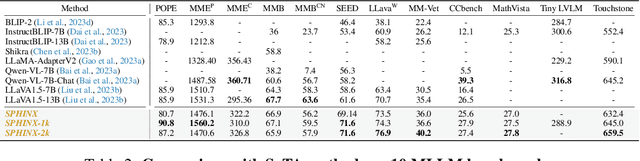
We present SPHINX, a versatile multi-modal large language model (MLLM) with a joint mixing of model weights, tuning tasks, and visual embeddings. First, for stronger vision-language alignment, we unfreeze the large language model (LLM) during pre-training, and introduce a weight mix strategy between LLMs trained by real-world and synthetic data. By directly integrating the weights from two domains, the mixed LLM can efficiently incorporate diverse semantics with favorable robustness. Then, to enable multi-purpose capabilities, we mix a variety of tasks for joint visual instruction tuning, and design task-specific instructions to avoid inter-task conflict. In addition to the basic visual question answering, we include more challenging tasks such as region-level understanding, caption grounding, document layout detection, and human pose estimation, contributing to mutual enhancement over different scenarios. Additionally, we propose to extract comprehensive visual embeddings from various network architectures, pre-training paradigms, and information granularity, providing language models with more robust image representations. Based on our proposed joint mixing, SPHINX exhibits superior multi-modal understanding capabilities on a wide range of applications. On top of this, we further propose an efficient strategy aiming to better capture fine-grained appearances of high-resolution images. With a mixing of different scales and high-resolution sub-images, SPHINX attains exceptional visual parsing and reasoning performance on existing evaluation benchmarks. We hope our work may cast a light on the exploration of joint mixing in future MLLM research. Code is released at https://github.com/Alpha-VLLM/LLaMA2-Accessory.
HOICLIP: Efficient Knowledge Transfer for HOI Detection with Vision-Language Models
Mar 29, 2023



Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions. Recently, Contrastive Language-Image Pre-training (CLIP) has shown great potential in providing interaction prior for HOI detectors via knowledge distillation. However, such approaches often rely on large-scale training data and suffer from inferior performance under few/zero-shot scenarios. In this paper, we propose a novel HOI detection framework that efficiently extracts prior knowledge from CLIP and achieves better generalization. In detail, we first introduce a novel interaction decoder to extract informative regions in the visual feature map of CLIP via a cross-attention mechanism, which is then fused with the detection backbone by a knowledge integration block for more accurate human-object pair detection. In addition, prior knowledge in CLIP text encoder is leveraged to generate a classifier by embedding HOI descriptions. To distinguish fine-grained interactions, we build a verb classifier from training data via visual semantic arithmetic and a lightweight verb representation adapter. Furthermore, we propose a training-free enhancement to exploit global HOI predictions from CLIP. Extensive experiments demonstrate that our method outperforms the state of the art by a large margin on various settings, e.g. +4.04 mAP on HICO-Det. The source code is available in https://github.com/Artanic30/HOICLIP.
CALIP: Zero-Shot Enhancement of CLIP with Parameter-free Attention
Sep 28, 2022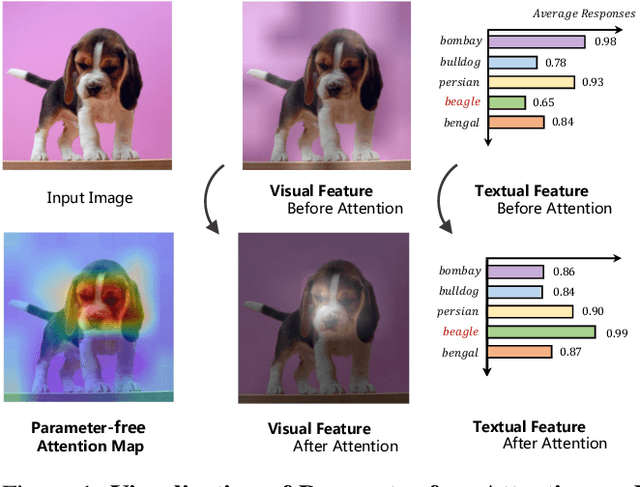
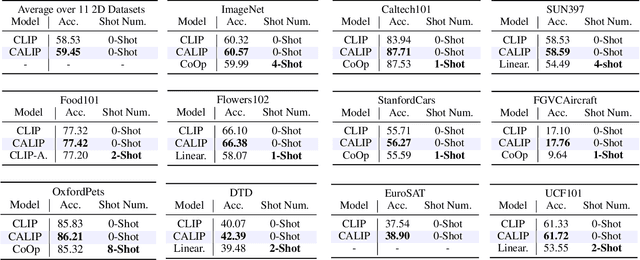
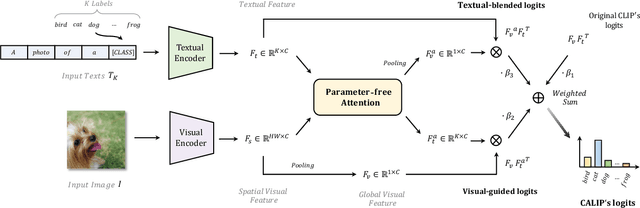

Contrastive Language-Image Pre-training (CLIP) has been shown to learn visual representations with great transferability, which achieves promising accuracy for zero-shot classification. To further improve its downstream performance, existing works propose additional learnable modules upon CLIP and fine-tune them by few-shot training sets. However, the resulting extra training cost and data requirement severely hinder the efficiency for model deployment and knowledge transfer. In this paper, we introduce a free-lunch enhancement method, CALIP, to boost CLIP's zero-shot performance via a parameter-free Attention module. Specifically, we guide visual and textual representations to interact with each other and explore cross-modal informative features via attention. As the pre-training has largely reduced the embedding distances between two modalities, we discard all learnable parameters in the attention and bidirectionally update the multi-modal features, enabling the whole process to be parameter-free and training-free. In this way, the images are blended with textual-aware signals and the text representations become visual-guided for better adaptive zero-shot alignment. We evaluate CALIP on various benchmarks of 14 datasets for both 2D image and 3D point cloud few-shot classification, showing consistent zero-shot performance improvement over CLIP. Based on that, we further insert a small number of linear layers in CALIP's attention module and verify our robustness under the few-shot settings, which also achieves leading performance compared to existing methods. Those extensive experiments demonstrate the superiority of our approach for efficient enhancement of CLIP.