 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Paper and Code



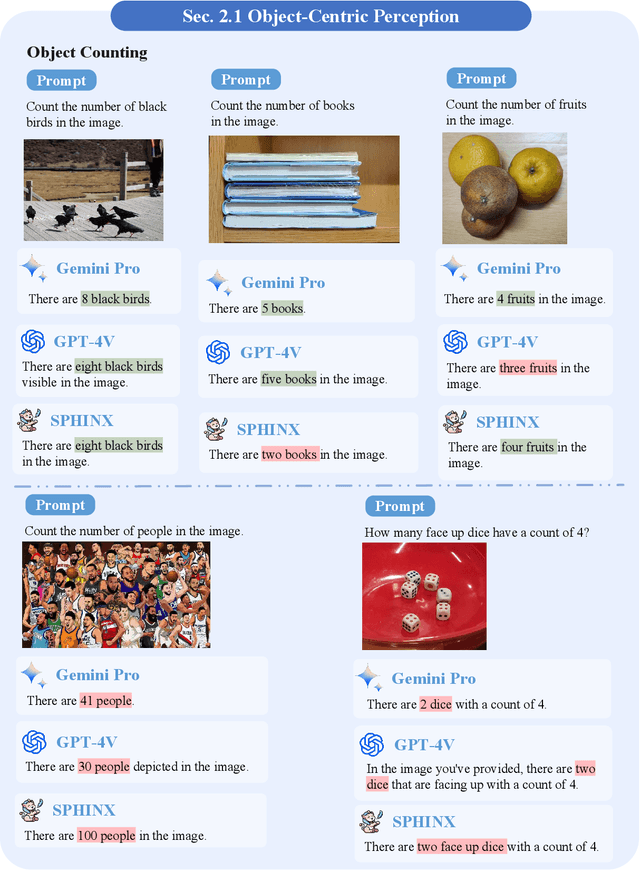
The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.