 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Streaming Video Instruction Tuning
Dec 24, 2025



We present Streamo, a real-time streaming video LLM that serves as a general-purpose interactive assistant. Unlike existing online video models that focus narrowly on question answering or captioning, Streamo performs a broad spectrum of streaming video tasks, including real-time narration, action understanding, event captioning, temporal event grounding, and time-sensitive question answering. To develop such versatility, we construct Streamo-Instruct-465K, a large-scale instruction-following dataset tailored for streaming video understanding. The dataset covers diverse temporal contexts and multi-task supervision, enabling unified training across heterogeneous streaming tasks. After training end-to-end on the instruction-following dataset through a streamlined pipeline, Streamo exhibits strong temporal reasoning, responsive interaction, and broad generalization across a variety of streaming benchmarks. Extensive experiments show that Streamo bridges the gap between offline video perception models and real-time multimodal assistants, making a step toward unified, intelligent video understanding in continuous video streams.
Zooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
May 28, 2025Multi-modal Large Language Models (MLLMs) excel at single-image tasks but struggle with multi-image understanding due to cross-modal misalignment, leading to hallucinations (context omission, conflation, and misinterpretation). Existing methods using Direct Preference Optimization (DPO) constrain optimization to a solitary image reference within the input sequence, neglecting holistic context modeling. We propose Context-to-Cue Direct Preference Optimization (CcDPO), a multi-level preference optimization framework that enhances per-image perception in multi-image settings by zooming into visual clues -- from sequential context to local details. It features: (i) Context-Level Optimization : Re-evaluates cognitive biases underlying MLLMs' multi-image context comprehension and integrates a spectrum of low-cost global sequence preferences for bias mitigation. (ii) Needle-Level Optimization : Directs attention to fine-grained visual details through region-targeted visual prompts and multimodal preference supervision. To support scalable optimization, we also construct MultiScope-42k, an automatically generated dataset with high-quality multi-level preference pairs. Experiments show that CcDPO significantly reduces hallucinations and yields consistent performance gains across general single- and multi-image tasks.
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large Models
Jun 14, 2024The swift progress of Multi-modal Large Models (MLLMs) has showcased their impressive ability to tackle tasks blending vision and language. Yet, most current models and benchmarks cater to scenarios with a narrow scope of visual and textual contexts. These models often fall short when faced with complex comprehension tasks, which involve navigating through a plethora of irrelevant and potentially misleading information in both text and image forms. To bridge this gap, we introduce a new, more demanding task known as Interleaved Image-Text Comprehension (IITC). This task challenges models to discern and disregard superfluous elements in both images and text to accurately answer questions and to follow intricate instructions to pinpoint the relevant image. In support of this task, we further craft a new VEGA dataset, tailored for the IITC task on scientific content, and devised a subtask, Image-Text Association (ITA), to refine image-text correlation skills. Our evaluation of four leading closed-source models, as well as various open-source models using VEGA, underscores the rigorous nature of IITC. Even the most advanced models, such as Gemini-1.5-pro and GPT4V, only achieved modest success. By employing a multi-task, multi-scale post-training strategy, we have set a robust baseline for MLLMs on the IITC task, attaining an $85.8\%$ accuracy rate in image association and a $0.508$ Rouge score. These results validate the effectiveness of our dataset in improving MLLMs capabilities for nuanced image-text comprehension.
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
May 31, 2024



In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video. Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data. Project Page: https://video-mme.github.io
Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
Apr 24, 2024With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales. Project Page: https://ggg0919.github.io/cantor/ .
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023


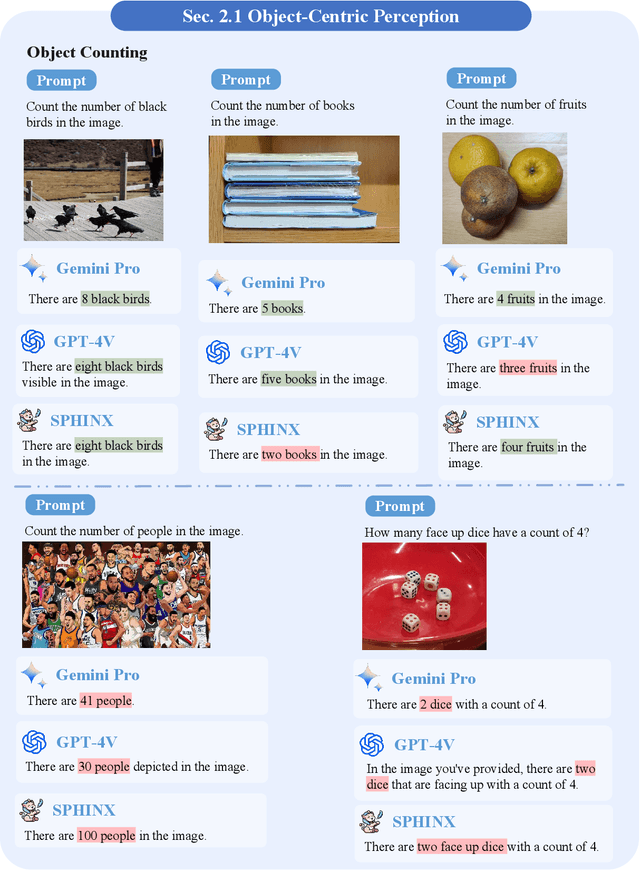
The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
Aligning and Prompting Everything All at Once for Universal Visual Perception
Dec 04, 2023Vision foundation models have been explored recently to build general-purpose vision systems. However, predominant paradigms, driven by casting instance-level tasks as an object-word alignment, bring heavy cross-modality interaction, which is not effective in prompting object detection and visual grounding. Another line of work that focuses on pixel-level tasks often encounters a large annotation gap of things and stuff, and suffers from mutual interference between foreground-object and background-class segmentation. In stark contrast to the prevailing methods, we present APE, a universal visual perception model for aligning and prompting everything all at once in an image to perform diverse tasks, i.e., detection, segmentation, and grounding, as an instance-level sentence-object matching paradigm. Specifically, APE advances the convergence of detection and grounding by reformulating language-guided grounding as open-vocabulary detection, which efficiently scales up model prompting to thousands of category vocabularies and region descriptions while maintaining the effectiveness of cross-modality fusion. To bridge the granularity gap of different pixel-level tasks, APE equalizes semantic and panoptic segmentation to proxy instance learning by considering any isolated regions as individual instances. APE aligns vision and language representation on broad data with natural and challenging characteristics all at once without task-specific fine-tuning. The extensive experiments on over 160 datasets demonstrate that, with only one-suit of weights, APE outperforms (or is on par with) the state-of-the-art models, proving that an effective yet universal perception for anything aligning and prompting is indeed feasible. Codes and trained models are released at https://github.com/shenyunhang/APE.